 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaRF-SLAM: Scale-Consistent Reconstruction with Feed-Forward Models and Classical Visual SLAM
May 29, 2026Recent works have explored unifying SLAM with geometric foundation models (GFMs). However, directly using GFM predictions for tracking is highly sensitive to model capability and uncertainty, as geometric inaccuracies in the predictions can adversely affect pose estimation. To address this limitation, we present a decoupled framework that integrates classical feature-based SLAM with GFMs, which achieves higher quality and more consistent dense reconstruction. In brief, we use classical visual SLAM for robust low-latency tracking and use GFMs exclusively for mapping. By anchoring mapping to poses produced by the SLAM module and optimizing across depth scales, the proposed design avoids propagating inaccuracies from GFM predictions into pose estimation while imposing geometric constraints on the reconstruction. The system builds submaps from multiple posed keyframes and enforces scale consistency via lightweight frame and submap scale optimization. It also performs projection-based point cloud fusion within each submap, and updates submaps online to reflect trajectory updates from the feature-based SLAM. To evaluate tracking and reconstruction of our method, we introduce a loop-rich, building-scale indoor dataset with accurate sensor trajectories and LiDAR ground-truth. Experiments show that our approach achieves superior trajectory accuracy while improving reconstruction precision by 10%-20% over existing methods, with about 2 cm reconstruction error per 10 m chunk on building-scale dataset. On large-scale outdoor datasets, it attains 10 cm error per 30 m chunk (w.r.t LiDAR ground-truth models).
LEXI-SG: Monocular 3D Scene Graph Mapping with Room-Guided Feed-Forward Reconstruction
May 13, 2026Scene graphs are becoming a standard representation for robot navigation, providing hierarchical geometric and semantic scene understanding. However, most scene graph mapping methods rely on depth cameras or LiDAR sensors. In this work, we present LEXI-SG, the first dense monocular visual mapping system for open-vocabulary 3D scene graphs using only RGB camera input. Our approach exploits the semantic priors of open-vocabulary foundation models to partition the scene into rooms, deferring feed-forward reconstruction to when each room is fully observed -- enabling scalable dense mapping without sliding-window scale inconsistencies. We propose a room-based factor graph formulation to globally align room reconstructions while preserving local map consistency and naturally imposing the semantic scene graph hierarchy. Within each room, we further support open-vocabulary object segmentation and tracking. We validate LEXI-SG on indoor scenes from the Habitat-Matterport 3D and self-collected egocentric office sequences. We evaluate its performance against existing feed-forward SLAM methods, as well as established scene graphs baselines. We demonstrate improved trajectory estimation and dense reconstruction, as well as, competitive performance in open-vocabulary segmentation. LEXI-SG shows that accurate, scalable, open-vocabulary 3D scene graphs can be achieved from monocular RGB alone. Our project page and office sequences are available here: https://ori-drs.github.io/lexisg-web/.
DigiForest: Digital Analytics and Robotics for Sustainable Forestry
Apr 16, 2026Covering one third of Earth's land surface, forests are vital to global biodiversity, climate regulation, and human well-being. In Europe, forests and woodlands reach approximately 40% of land area, and the forestry sector is central to achieving the EU's climate neutrality and biodiversity goals; these emphasize sustainable forest management, increased use of long-lived wood products, and resilient forest ecosystems. To meet these goals and properly address their inherent challenges, current practices require further innovation. This chapter introduces DigiForest, a novel, large-scale precision forestry approach leveraging digital technologies and autonomous robotics. DigiForest is structured around four main components: (1) autonomous, heterogeneous mobile robots (aerial, legged, and marsupial) for tree-level data collection; (2) automated extraction of tree traits to build forest inventories; (3) a Decision Support System (DSS) for forecasting forest growth and supporting decision-making; and (4) low-impact selective logging using purpose-built autonomous harvesters. These technologies have been extensively validated in real-world conditions in several locations, including forests in Finland, the UK, and Switzerland.
TreeLoc++: Robust 6-DoF LiDAR Localization in Forests with a Compact Digital Forest Inventory
Mar 04, 2026Reliable localization is essential for sustainable forest management, as it allows robots or sensor systems to revisit and monitor the status of individual trees over long periods. In modern forestry, this management is structured around Digital Forest Inventories (DFIs), which encode stems using compact geometric attributes rather than raw data. Despite their central role, DFIs have been overlooked in localization research, and most methods still rely on dense gigabyte-sized point clouds that are costly to store and maintain. To improve upon this, we propose TreeLoc++, a global localization framework that operates directly on DFIs as a discriminative representation, eliminating the need to use the raw point clouds. TreeLoc++ reduces false matches in structurally ambiguous forests and improves the reliability of full 6-DoF pose estimation. It augments coarse retrieval with a pairwise distance histogram that encodes local tree-layout context, subsequently refining candidates via DBH-based filtering and yaw-consistent inlier selection to further reduce mismatches. Furthermore, a constrained optimization leveraging tree geometry jointly estimates roll, pitch, and height, enhancing pose stability and enabling accurate localization without reliance on dense 3D point cloud data. Evaluations on 27 sequences recorded in forests across three datasets and four countries show that TreeLoc++ achieves precise localization with centimeter-level accuracy. We further demonstrate robustness to long-term change by localizing data recorded in 2025 against inventories built from 2023 data, spanning a two-year interval. The system represents 15 sessions spanning 7.98 km of trajectories using only 250KB of map data and outperforms both hand-crafted and learning-based baselines that rely on point cloud maps. This demonstrates the scalability of TreeLoc++ for long-term deployment.
