 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn h-space Based Adversarial Attack for Protection Against Few-shot Personalization
Jul 23, 2025The versatility of diffusion models in generating customized images from few samples raises significant privacy concerns, particularly regarding unauthorized modifications of private content. This concerning issue has renewed the efforts in developing protection mechanisms based on adversarial attacks, which generate effective perturbations to poison diffusion models. Our work is motivated by the observation that these models exhibit a high degree of abstraction within their semantic latent space (`h-space'), which encodes critical high-level features for generating coherent and meaningful content. In this paper, we propose a novel anti-customization approach, called HAAD (h-space based Adversarial Attack for Diffusion models), that leverages adversarial attacks to craft perturbations based on the h-space that can efficiently degrade the image generation process. Building upon HAAD, we further introduce a more efficient variant, HAAD-KV, that constructs perturbations solely based on the KV parameters of the h-space. This strategy offers a stronger protection, that is computationally less expensive. Despite their simplicity, our methods outperform state-of-the-art adversarial attacks, highlighting their effectiveness.
Privacy Protection in Personalized Diffusion Models via Targeted Cross-Attention Adversarial Attack
Nov 25, 2024



The growing demand for customized visual content has led to the rise of personalized text-to-image (T2I) diffusion models. Despite their remarkable potential, they pose significant privacy risk when misused for malicious purposes. In this paper, we propose a novel and efficient adversarial attack method, Concept Protection by Selective Attention Manipulation (CoPSAM) which targets only the cross-attention layers of a T2I diffusion model. For this purpose, we carefully construct an imperceptible noise to be added to clean samples to get their adversarial counterparts. This is obtained during the fine-tuning process by maximizing the discrepancy between the corresponding cross-attention maps of the user-specific token and the class-specific token, respectively. Experimental validation on a subset of CelebA-HQ face images dataset demonstrates that our approach outperforms existing methods. Besides this, our method presents two important advantages derived from the qualitative evaluation: (i) we obtain better protection results for lower noise levels than our competitors; and (ii) we protect the content from unauthorized use thereby protecting the individual's identity from potential misuse.
The Expanding Scope of the Stability Gap: Unveiling its Presence in Joint Incremental Learning of Homogeneous Tasks
Jun 07, 2024



Recent research identified a temporary performance drop on previously learned tasks when transitioning to a new one. This drop is called the stability gap and has great consequences for continual learning: it complicates the direct employment of continually learning since the worse-case performance at task-boundaries is dramatic, it limits its potential as an energy-efficient training paradigm, and finally, the stability drop could result in a reduced final performance of the algorithm. In this paper, we show that the stability gap also occurs when applying joint incremental training of homogeneous tasks. In this scenario, the learner continues training on the same data distribution and has access to all data from previous tasks. In addition, we show that in this scenario, there exists a low-loss linear path to the next minima, but that SGD optimization does not choose this path. We perform further analysis including a finer batch-wise analysis which could provide insights towards potential solution directions.
Resurrecting Old Classes with New Data for Exemplar-Free Continual Learning
May 29, 2024



Continual learning methods are known to suffer from catastrophic forgetting, a phenomenon that is particularly hard to counter for methods that do not store exemplars of previous tasks. Therefore, to reduce potential drift in the feature extractor, existing exemplar-free methods are typically evaluated in settings where the first task is significantly larger than subsequent tasks. Their performance drops drastically in more challenging settings starting with a smaller first task. To address this problem of feature drift estimation for exemplar-free methods, we propose to adversarially perturb the current samples such that their embeddings are close to the old class prototypes in the old model embedding space. We then estimate the drift in the embedding space from the old to the new model using the perturbed images and compensate the prototypes accordingly. We exploit the fact that adversarial samples are transferable from the old to the new feature space in a continual learning setting. The generation of these images is simple and computationally cheap. We demonstrate in our experiments that the proposed approach better tracks the movement of prototypes in embedding space and outperforms existing methods on several standard continual learning benchmarks as well as on fine-grained datasets. Code is available at https://github.com/dipamgoswami/ADC.
Rethinking Robustness of Model Attributions
Dec 16, 2023


