 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal-Tune: Mining Causal Factors from Vision Foundation Models for Domain Generalized Semantic Segmentation
Dec 18, 2025Fine-tuning Vision Foundation Models (VFMs) with a small number of parameters has shown remarkable performance in Domain Generalized Semantic Segmentation (DGSS). Most existing works either train lightweight adapters or refine intermediate features to achieve better generalization on unseen domains. However, they both overlook the fact that long-term pre-trained VFMs often exhibit artifacts, which hinder the utilization of valuable representations and ultimately degrade DGSS performance. Inspired by causal mechanisms, we observe that these artifacts are associated with non-causal factors, which usually reside in the low- and high-frequency components of the VFM spectrum. In this paper, we explicitly examine the causal and non-causal factors of features within VFMs for DGSS, and propose a simple yet effective method to identify and disentangle them, enabling more robust domain generalization. Specifically, we propose Causal-Tune, a novel fine-tuning strategy designed to extract causal factors and suppress non-causal ones from the features of VFMs. First, we extract the frequency spectrum of features from each layer using the Discrete Cosine Transform (DCT). A Gaussian band-pass filter is then applied to separate the spectrum into causal and non-causal components. To further refine the causal components, we introduce a set of causal-aware learnable tokens that operate in the frequency domain, while the non-causal components are discarded. Finally, refined features are transformed back into the spatial domain via inverse DCT and passed to the next layer. Extensive experiments conducted on various cross-domain tasks demonstrate the effectiveness of Causal-Tune. In particular, our method achieves superior performance under adverse weather conditions, improving +4.8% mIoU over the baseline in snow conditions.
Canonical Space Representation for 4D Panoptic Segmentation of Articulated Objects
Nov 07, 2025Articulated object perception presents significant challenges in computer vision, particularly because most existing methods ignore temporal dynamics despite the inherently dynamic nature of such objects. The use of 4D temporal data has not been thoroughly explored in articulated object perception and remains unexamined for panoptic segmentation. The lack of a benchmark dataset further hurt this field. To this end, we introduce Artic4D as a new dataset derived from PartNet Mobility and augmented with synthetic sensor data, featuring 4D panoptic annotations and articulation parameters. Building on this dataset, we propose CanonSeg4D, a novel 4D panoptic segmentation framework. This approach explicitly estimates per-frame offsets mapping observed object parts to a learned canonical space, thereby enhancing part-level segmentation. The framework employs this canonical representation to achieve consistent alignment of object parts across sequential frames. Comprehensive experiments on Artic4D demonstrate that the proposed CanonSeg4D outperforms state of the art approaches in panoptic segmentation accuracy in more complex scenarios. These findings highlight the effectiveness of temporal modeling and canonical alignment in dynamic object understanding, and pave the way for future advances in 4D articulated object perception.
An h-space Based Adversarial Attack for Protection Against Few-shot Personalization
Jul 23, 2025The versatility of diffusion models in generating customized images from few samples raises significant privacy concerns, particularly regarding unauthorized modifications of private content. This concerning issue has renewed the efforts in developing protection mechanisms based on adversarial attacks, which generate effective perturbations to poison diffusion models. Our work is motivated by the observation that these models exhibit a high degree of abstraction within their semantic latent space (`h-space'), which encodes critical high-level features for generating coherent and meaningful content. In this paper, we propose a novel anti-customization approach, called HAAD (h-space based Adversarial Attack for Diffusion models), that leverages adversarial attacks to craft perturbations based on the h-space that can efficiently degrade the image generation process. Building upon HAAD, we further introduce a more efficient variant, HAAD-KV, that constructs perturbations solely based on the KV parameters of the h-space. This strategy offers a stronger protection, that is computationally less expensive. Despite their simplicity, our methods outperform state-of-the-art adversarial attacks, highlighting their effectiveness.
