 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderactuated dexterous robotic grasping with reconfigurable passive joints
Jan 27, 2025We introduce a novel reconfigurable passive joint (RP-joint), which has been implemented and tested on an underactuated three-finger robotic gripper. RP-joint has no actuation, but instead it is lightweight and compact. It can be easily reconfigured by applying external forces and locked to perform complex dexterous manipulation tasks, but only after tension is applied to the connected tendon. Additionally, we present an approach that allows learning dexterous grasps from single examples with underactuated grippers and automatically configures the RP-joints for dexterous manipulation. This is enhanced by integrating kinaesthetic contact optimization, which improves grasp performance even further. The proposed RP-joint gripper and grasp planner have been tested on over 370 grasps executed on 42 IKEA objects and on the YCB object dataset, achieving grasping success rates of 80% and 87%, on IKEA and YCB, respectively.
MAD-BA: 3D LiDAR Bundle Adjustment -- from Uncertainty Modelling to Structure Optimization
Jan 07, 2025



The joint optimization of sensor poses and 3D structure is fundamental for state estimation in robotics and related fields. Current LiDAR systems often prioritize pose optimization, with structure refinement either omitted or treated separately using representations like signed distance functions or neural networks. This paper introduces a framework for simultaneous optimization of sensor poses and 3D map, represented as surfels. A generalized LiDAR uncertainty model is proposed to address degraded or less reliable measurements in varying scenarios. Experimental results on public datasets demonstrate improved performance over most comparable state-of-the-art methods. The system is provided as open-source software to support further research.
How Accurate is the Positioning in VR? Using Motion Capture and Robotics to Compare Positioning Capabilities of Popular VR Headsets
Dec 09, 2024In this paper, we introduce a new methodology for assessing the positioning accuracy of virtual reality (VR) headsets, utilizing a cooperative industrial robot to simulate user head trajectories in a reproducible manner. We conduct a comprehensive evaluation of two popular VR headsets, i.e., Meta Quest 2 and Meta Quest Pro. Using head movement trajectories captured from realistic VR game scenarios with motion capture, we compared the performance of these headsets in terms of precision and reliability. Our analysis revealed that both devices exhibit high positioning accuracy, with no significant differences between them. These findings may provide insights for developers and researchers seeking to optimize their VR experiences in particular contexts such as manufacturing.
* 2024 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct)
Real-Time Onboard Object Detection for Augmented Reality: Enhancing Head-Mounted Display with YOLOv8
Jun 06, 2023This paper introduces a software architecture for real-time object detection using machine learning (ML) in an augmented reality (AR) environment. Our approach uses the recent state-of-the-art YOLOv8 network that runs onboard on the Microsoft HoloLens 2 head-mounted display (HMD). The primary motivation behind this research is to enable the application of advanced ML models for enhanced perception and situational awareness with a wearable, hands-free AR platform. We show the image processing pipeline for the YOLOv8 model and the techniques used to make it real-time on the resource-limited edge computing platform of the headset. The experimental results demonstrate that our solution achieves real-time processing without needing offloading tasks to the cloud or any other external servers while retaining satisfactory accuracy regarding the usual mAP metric and measured qualitative performance
Reproducibility of Machine Learning: Terminology, Recommendations and Open Issues
Feb 24, 2023



Reproducibility is one of the core dimensions that concur to deliver Trustworthy Artificial Intelligence. Broadly speaking, reproducibility can be defined as the possibility to reproduce the same or a similar experiment or method, thereby obtaining the same or similar results as the original scientists. It is an essential ingredient of the scientific method and crucial for gaining trust in relevant claims. A reproducibility crisis has been recently acknowledged by scientists and this seems to affect even more Artificial Intelligence and Machine Learning, due to the complexity of the models at the core of their recent successes. Notwithstanding the recent debate on Artificial Intelligence reproducibility, its practical implementation is still insufficient, also because many technical issues are overlooked. In this survey, we critically review the current literature on the topic and highlight the open issues. Our contribution is three-fold. We propose a concise terminological review of the terms coming into play. We collect and systematize existing recommendations for achieving reproducibility, putting forth the means to comply with them. We identify key elements often overlooked in modern Machine Learning and provide novel recommendations for them. We further specialize these for two critical application domains, namely the biomedical and physical artificial intelligence fields.
Fast Kinodynamic Planning on the Constraint Manifold with Deep Neural Networks
Jan 12, 2023



