 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Prototype Alignment and Mixing for Training-Free Few-Shot Classification
Mar 25, 2026Vision-language models (VLMs) like CLIP are trained with the objective of aligning text and image pairs. To improve CLIP-based few-shot image classification, recent works have observed that, along with text embeddings, image embeddings from the training set are an important source of information. In this work we investigate the impact of directly mixing image and text prototypes for few-shot classification and analyze this from a bias-variance perspective. We show that mixing prototypes acts like a shrinkage estimator. Although mixed prototypes improve classification performance, the image prototypes still add some noise in the form of instance-specific background or context information. In order to capture only information from the image space relevant to the given classification task, we propose projecting image prototypes onto the principal directions of the semantic text embedding space to obtain a text-aligned semantic image subspace. These text-aligned image prototypes, when mixed with text embeddings, further improve classification. However, for downstream datasets with poor cross-modal alignment in CLIP, semantic alignment might be suboptimal. We show that the image subspace can still be leveraged by modeling the anisotropy using class covariances. We demonstrate that combining a text-aligned mixed prototype classifier and an image-specific LDA classifier outperforms existing methods across few-shot classification benchmarks.
IsoCLIP: Decomposing CLIP Projectors for Efficient Intra-modal Alignment
Mar 20, 2026Vision-Language Models like CLIP are extensively used for inter-modal tasks which involve both visual and text modalities. However, when the individual modality encoders are applied to inherently intra-modal tasks like image-to-image retrieval, their performance suffers from the intra-modal misalignment. In this paper we study intra-modal misalignment in CLIP with a focus on the role of the projectors that map pre-projection image and text embeddings into the shared embedding space. By analyzing the form of the cosine similarity applied to projected features, and its interaction with the contrastive CLIP loss, we show that there is an inter-modal operator responsible for aligning the two modalities during training, and a second, intra-modal operator that only enforces intra-modal normalization but does nothing to promote intra-modal alignment. Via spectral analysis of the inter-modal operator, we identify an approximately isotropic subspace in which the two modalities are well-aligned, as well as anisotropic directions specific to each modality. We demonstrate that this aligned subspace can be directly obtained from the projector weights and that removing the anisotropic directions improves intra-modal alignment. Our experiments on intra-modal retrieval and classification benchmarks show that our training-free method reduces intra-modal misalignment, greatly lowers latency, and outperforms existing approaches across multiple pre-trained CLIP-like models. The code is publicly available at: https://github.com/simomagi/IsoCLIP.
Backdoor Vectors: a Task Arithmetic View on Backdoor Attacks and Defenses
Oct 09, 2025Model merging (MM) recently emerged as an effective method for combining large deep learning models. However, it poses significant security risks. Recent research shows that it is highly susceptible to backdoor attacks, which introduce a hidden trigger into a single fine-tuned model instance that allows the adversary to control the output of the final merged model at inference time. In this work, we propose a simple framework for understanding backdoor attacks by treating the attack itself as a task vector. $Backdoor\ Vector\ (BV)$ is calculated as the difference between the weights of a fine-tuned backdoored model and fine-tuned clean model. BVs reveal new insights into attacks understanding and a more effective framework to measure their similarity and transferability. Furthermore, we propose a novel method that enhances backdoor resilience through merging dubbed $Sparse\ Backdoor\ Vector\ (SBV)$ that combines multiple attacks into a single one. We identify the core vulnerability behind backdoor threats in MM: $inherent\ triggers$ that exploit adversarial weaknesses in the base model. To counter this, we propose $Injection\ BV\ Subtraction\ (IBVS)$ - an assumption-free defense against backdoors in MM. Our results show that SBVs surpass prior attacks and is the first method to leverage merging to improve backdoor effectiveness. At the same time, IBVS provides a lightweight, general defense that remains effective even when the backdoor threat is entirely unknown.
No Task Left Behind: Isotropic Model Merging with Common and Task-Specific Subspaces
Feb 07, 2025Model merging integrates the weights of multiple task-specific models into a single multi-task model. Despite recent interest in the problem, a significant performance gap between the combined and single-task models remains. In this paper, we investigate the key characteristics of task matrices -- weight update matrices applied to a pre-trained model -- that enable effective merging. We show that alignment between singular components of task-specific and merged matrices strongly correlates with performance improvement over the pre-trained model. Based on this, we propose an isotropic merging framework that flattens the singular value spectrum of task matrices, enhances alignment, and reduces the performance gap. Additionally, we incorporate both common and task-specific subspaces to further improve alignment and performance. Our proposed approach achieves state-of-the-art performance across multiple scenarios, including various sets of tasks and model scales. This work advances the understanding of model merging dynamics, offering an effective methodology to merge models without requiring additional training. Code is available at https://github.com/danielm1405/iso-merging .
Covariances for Free: Exploiting Mean Distributions for Federated Learning with Pre-Trained Models
Dec 18, 2024