Aesthetics Without Semantics
May 08, 2025While it is easy for human observers to judge an image as beautiful or ugly, aesthetic decisions result from a combination of entangled perceptual and cognitive (semantic) factors, making the understanding of aesthetic judgements particularly challenging from a scientific point of view. Furthermore, our research shows a prevailing bias in current databases, which include mostly beautiful images, further complicating the study and prediction of aesthetic responses. We address these limitations by creating a database of images with minimal semantic content and devising, and next exploiting, a method to generate images on the ugly side of aesthetic valuations. The resulting Minimum Semantic Content (MSC) database consists of a large and balanced collection of 10,426 images, each evaluated by 100 observers. We next use established image metrics to demonstrate how augmenting an image set biased towards beautiful images with ugly images can modify, or even invert, an observed relationship between image features and aesthetics valuation. Taken together, our study reveals that works in empirical aesthetics attempting to link image content and aesthetic judgements may magnify, underestimate, or simply miss interesting effects due to a limitation of the range of aesthetic values they consider.
Leveraging Semantic Attribute Binding for Free-Lunch Color Control in Diffusion Models
Mar 12, 2025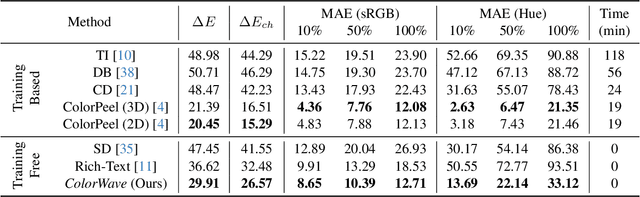
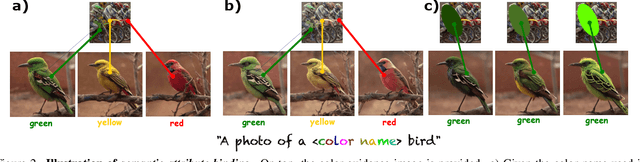
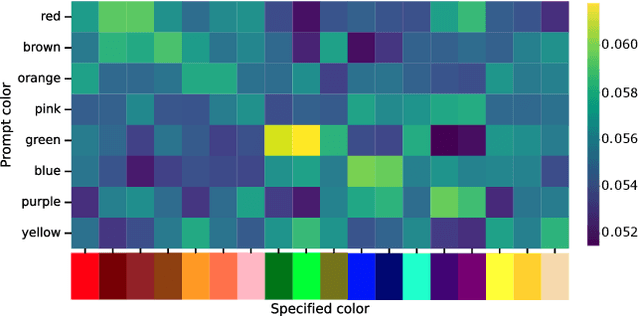
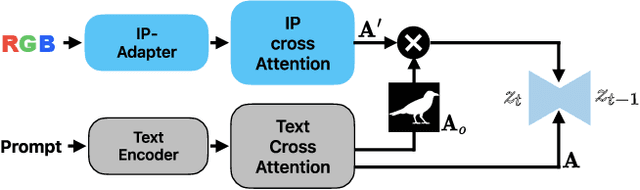
Recent advances in text-to-image (T2I) diffusion models have enabled remarkable control over various attributes, yet precise color specification remains a fundamental challenge. Existing approaches, such as ColorPeel, rely on model personalization, requiring additional optimization and limiting flexibility in specifying arbitrary colors. In this work, we introduce ColorWave, a novel training-free approach that achieves exact RGB-level color control in diffusion models without fine-tuning. By systematically analyzing the cross-attention mechanisms within IP-Adapter, we uncover an implicit binding between textual color descriptors and reference image features. Leveraging this insight, our method rewires these bindings to enforce precise color attribution while preserving the generative capabilities of pretrained models. Our approach maintains generation quality and diversity, outperforming prior methods in accuracy and applicability across diverse object categories. Through extensive evaluations, we demonstrate that ColorWave establishes a new paradigm for structured, color-consistent diffusion-based image synthesis.