Sapling-NeRF: Geo-Localised Sapling Reconstruction in Forests for Ecological Monitoring
Feb 26, 2026Saplings are key indicators of forest regeneration and overall forest health. However, their fine-scale architectural traits are difficult to capture with existing 3D sensing methods, which make quantitative evaluation difficult. Terrestrial Laser Scanners (TLS), Mobile Laser Scanners (MLS), or traditional photogrammetry approaches poorly reconstruct thin branches, dense foliage, and lack the scale consistency needed for long-term monitoring. Implicit 3D reconstruction methods such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) are promising alternatives, but cannot recover the true scale of a scene and lack any means to be accurately geo-localised. In this paper, we present a pipeline which fuses NeRF, LiDAR SLAM, and GNSS to enable repeatable, geo-localised ecological monitoring of saplings. Our system proposes a three-level representation: (i) coarse Earth-frame localisation using GNSS, (ii) LiDAR-based SLAM for centimetre-accurate localisation and reconstruction, and (iii) NeRF-derived object-centric dense reconstruction of individual saplings. This approach enables repeatable quantitative evaluation and long-term monitoring of sapling traits. Our experiments in forest plots in Wytham Woods (Oxford, UK) and Evo (Finland) show that stem height, branching patterns, and leaf-to-wood ratios can be captured with increased accuracy as compared to TLS. We demonstrate that accurate stem skeletons and leaf distributions can be measured for saplings with heights between 0.5m and 2m in situ, giving ecologists access to richer structural and quantitative data for analysing forest dynamics.
TreeLoc: 6-DoF LiDAR Global Localization in Forests via Inter-Tree Geometric Matching
Feb 03, 2026Reliable localization is crucial for navigation in forests, where GPS is often degraded and LiDAR measurements are repetitive, occluded, and structurally complex. These conditions weaken the assumptions of traditional urban-centric localization methods, which assume that consistent features arise from unique structural patterns, necessitating forest-centric solutions to achieve robustness in these environments. To address these challenges, we propose TreeLoc, a LiDAR-based global localization framework for forests that handles place recognition and 6-DoF pose estimation. We represent scenes using tree stems and their Diameter at Breast Height (DBH), which are aligned to a common reference frame via their axes and summarized using the tree distribution histogram (TDH) for coarse matching, followed by fine matching with a 2D triangle descriptor. Finally, pose estimation is achieved through a two-step geometric verification. On diverse forest benchmarks, TreeLoc outperforms baselines, achieving precise localization. Ablation studies validate the contribution of each component. We also propose applications for long-term forest management using descriptors from a compact global tree database. TreeLoc is open-sourced for the robotics community at https://github.com/minwoo0611/TreeLoc.
Seeing in the Dark: Benchmarking Egocentric 3D Vision with the Oxford Day-and-Night Dataset
Jun 04, 2025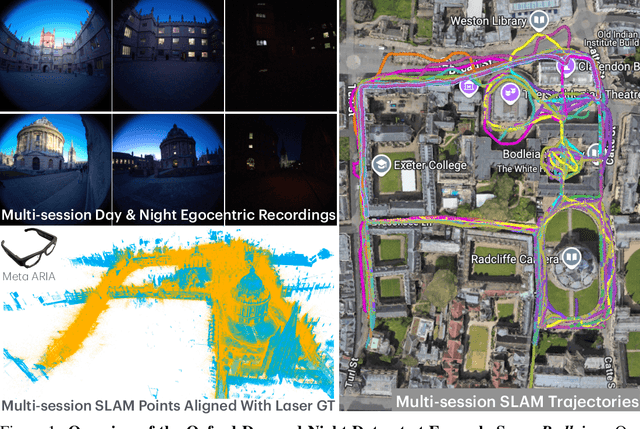


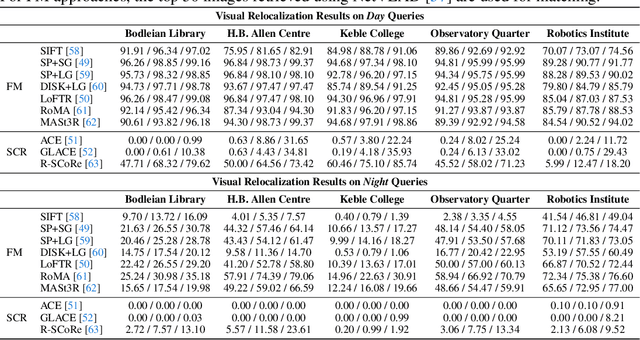
We introduce Oxford Day-and-Night, a large-scale, egocentric dataset for novel view synthesis (NVS) and visual relocalisation under challenging lighting conditions. Existing datasets often lack crucial combinations of features such as ground-truth 3D geometry, wide-ranging lighting variation, and full 6DoF motion. Oxford Day-and-Night addresses these gaps by leveraging Meta ARIA glasses to capture egocentric video and applying multi-session SLAM to estimate camera poses, reconstruct 3D point clouds, and align sequences captured under varying lighting conditions, including both day and night. The dataset spans over 30 $\mathrm{km}$ of recorded trajectories and covers an area of 40,000 $\mathrm{m}^2$, offering a rich foundation for egocentric 3D vision research. It supports two core benchmarks, NVS and relocalisation, providing a unique platform for evaluating models in realistic and diverse environments.