Using pre-trained models has been found to reduce the effect of data heterogeneity and speed up federated learning algorithms. Recent works have investigated the use of first-order statistics and second-order statistics to aggregate local client data distributions at the server and achieve very high performance without any training. In this work we propose a training-free method based on an unbiased estimator of class covariance matrices. Our method, which only uses first-order statistics in the form of class means communicated by clients to the server, incurs only a fraction of the communication costs required by methods based on communicating second-order statistics. We show how these estimated class covariances can be used to initialize a linear classifier, thus exploiting the covariances without actually sharing them. When compared to state-of-the-art methods which also share only class means, our approach improves performance in the range of 4-26\% with exactly the same communication cost. Moreover, our method achieves performance competitive or superior to sharing second-order statistics with dramatically less communication overhead. Finally, using our method to initialize classifiers and then performing federated fine-tuning yields better and faster convergence. Code is available at https://github.com/dipamgoswami/FedCOF.
Task-recency bias strikes back: Adapting covariances in Exemplar-Free Class Incremental Learning
Sep 26, 2024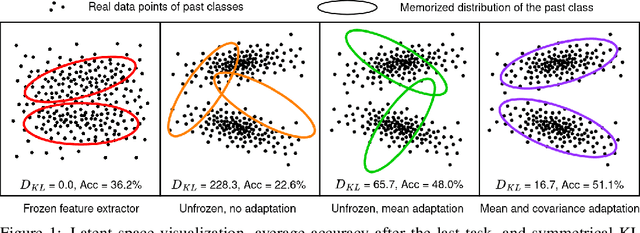
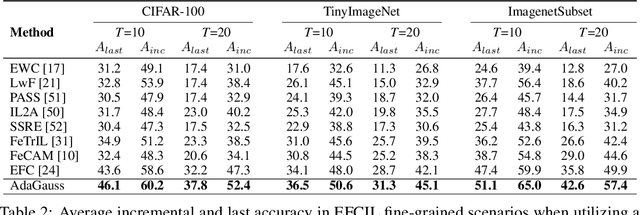
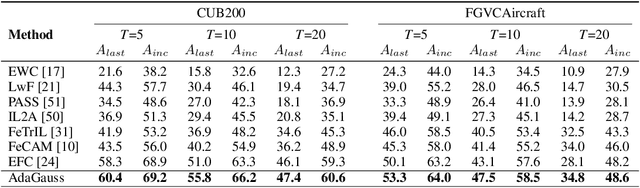

Exemplar-Free Class Incremental Learning (EFCIL) tackles the problem of training a model on a sequence of tasks without access to past data. Existing state-of-the-art methods represent classes as Gaussian distributions in the feature extractor's latent space, enabling Bayes classification or training the classifier by replaying pseudo features. However, we identify two critical issues that compromise their efficacy when the feature extractor is updated on incremental tasks. First, they do not consider that classes' covariance matrices change and must be adapted after each task. Second, they are susceptible to a task-recency bias caused by dimensionality collapse occurring during training. In this work, we propose AdaGauss -- a novel method that adapts covariance matrices from task to task and mitigates the task-recency bias owing to the additional anti-collapse loss function. AdaGauss yields state-of-the-art results on popular EFCIL benchmarks and datasets when training from scratch or starting from a pre-trained backbone. The code is available at: https://github.com/grypesc/AdaGauss.
Realistic Evaluation of Test-Time Adaptation Algorithms: Unsupervised Hyperparameter Selection
Jul 19, 2024