Multi-label out-of-distribution detection via evidential learning
Feb 25, 2025



A crucial requirement for machine learning algorithms is not only to perform well, but also to show robustness and adaptability when encountering novel scenarios. One way to achieve these characteristics is to endow the deep learning models with the ability to detect out-of-distribution (OOD) data, i.e. data that belong to distributions different from the one used during their training. It is even a more complicated situation, when these data usually are multi-label. In this paper, we propose an approach based on evidential deep learning in order to meet these challenges applied to visual recognition problems. More concretely, we designed a CNN architecture that uses a Beta Evidential Neural Network to compute both the likelihood and the predictive uncertainty of the samples. Based on these results, we propose afterwards two new uncertainty-based scores for OOD data detection: (i) OOD - score Max, based on the maximum evidence; and (ii) OOD score - Sum, which considers the evidence from all outputs. Extensive experiments have been carried out to validate the proposed approach using three widely-used datasets: PASCAL-VOC, MS-COCO and NUS-WIDE, demonstrating its outperformance over several State-of-the-Art methods.
Privacy Protection in Personalized Diffusion Models via Targeted Cross-Attention Adversarial Attack
Nov 25, 2024



The growing demand for customized visual content has led to the rise of personalized text-to-image (T2I) diffusion models. Despite their remarkable potential, they pose significant privacy risk when misused for malicious purposes. In this paper, we propose a novel and efficient adversarial attack method, Concept Protection by Selective Attention Manipulation (CoPSAM) which targets only the cross-attention layers of a T2I diffusion model. For this purpose, we carefully construct an imperceptible noise to be added to clean samples to get their adversarial counterparts. This is obtained during the fine-tuning process by maximizing the discrepancy between the corresponding cross-attention maps of the user-specific token and the class-specific token, respectively. Experimental validation on a subset of CelebA-HQ face images dataset demonstrates that our approach outperforms existing methods. Besides this, our method presents two important advantages derived from the qualitative evaluation: (i) we obtain better protection results for lower noise levels than our competitors; and (ii) we protect the content from unauthorized use thereby protecting the individual's identity from potential misuse.
Multi-Class Textual-Inversion Secretly Yields a Semantic-Agnostic Classifier
Oct 29, 2024
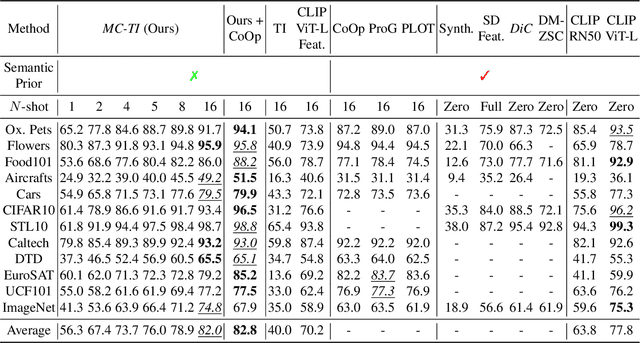
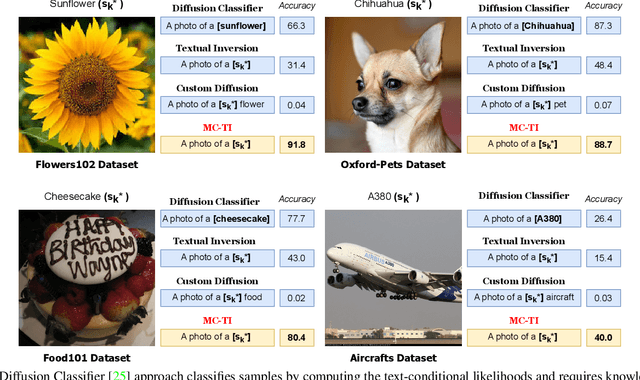
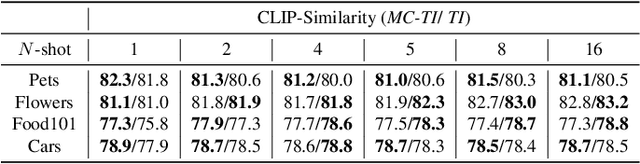
With the advent of large pre-trained vision-language models such as CLIP, prompt learning methods aim to enhance the transferability of the CLIP model. They learn the prompt given few samples from the downstream task given the specific class names as prior knowledge, which we term as semantic-aware classification. However, in many realistic scenarios, we only have access to few samples and knowledge of the class names (e.g., when considering instances of classes). This challenging scenario represents the semantic-agnostic discriminative case. Text-to-Image (T2I) personalization methods aim to adapt T2I models to unseen concepts by learning new tokens and endowing these tokens with the capability of generating the learned concepts. These methods do not require knowledge of class names as a semantic-aware prior. Therefore, in this paper, we first explore Textual Inversion and reveal that the new concept tokens possess both generation and classification capabilities by regarding each category as a single concept. However, learning classifiers from single-concept textual inversion is limited since the learned tokens are suboptimal for the discriminative tasks. To mitigate this issue, we propose Multi-Class textual inversion, which includes a discriminative regularization term for the token updating process. Using this technique, our method MC-TI achieves stronger Semantic-Agnostic Classification while preserving the generation capability of these modifier tokens given only few samples per category. In the experiments, we extensively evaluate MC-TI on 12 datasets covering various scenarios, which demonstrates that MC-TI achieves superior results in terms of both classification and generation outcomes.