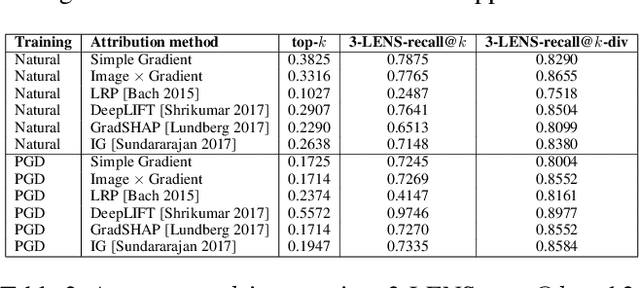
For machine learning models to be reliable and trustworthy, their decisions must be interpretable. As these models find increasing use in safety-critical applications, it is important that not just the model predictions but also their explanations (as feature attributions) be robust to small human-imperceptible input perturbations. Recent works have shown that many attribution methods are fragile and have proposed improvements in either these methods or the model training. We observe two main causes for fragile attributions: first, the existing metrics of robustness (e.g., top-k intersection) over-penalize even reasonable local shifts in attribution, thereby making random perturbations to appear as a strong attack, and second, the attribution can be concentrated in a small region even when there are multiple important parts in an image. To rectify this, we propose simple ways to strengthen existing metrics and attribution methods that incorporate locality of pixels in robustness metrics and diversity of pixel locations in attributions. Towards the role of model training in attributional robustness, we empirically observe that adversarially trained models have more robust attributions on smaller datasets, however, this advantage disappears in larger datasets. Code is available at https://github.com/ksandeshk/LENS.
On the Robustness of Explanations of Deep Neural Network Models: A Survey
Nov 09, 2022



Explainability has been widely stated as a cornerstone of the responsible and trustworthy use of machine learning models. With the ubiquitous use of Deep Neural Network (DNN) models expanding to risk-sensitive and safety-critical domains, many methods have been proposed to explain the decisions of these models. Recent years have also seen concerted efforts that have shown how such explanations can be distorted (attacked) by minor input perturbations. While there have been many surveys that review explainability methods themselves, there has been no effort hitherto to assimilate the different methods and metrics proposed to study the robustness of explanations of DNN models. In this work, we present a comprehensive survey of methods that study, understand, attack, and defend explanations of DNN models. We also present a detailed review of different metrics used to evaluate explanation methods, as well as describe attributional attack and defense methods. We conclude with lessons and take-aways for the community towards ensuring robust explanations of DNN model predictions.
How do SGD hyperparameters in natural training affect adversarial robustness?
Jun 20, 2020
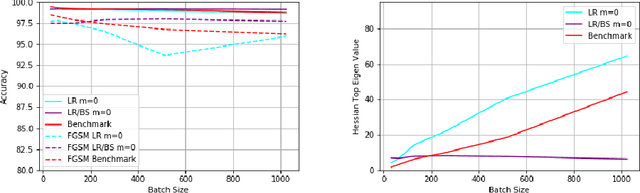
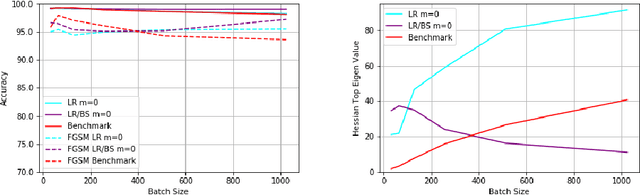
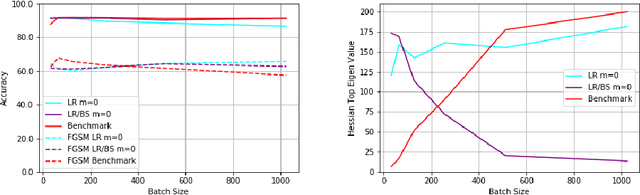
Learning rate, batch size and momentum are three important hyperparameters in the SGD algorithm. It is known from the work of Jastrzebski et al. arXiv:1711.04623 that large batch size training of neural networks yields models which do not generalize well. Yao et al. arXiv:1802.08241 observe that large batch training yields models that have poor adversarial robustness. In the same paper, the authors train models with different batch sizes and compute the eigenvalues of the Hessian of loss function. They observe that as the batch size increases, the dominant eigenvalues of the Hessian become larger. They also show that both adversarial training and small-batch training leads to a drop in the dominant eigenvalues of the Hessian or lowering its spectrum. They combine adversarial training and second order information to come up with a new large-batch training algorithm and obtain robust models with good generalization. In this paper, we empirically observe the effect of the SGD hyperparameters on the accuracy and adversarial robustness of networks trained with unperturbed samples. Jastrzebski et al. considered training models with a fixed learning rate to batch size ratio. They observed that higher the ratio, better is the generalization. We observe that networks trained with constant learning rate to batch size ratio, as proposed in Jastrzebski et al., yield models which generalize well and also have almost constant adversarial robustness, independent of the batch size. We observe that momentum is more effective with varying batch sizes and a fixed learning rate than with constant learning rate to batch size ratio based SGD training.
On Universalized Adversarial and Invariant Perturbations
Jun 08, 2020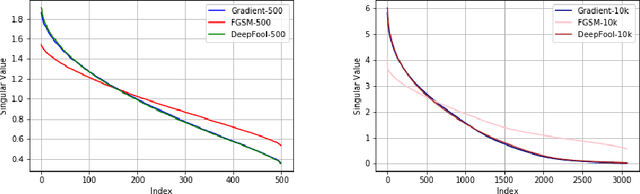

