 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Accurate is the Positioning in VR? Using Motion Capture and Robotics to Compare Positioning Capabilities of Popular VR Headsets
Dec 09, 2024In this paper, we introduce a new methodology for assessing the positioning accuracy of virtual reality (VR) headsets, utilizing a cooperative industrial robot to simulate user head trajectories in a reproducible manner. We conduct a comprehensive evaluation of two popular VR headsets, i.e., Meta Quest 2 and Meta Quest Pro. Using head movement trajectories captured from realistic VR game scenarios with motion capture, we compared the performance of these headsets in terms of precision and reliability. Our analysis revealed that both devices exhibit high positioning accuracy, with no significant differences between them. These findings may provide insights for developers and researchers seeking to optimize their VR experiences in particular contexts such as manufacturing.
* 2024 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct)
Real-Time Onboard Object Detection for Augmented Reality: Enhancing Head-Mounted Display with YOLOv8
Jun 06, 2023This paper introduces a software architecture for real-time object detection using machine learning (ML) in an augmented reality (AR) environment. Our approach uses the recent state-of-the-art YOLOv8 network that runs onboard on the Microsoft HoloLens 2 head-mounted display (HMD). The primary motivation behind this research is to enable the application of advanced ML models for enhanced perception and situational awareness with a wearable, hands-free AR platform. We show the image processing pipeline for the YOLOv8 model and the techniques used to make it real-time on the resource-limited edge computing platform of the headset. The experimental results demonstrate that our solution achieves real-time processing without needing offloading tasks to the cloud or any other external servers while retaining satisfactory accuracy regarding the usual mAP metric and measured qualitative performance
Learning an Efficient Terrain Representation for Haptic Localization of a Legged Robot
Sep 29, 2022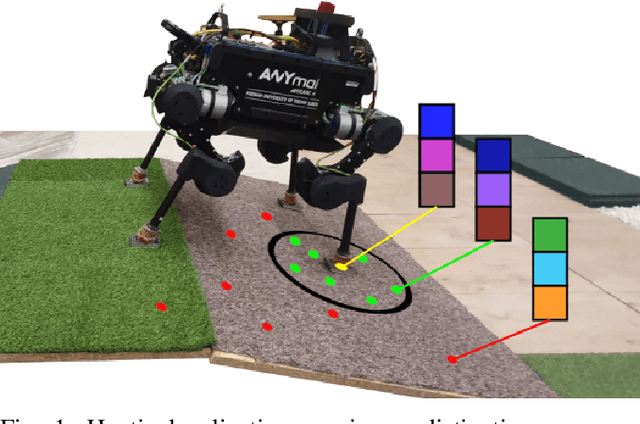



Although haptic sensing has recently been used for legged robot localization in extreme environments where a camera or LiDAR might fail, the problem of efficiently representing the haptic signatures in a learned prior map is still open. This paper introduces an approach to terrain representation for haptic localization inspired by recent trends in machine learning. It combines this approach with the proven Monte Carlo algorithm to obtain an accurate, computation-efficient, and practical method for localizing legged robots under adversarial environmental conditions. We apply the triplet loss concept to learn highly descriptive embeddings in a transformer-based neural network. As the training haptic data are not labeled, the positive and negative examples are discriminated by their geometric locations discovered while training. We demonstrate experimentally that the proposed approach outperforms by a large margin the previous solutions to haptic localization of legged robots concerning the accuracy, inference time, and the amount of data stored in the map. As far as we know, this is the first approach that completely removes the need to use a dense terrain map for accurate haptic localization, thus paving the way to practical applications.