Test-Time Adaptation (TTA) has recently emerged as a promising strategy for tackling the problem of machine learning model robustness under distribution shifts by adapting the model during inference without access to any labels. Because of task difficulty, hyperparameters strongly influence the effectiveness of adaptation. However, the literature has provided little exploration into optimal hyperparameter selection. In this work, we tackle this problem by evaluating existing TTA methods using surrogate-based hp-selection strategies (which do not assume access to the test labels) to obtain a more realistic evaluation of their performance. We show that some of the recent state-of-the-art methods exhibit inferior performance compared to the previous algorithms when using our more realistic evaluation setup. Further, we show that forgetting is still a problem in TTA as the only method that is robust to hp-selection resets the model to the initial state at every step. We analyze different types of unsupervised selection strategies, and while they work reasonably well in most scenarios, the only strategies that work consistently well use some kind of supervision (either by a limited number of annotated test samples or by using pretraining data). Our findings underscore the need for further research with more rigorous benchmarking by explicitly stating model selection strategies, to facilitate which we open-source our code.
MagMax: Leveraging Model Merging for Seamless Continual Learning
Jul 08, 2024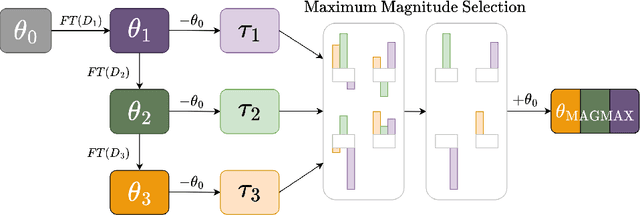
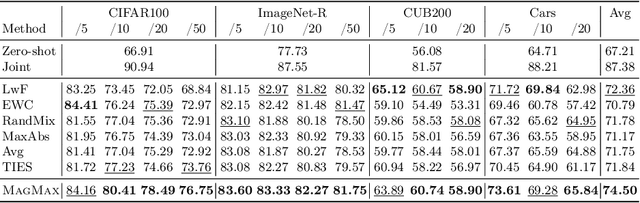
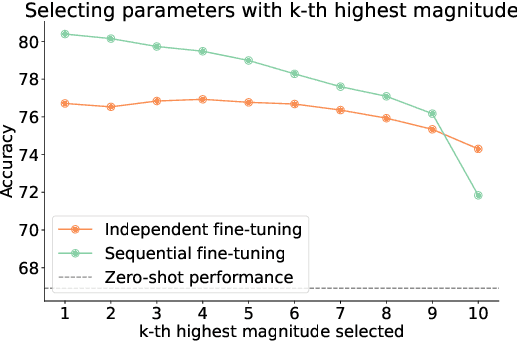
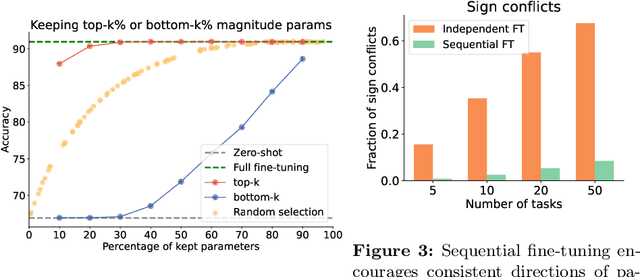
This paper introduces a continual learning approach named MagMax, which utilizes model merging to enable large pre-trained models to continuously learn from new data without forgetting previously acquired knowledge. Distinct from traditional continual learning methods that aim to reduce forgetting during task training, MagMax combines sequential fine-tuning with a maximum magnitude weight selection for effective knowledge integration across tasks. Our initial contribution is an extensive examination of model merging techniques, revealing that simple approaches like weight averaging and random weight selection surprisingly hold up well in various continual learning contexts. More importantly, we present MagMax, a novel model-merging strategy that enables continual learning of large pre-trained models for successive tasks. Our thorough evaluation demonstrates the superiority of MagMax in various scenarios, including class- and domain-incremental learning settings.
Resurrecting Old Classes with New Data for Exemplar-Free Continual Learning
May 29, 2024



Continual learning methods are known to suffer from catastrophic forgetting, a phenomenon that is particularly hard to counter for methods that do not store exemplars of previous tasks. Therefore, to reduce potential drift in the feature extractor, existing exemplar-free methods are typically evaluated in settings where the first task is significantly larger than subsequent tasks. Their performance drops drastically in more challenging settings starting with a smaller first task. To address this problem of feature drift estimation for exemplar-free methods, we propose to adversarially perturb the current samples such that their embeddings are close to the old class prototypes in the old model embedding space. We then estimate the drift in the embedding space from the old to the new model using the perturbed images and compensate the prototypes accordingly. We exploit the fact that adversarial samples are transferable from the old to the new feature space in a continual learning setting. The generation of these images is simple and computationally cheap. We demonstrate in our experiments that the proposed approach better tracks the movement of prototypes in embedding space and outperforms existing methods on several standard continual learning benchmarks as well as on fine-grained datasets. Code is available at https://github.com/dipamgoswami/ADC.
Calibrating Higher-Order Statistics for Few-Shot Class-Incremental Learning with Pre-trained Vision Transformers
Apr 09, 2024



Few-shot class-incremental learning (FSCIL) aims to adapt the model to new classes from very few data (5 samples) without forgetting the previously learned classes. Recent works in many-shot CIL (MSCIL) (using all available training data) exploited pre-trained models to reduce forgetting and achieve better plasticity. In a similar fashion, we use ViT models pre-trained on large-scale datasets for few-shot settings, which face the critical issue of low plasticity. FSCIL methods start with a many-shot first task to learn a very good feature extractor and then move to the few-shot setting from the second task onwards. While the focus of most recent studies is on how to learn the many-shot first task so that the model generalizes to all future few-shot tasks, we explore in this work how to better model the few-shot data using pre-trained models, irrespective of how the first task is trained. Inspired by recent works in MSCIL, we explore how using higher-order feature statistics can influence the classification of few-shot classes. We identify the main challenge of obtaining a good covariance matrix from few-shot data and propose to calibrate the covariance matrix for new classes based on semantic similarity to the many-shot base classes. Using the calibrated feature statistics in combination with existing methods significantly improves few-shot continual classification on several FSCIL benchmarks. Code is available at https://github.com/dipamgoswami/FSCIL-Calibration.