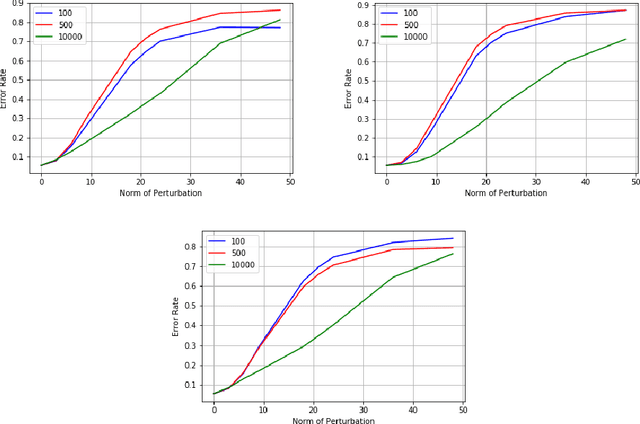
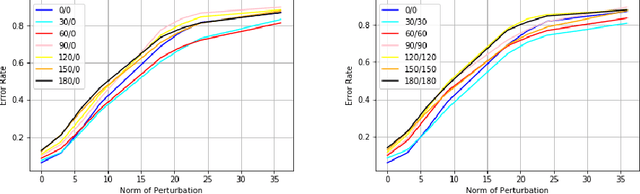
Convolutional neural networks or standard CNNs (StdCNNs) are translation-equivariant models that achieve translation invariance when trained on data augmented with sufficient translations. Recent work on equivariant models for a given group of transformations (e.g., rotations) has lead to group-equivariant convolutional neural networks (GCNNs). GCNNs trained on data augmented with sufficient rotations achieve rotation invariance. Recent work by authors arXiv:2002.11318 studies a trade-off between invariance and robustness to adversarial attacks. In another related work arXiv:2005.08632, given any model and any input-dependent attack that satisfies a certain spectral property, the authors propose a universalization technique called SVD-Universal to produce a universal adversarial perturbation by looking at very few test examples. In this paper, we study the effectiveness of SVD-Universal on GCNNs as they gain rotation invariance through higher degree of training augmentation. We empirically observe that as GCNNs gain rotation invariance through training augmented with larger rotations, the fooling rate of SVD-Universal gets better. To understand this phenomenon, we introduce universal invariant directions and study their relation to the universal adversarial direction produced by SVD-Universal.
Universalization of any adversarial attack using very few test examples
May 18, 2020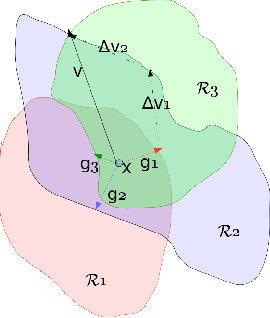
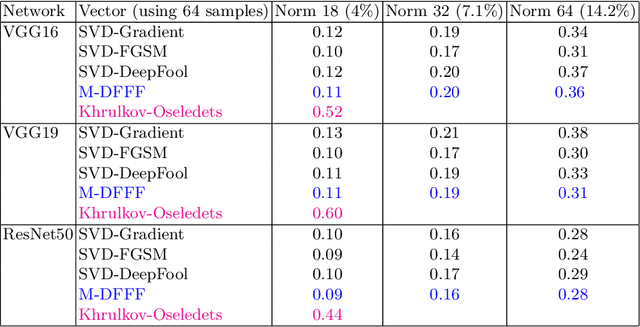

