 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Accurate is the Positioning in VR? Using Motion Capture and Robotics to Compare Positioning Capabilities of Popular VR Headsets
Dec 09, 2024In this paper, we introduce a new methodology for assessing the positioning accuracy of virtual reality (VR) headsets, utilizing a cooperative industrial robot to simulate user head trajectories in a reproducible manner. We conduct a comprehensive evaluation of two popular VR headsets, i.e., Meta Quest 2 and Meta Quest Pro. Using head movement trajectories captured from realistic VR game scenarios with motion capture, we compared the performance of these headsets in terms of precision and reliability. Our analysis revealed that both devices exhibit high positioning accuracy, with no significant differences between them. These findings may provide insights for developers and researchers seeking to optimize their VR experiences in particular contexts such as manufacturing.
* 2024 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct)
Real-Time Onboard Object Detection for Augmented Reality: Enhancing Head-Mounted Display with YOLOv8
Jun 06, 2023This paper introduces a software architecture for real-time object detection using machine learning (ML) in an augmented reality (AR) environment. Our approach uses the recent state-of-the-art YOLOv8 network that runs onboard on the Microsoft HoloLens 2 head-mounted display (HMD). The primary motivation behind this research is to enable the application of advanced ML models for enhanced perception and situational awareness with a wearable, hands-free AR platform. We show the image processing pipeline for the YOLOv8 model and the techniques used to make it real-time on the resource-limited edge computing platform of the headset. The experimental results demonstrate that our solution achieves real-time processing without needing offloading tasks to the cloud or any other external servers while retaining satisfactory accuracy regarding the usual mAP metric and measured qualitative performance
HyperColor: A HyperNetwork Approach for Synthesizing Auto-colored 3D Models for Game Scenes Population
Aug 03, 2021
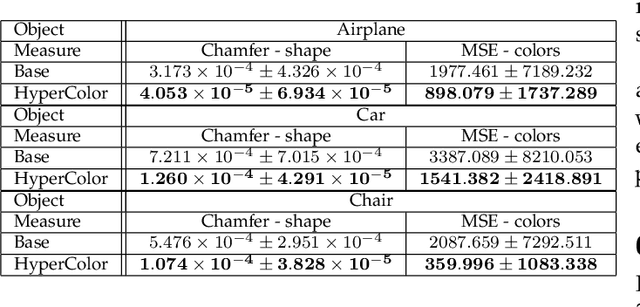

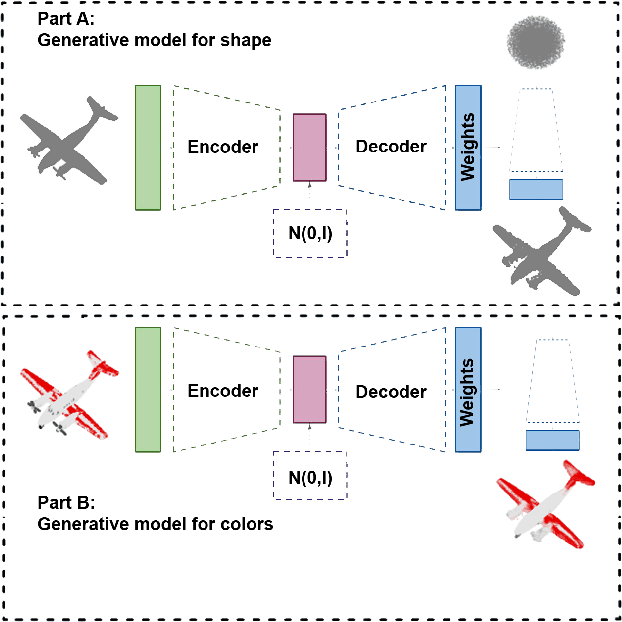
Designing a 3D game scene is a tedious task that often requires a substantial amount of work. Typically, this task involves synthesis, coloring, and placement of 3D models within the game scene. To lessen this workload, we can apply machine learning to automate some aspects of the game scene development. Earlier research has already tackled automated generation of the game scene background with machine learning. However, model auto-coloring remains an underexplored problem. The automatic coloring of a 3D model is a challenging task, especially when dealing with the digital representation of a colorful, multipart object. In such a case, we have to ``understand'' the object's composition and coloring scheme of each part. Existing single-stage methods have their own caveats such as the need for segmentation of the object or generating individual parts that have to be assembled together to yield the final model. We address these limitations by proposing a two-stage training approach to synthesize auto-colored 3D models. In the first stage, we obtain a 3D point cloud representing a 3D object, whilst in the second stage, we assign colors to points within such cloud. Next, by leveraging the so-called triangulation trick, we generate a 3D mesh in which the surfaces are colored based on interpolation of colored points representing vertices of a given mesh triangle. This approach allows us to generate a smooth coloring scheme. Experimental evaluation shows that our two-stage approach gives better results in terms of shape reconstruction and coloring when compared to traditional single-stage techniques.