Assessing Open-world Forgetting in Generative Image Model Customization
Oct 18, 2024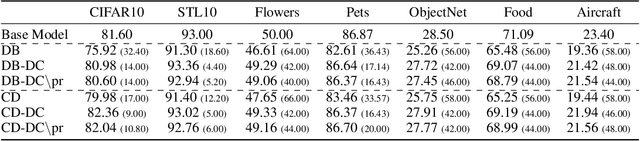
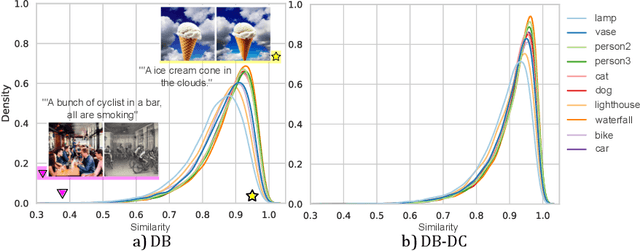


Recent advances in diffusion models have significantly enhanced image generation capabilities. However, customizing these models with new classes often leads to unintended consequences that compromise their reliability. We introduce the concept of open-world forgetting to emphasize the vast scope of these unintended alterations, contrasting it with the well-studied closed-world forgetting, which is measurable by evaluating performance on a limited set of classes or skills. Our research presents the first comprehensive investigation into open-world forgetting in diffusion models, focusing on semantic and appearance drift of representations. We utilize zero-shot classification to analyze semantic drift, revealing that even minor model adaptations lead to unpredictable shifts affecting areas far beyond newly introduced concepts, with dramatic drops in zero-shot classification of up to 60%. Additionally, we observe significant changes in texture and color of generated content when analyzing appearance drift. To address these issues, we propose a mitigation strategy based on functional regularization, designed to preserve original capabilities while accommodating new concepts. Our study aims to raise awareness of unintended changes due to model customization and advocates for the analysis of open-world forgetting in future research on model customization and finetuning methods. Furthermore, we provide insights for developing more robust adaptation methodologies.
The Expanding Scope of the Stability Gap: Unveiling its Presence in Joint Incremental Learning of Homogeneous Tasks
Jun 07, 2024



Recent research identified a temporary performance drop on previously learned tasks when transitioning to a new one. This drop is called the stability gap and has great consequences for continual learning: it complicates the direct employment of continually learning since the worse-case performance at task-boundaries is dramatic, it limits its potential as an energy-efficient training paradigm, and finally, the stability drop could result in a reduced final performance of the algorithm. In this paper, we show that the stability gap also occurs when applying joint incremental training of homogeneous tasks. In this scenario, the learner continues training on the same data distribution and has access to all data from previous tasks. In addition, we show that in this scenario, there exists a low-loss linear path to the next minima, but that SGD optimization does not choose this path. We perform further analysis including a finer batch-wise analysis which could provide insights towards potential solution directions.