 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspace Optimization for Backpropagation-Free Continual Test-Time Adaptation
Mar 30, 2026We introduce PACE, a backpropagation-free continual test-time adaptation system that directly optimizes the affine parameters of normalization layers. Existing derivative-free approaches struggle to balance runtime efficiency with learning capacity, as they either restrict updates to input prompts or require continuous, resource-intensive adaptation regardless of domain stability. To address these limitations, PACE leverages the Covariance Matrix Adaptation Evolution Strategy with the Fastfood projection to optimize high-dimensional affine parameters within a low-dimensional subspace, leading to superior adaptive performance. Furthermore, we enhance the runtime efficiency by incorporating an adaptation stopping criterion and a domain-specialized vector bank to eliminate redundant computation. Our framework achieves state-of-the-art accuracy across multiple benchmarks under continual distribution shifts, reducing runtime by over 50% compared to existing backpropagation-free methods.
Realistic Evaluation of Test-Time Adaptation Algorithms: Unsupervised Hyperparameter Selection
Jul 19, 2024



Test-Time Adaptation (TTA) has recently emerged as a promising strategy for tackling the problem of machine learning model robustness under distribution shifts by adapting the model during inference without access to any labels. Because of task difficulty, hyperparameters strongly influence the effectiveness of adaptation. However, the literature has provided little exploration into optimal hyperparameter selection. In this work, we tackle this problem by evaluating existing TTA methods using surrogate-based hp-selection strategies (which do not assume access to the test labels) to obtain a more realistic evaluation of their performance. We show that some of the recent state-of-the-art methods exhibit inferior performance compared to the previous algorithms when using our more realistic evaluation setup. Further, we show that forgetting is still a problem in TTA as the only method that is robust to hp-selection resets the model to the initial state at every step. We analyze different types of unsupervised selection strategies, and while they work reasonably well in most scenarios, the only strategies that work consistently well use some kind of supervision (either by a limited number of annotated test samples or by using pretraining data). Our findings underscore the need for further research with more rigorous benchmarking by explicitly stating model selection strategies, to facilitate which we open-source our code.
Technical Report for ICCV 2023 Visual Continual Learning Challenge: Continuous Test-time Adaptation for Semantic Segmentation
Oct 20, 2023



The goal of the challenge is to develop a test-time adaptation (TTA) method, which could adapt the model to gradually changing domains in video sequences for semantic segmentation task. It is based on a synthetic driving video dataset - SHIFT. The source model is trained on images taken during daytime in clear weather. Domain changes at test-time are mainly caused by varying weather conditions and times of day. The TTA methods are evaluated in each image sequence (video) separately, meaning the model is reset to the source model state before the next sequence. Images come one by one and a prediction has to be made at the arrival of each frame. Each sequence is composed of 401 images and starts with the source domain, then gradually drifts to a different one (changing weather or time of day) until the middle of the sequence. In the second half of the sequence, the domain gradually shifts back to the source one. Ground truth data is available only for the validation split of the SHIFT dataset, in which there are only six sequences that start and end with the source domain. We conduct an analysis specifically on those sequences. Ground truth data for test split, on which the developed TTA methods are evaluated for leader board ranking, are not publicly available. The proposed solution secured a 3rd place in a challenge and received an innovation award. Contrary to the solutions that scored better, we did not use any external pretrained models or specialized data augmentations, to keep the solutions as general as possible. We have focused on analyzing the distributional shift and developing a method that could adapt to changing data dynamics and generalize across different scenarios.
AR-TTA: A Simple Method for Real-World Continual Test-Time Adaptation
Sep 18, 2023



Test-time adaptation is a promising research direction that allows the source model to adapt itself to changes in data distribution without any supervision. Yet, current methods are usually evaluated on benchmarks that are only a simplification of real-world scenarios. Hence, we propose to validate test-time adaptation methods using the recently introduced datasets for autonomous driving, namely CLAD-C and SHIFT. We observe that current test-time adaptation methods struggle to effectively handle varying degrees of domain shift, often resulting in degraded performance that falls below that of the source model. We noticed that the root of the problem lies in the inability to preserve the knowledge of the source model and adapt to dynamically changing, temporally correlated data streams. Therefore, we enhance well-established self-training framework by incorporating a small memory buffer to increase model stability and at the same time perform dynamic adaptation based on the intensity of domain shift. The proposed method, named AR-TTA, outperforms existing approaches on both synthetic and more real-world benchmarks and shows robustness across a variety of TTA scenarios.
Learning an Efficient Terrain Representation for Haptic Localization of a Legged Robot
Sep 29, 2022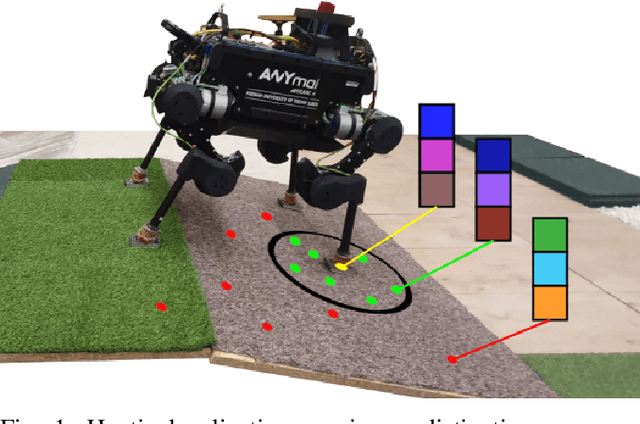



Although haptic sensing has recently been used for legged robot localization in extreme environments where a camera or LiDAR might fail, the problem of efficiently representing the haptic signatures in a learned prior map is still open. This paper introduces an approach to terrain representation for haptic localization inspired by recent trends in machine learning. It combines this approach with the proven Monte Carlo algorithm to obtain an accurate, computation-efficient, and practical method for localizing legged robots under adversarial environmental conditions. We apply the triplet loss concept to learn highly descriptive embeddings in a transformer-based neural network. As the training haptic data are not labeled, the positive and negative examples are discriminated by their geometric locations discovered while training. We demonstrate experimentally that the proposed approach outperforms by a large margin the previous solutions to haptic localization of legged robots concerning the accuracy, inference time, and the amount of data stored in the map. As far as we know, this is the first approach that completely removes the need to use a dense terrain map for accurate haptic localization, thus paving the way to practical applications.