MinkLoc3D-SI: 3D LiDAR place recognition with sparse convolutions, spherical coordinates, and intensity
Dec 27, 2021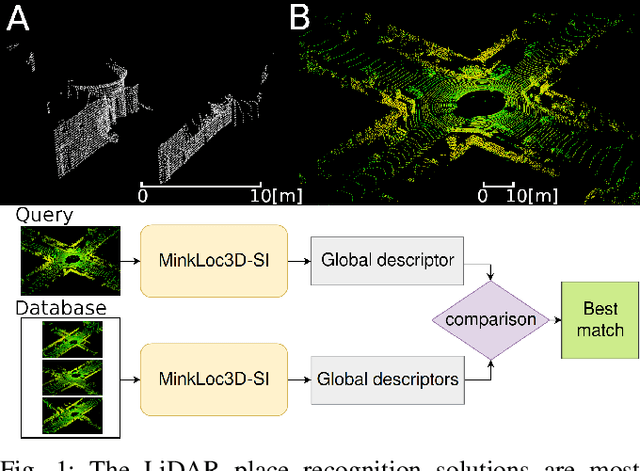


The 3D LiDAR place recognition aims to estimate a coarse localization in a previously seen environment based on a single scan from a rotating 3D LiDAR sensor. The existing solutions to this problem include hand-crafted point cloud descriptors (e.g., ScanContext, M2DP, LiDAR IRIS) and deep learning-based solutions (e.g., PointNetVLAD, PCAN, LPDNet, DAGC, MinkLoc3D), which are often only evaluated on accumulated 2D scans from the Oxford RobotCar dataset. We introduce MinkLoc3D-SI, a sparse convolution-based solution that utilizes spherical coordinates of 3D points and processes the intensity of 3D LiDAR measurements, improving the performance when a single 3D LiDAR scan is used. Our method integrates the improvements typical for hand-crafted descriptors (like ScanContext) with the most efficient 3D sparse convolutions (MinkLoc3D). Our experiments show improved results on single scans from 3D LiDARs (USyd Campus dataset) and great generalization ability (KITTI dataset). Using intensity information on accumulated 2D scans (RobotCar Intensity dataset) improves the performance, even though spherical representation doesn't produce a noticeable improvement. As a result, MinkLoc3D-SI is suited for single scans obtained from a 3D LiDAR, making it applicable in autonomous vehicles.
Navigating by Touch: Haptic Monte Carlo Localization via Geometric Sensing and Terrain Classification
Aug 18, 2021
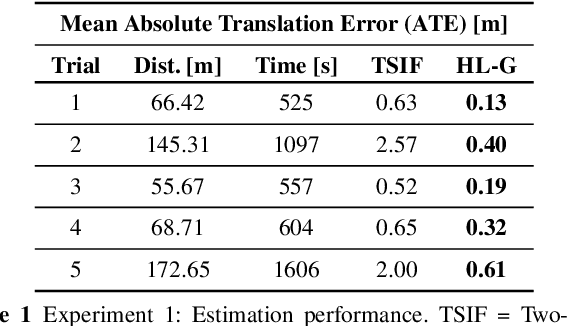
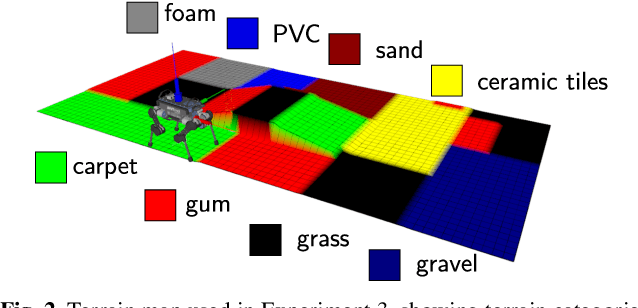
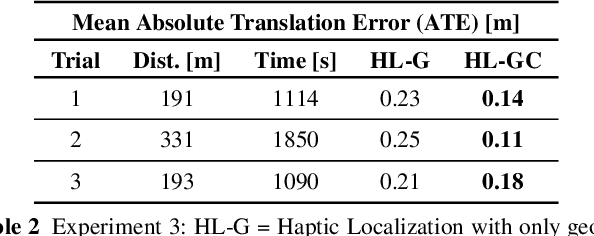
Legged robot navigation in extreme environments can hinder the use of cameras and laser scanners due to darkness, air obfuscation or sensor damage. In these conditions, proprioceptive sensing will continue to work reliably. In this paper, we propose a purely proprioceptive localization algorithm which fuses information from both geometry and terrain class, to localize a legged robot within a prior map. First, a terrain classifier computes the probability that a foot has stepped on a particular terrain class from sensed foot forces. Then, a Monte Carlo-based estimator fuses this terrain class probability with the geometric information of the foot contact points. Results are demonstrated showing this approach operating online and onboard a ANYmal B300 quadruped robot traversing a series of terrain courses with different geometries and terrain types over more than 1.2km. The method keeps the localization error below 20cm using only the information coming from the feet, IMU, and joints of the quadruped.