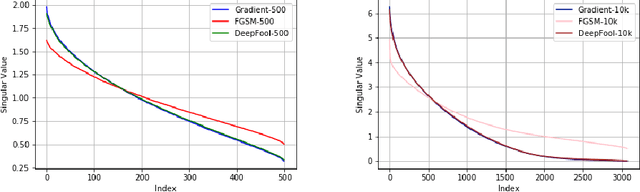
Deep learning models are known to be vulnerable not only to input-dependent adversarial attacks but also to input-agnostic or universal adversarial attacks. Dezfooli et al. \cite{Dezfooli17,Dezfooli17anal} construct universal adversarial attack on a given model by looking at a large number of training data points and the geometry of the decision boundary near them. Subsequent work \cite{Khrulkov18} constructs universal attack by looking only at test examples and intermediate layers of the given model. In this paper, we propose a simple universalization technique to take any input-dependent adversarial attack and construct a universal attack by only looking at very few adversarial test examples. We do not require details of the given model and have negligible computational overhead for universalization. We theoretically justify our universalization technique by a spectral property common to many input-dependent adversarial perturbations, e.g., gradients, Fast Gradient Sign Method (FGSM) and DeepFool. Using matrix concentration inequalities and spectral perturbation bounds, we show that the top singular vector of input-dependent adversarial directions on a small test sample gives an effective and simple universal adversarial attack. For VGG16 and VGG19 models trained on ImageNet, our simple universalization of Gradient, FGSM, and DeepFool perturbations using a test sample of 64 images gives fooling rates comparable to state-of-the-art universal attacks \cite{Dezfooli17,Khrulkov18} for reasonable norms of perturbation.
Invariance vs. Robustness of Neural Networks
Feb 26, 2020



We study the performance of neural network models on random geometric transformations and adversarial perturbations. Invariance means that the model's prediction remains unchanged when a geometric transformation is applied to an input. Adversarial robustness means that the model's prediction remains unchanged after small adversarial perturbations of an input. In this paper, we show a quantitative trade-off between rotation invariance and robustness. We empirically study the following two cases: (a) change in adversarial robustness as we improve only the invariance of equivariant models via training augmentation, (b) change in invariance as we improve only the adversarial robustness using adversarial training. We observe that the rotation invariance of equivariant models (StdCNNs and GCNNs) improves by training augmentation with progressively larger random rotations but while doing so, their adversarial robustness drops progressively, and very significantly on MNIST. We take adversarially trained LeNet and ResNet models which have good $L_\infty$ adversarial robustness on MNIST and CIFAR-10, respectively, and observe that adversarial training with progressively larger perturbations results in a progressive drop in their rotation invariance profiles. Similar to the trade-off between accuracy and robustness known in previous work, we give a theoretical justification for the invariance vs. robustness trade-off observed in our experiments.