Motion planning is a mature area of research in robotics with many well-established methods based on optimization or sampling the state space, suitable for solving kinematic motion planning. However, when dynamic motions under constraints are needed and computation time is limited, fast kinodynamic planning on the constraint manifold is indispensable. In recent years, learning-based solutions have become alternatives to classical approaches, but they still lack comprehensive handling of complex constraints, such as planning on a lower-dimensional manifold of the task space while considering the robot's dynamics. This paper introduces a novel learning-to-plan framework that exploits the concept of constraint manifold, including dynamics, and neural planning methods. Our approach generates plans satisfying an arbitrary set of constraints and computes them in a short constant time, namely the inference time of a neural network. This allows the robot to plan and replan reactively, making our approach suitable for dynamic environments. We validate our approach on two simulated tasks and in a demanding real-world scenario, where we use a Kuka LBR Iiwa 14 robotic arm to perform the hitting movement in robotic Air Hockey.
Learning an Efficient Terrain Representation for Haptic Localization of a Legged Robot
Sep 29, 2022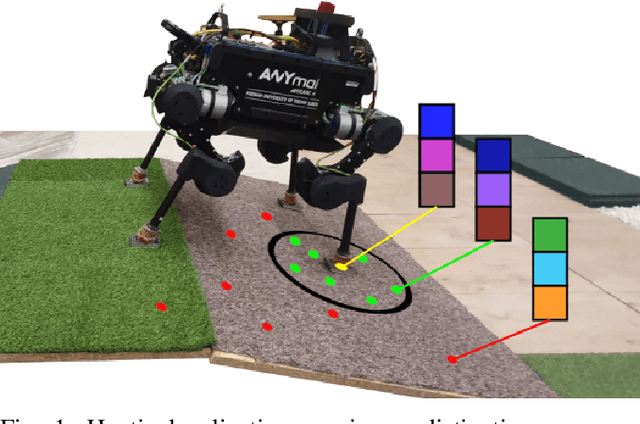



Although haptic sensing has recently been used for legged robot localization in extreme environments where a camera or LiDAR might fail, the problem of efficiently representing the haptic signatures in a learned prior map is still open. This paper introduces an approach to terrain representation for haptic localization inspired by recent trends in machine learning. It combines this approach with the proven Monte Carlo algorithm to obtain an accurate, computation-efficient, and practical method for localizing legged robots under adversarial environmental conditions. We apply the triplet loss concept to learn highly descriptive embeddings in a transformer-based neural network. As the training haptic data are not labeled, the positive and negative examples are discriminated by their geometric locations discovered while training. We demonstrate experimentally that the proposed approach outperforms by a large margin the previous solutions to haptic localization of legged robots concerning the accuracy, inference time, and the amount of data stored in the map. As far as we know, this is the first approach that completely removes the need to use a dense terrain map for accurate haptic localization, thus paving the way to practical applications.
Speeding up deep neural network-based planning of local car maneuvers via efficient B-spline path construction
Mar 14, 2022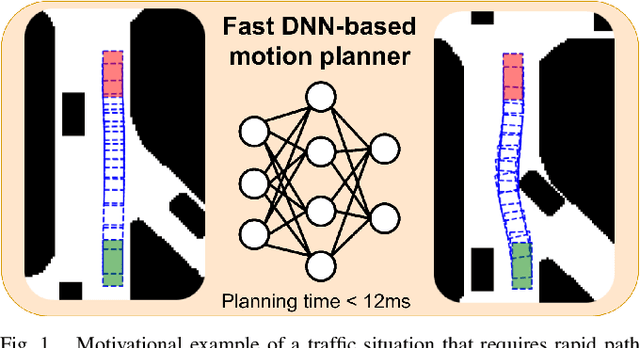
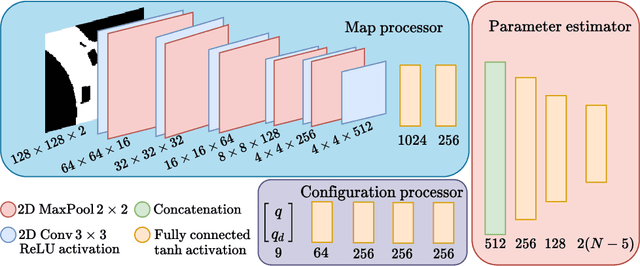