ImLPR: Image-based LiDAR Place Recognition using Vision Foundation Models
May 23, 2025LiDAR Place Recognition (LPR) is a key component in robotic localization, enabling robots to align current scans with prior maps of their environment. While Visual Place Recognition (VPR) has embraced Vision Foundation Models (VFMs) to enhance descriptor robustness, LPR has relied on task-specific models with limited use of pre-trained foundation-level knowledge. This is due to the lack of 3D foundation models and the challenges of using VFM with LiDAR point clouds. To tackle this, we introduce ImLPR, a novel pipeline that employs a pre-trained DINOv2 VFM to generate rich descriptors for LPR. To our knowledge, ImLPR is the first method to leverage a VFM to support LPR. ImLPR converts raw point clouds into Range Image Views (RIV) to leverage VFM in the LiDAR domain. It employs MultiConv adapters and Patch-InfoNCE loss for effective feature learning. We validate ImLPR using public datasets where it outperforms state-of-the-art (SOTA) methods in intra-session and inter-session LPR with top Recall@1 and F1 scores across various LiDARs. We also demonstrate that RIV outperforms Bird's-Eye-View (BEV) as a representation choice for adapting LiDAR for VFM. We release ImLPR as open source for the robotics community.
Boxi: Design Decisions in the Context of Algorithmic Performance for Robotics
Apr 25, 2025Achieving robust autonomy in mobile robots operating in complex and unstructured environments requires a multimodal sensor suite capable of capturing diverse and complementary information. However, designing such a sensor suite involves multiple critical design decisions, such as sensor selection, component placement, thermal and power limitations, compute requirements, networking, synchronization, and calibration. While the importance of these key aspects is widely recognized, they are often overlooked in academia or retained as proprietary knowledge within large corporations. To improve this situation, we present Boxi, a tightly integrated sensor payload that enables robust autonomy of robots in the wild. This paper discusses the impact of payload design decisions made to optimize algorithmic performance for downstream tasks, specifically focusing on state estimation and mapping. Boxi is equipped with a variety of sensors: two LiDARs, 10 RGB cameras including high-dynamic range, global shutter, and rolling shutter models, an RGB-D camera, 7 inertial measurement units (IMUs) of varying precision, and a dual antenna RTK GNSS system. Our analysis shows that time synchronization, calibration, and sensor modality have a crucial impact on the state estimation performance. We frame this analysis in the context of cost considerations and environment-specific challenges. We also present a mobile sensor suite `cookbook` to serve as a comprehensive guideline, highlighting generalizable key design considerations and lessons learned during the development of Boxi. Finally, we demonstrate the versatility of Boxi being used in a variety of applications in real-world scenarios, contributing to robust autonomy. More details and code: https://github.com/leggedrobotics/grand_tour_box
OpenLex3D: A New Evaluation Benchmark for Open-Vocabulary 3D Scene Representations
Mar 25, 2025



3D scene understanding has been transformed by open-vocabulary language models that enable interaction via natural language. However, the evaluation of these representations is limited to closed-set semantics that do not capture the richness of language. This work presents OpenLex3D, a dedicated benchmark to evaluate 3D open-vocabulary scene representations. OpenLex3D provides entirely new label annotations for 23 scenes from Replica, ScanNet++, and HM3D, which capture real-world linguistic variability by introducing synonymical object categories and additional nuanced descriptions. By introducing an open-set 3D semantic segmentation task and an object retrieval task, we provide insights on feature precision, segmentation, and downstream capabilities. We evaluate various existing 3D open-vocabulary methods on OpenLex3D, showcasing failure cases, and avenues for improvement. The benchmark is publicly available at: https://openlex3d.github.io/.