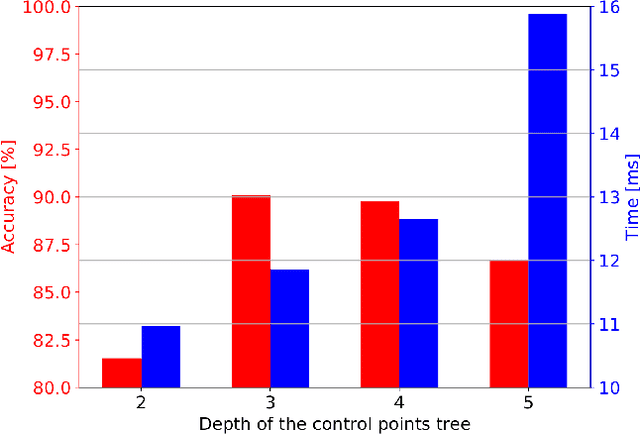
This paper demonstrates how an efficient representation of the planned path using B-splines, and a construction procedure that takes advantage of the neural network's inductive bias, speed up both the inference and training of a DNN-based motion planner. We build upon our recent work on learning local car maneuvers from past experience using a DNN architecture, introducing a novel B-spline path construction method, making it possible to generate local maneuvers in almost constant time of about 11 ms, respecting a number of constraints imposed by the environment map and the kinematics of a car-like vehicle. We evaluate thoroughly the new planner employing the recent Bench-MR framework to obtain quantitative results showing that our method outperforms state-of-the-art planners by a large margin in the considered task.
On the descriptive power of LiDAR intensity images for segment-based loop closing in 3-D SLAM
Aug 03, 2021



We propose an extension to the segment-based global localization method for LiDAR SLAM using descriptors learned considering the visual context of the segments. A new architecture of the deep neural network is presented that learns the visual context acquired from synthetic LiDAR intensity images. This approach allows a single multi-beam LiDAR to produce rich and highly descriptive location signatures. The method is tested on two public datasets, demonstrating an improved descriptiveness of the new descriptors, and more reliable loop closure detection in SLAM. Attention analysis of the network is used to show the importance of focusing on the broader context rather than only on the 3-D segment.
A New Neural Network Architecture Invariant to the Action of Symmetry Subgroups
Dec 11, 2020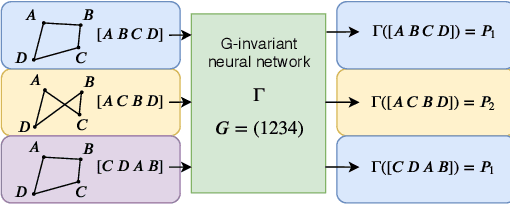

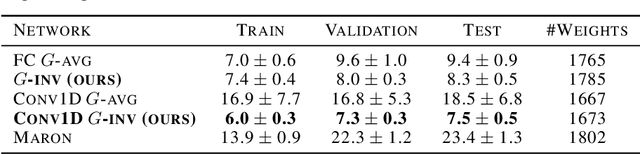
We propose a computationally efficient $G$-invariant neural network that approximates functions invariant to the action of a given permutation subgroup $G \leq S_n$ of the symmetric group on input data. The key element of the proposed network architecture is a new $G$-invariant transformation module, which produces a $G$-invariant latent representation of the input data. Theoretical considerations are supported by numerical experiments, which demonstrate the effectiveness and strong generalization properties of the proposed method in comparison to other $G$-invariant neural networks.