 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEXI-SG: Monocular 3D Scene Graph Mapping with Room-Guided Feed-Forward Reconstruction
May 13, 2026Scene graphs are becoming a standard representation for robot navigation, providing hierarchical geometric and semantic scene understanding. However, most scene graph mapping methods rely on depth cameras or LiDAR sensors. In this work, we present LEXI-SG, the first dense monocular visual mapping system for open-vocabulary 3D scene graphs using only RGB camera input. Our approach exploits the semantic priors of open-vocabulary foundation models to partition the scene into rooms, deferring feed-forward reconstruction to when each room is fully observed -- enabling scalable dense mapping without sliding-window scale inconsistencies. We propose a room-based factor graph formulation to globally align room reconstructions while preserving local map consistency and naturally imposing the semantic scene graph hierarchy. Within each room, we further support open-vocabulary object segmentation and tracking. We validate LEXI-SG on indoor scenes from the Habitat-Matterport 3D and self-collected egocentric office sequences. We evaluate its performance against existing feed-forward SLAM methods, as well as established scene graphs baselines. We demonstrate improved trajectory estimation and dense reconstruction, as well as, competitive performance in open-vocabulary segmentation. LEXI-SG shows that accurate, scalable, open-vocabulary 3D scene graphs can be achieved from monocular RGB alone. Our project page and office sequences are available here: https://ori-drs.github.io/lexisg-web/.
OpenLex3D: A New Evaluation Benchmark for Open-Vocabulary 3D Scene Representations
Mar 25, 2025



3D scene understanding has been transformed by open-vocabulary language models that enable interaction via natural language. However, the evaluation of these representations is limited to closed-set semantics that do not capture the richness of language. This work presents OpenLex3D, a dedicated benchmark to evaluate 3D open-vocabulary scene representations. OpenLex3D provides entirely new label annotations for 23 scenes from Replica, ScanNet++, and HM3D, which capture real-world linguistic variability by introducing synonymical object categories and additional nuanced descriptions. By introducing an open-set 3D semantic segmentation task and an object retrieval task, we provide insights on feature precision, segmentation, and downstream capabilities. We evaluate various existing 3D open-vocabulary methods on OpenLex3D, showcasing failure cases, and avenues for improvement. The benchmark is publicly available at: https://openlex3d.github.io/.
The Bare Necessities: Designing Simple, Effective Open-Vocabulary Scene Graphs
Dec 02, 20243D open-vocabulary scene graph methods are a promising map representation for embodied agents, however many current approaches are computationally expensive. In this paper, we reexamine the critical design choices established in previous works to optimize both efficiency and performance. We propose a general scene graph framework and conduct three studies that focus on image pre-processing, feature fusion, and feature selection. Our findings reveal that commonly used image pre-processing techniques provide minimal performance improvement while tripling computation (on a per object view basis). We also show that averaging feature labels across different views significantly degrades performance. We study alternative feature selection strategies that enhance performance without adding unnecessary computational costs. Based on our findings, we introduce a computationally balanced approach for 3D point cloud segmentation with per-object features. The approach matches state-of-the-art classification accuracy while achieving a threefold reduction in computation.
Exosense: A Vision-Centric Scene Understanding System For Safe Exoskeleton Navigation
Mar 21, 2024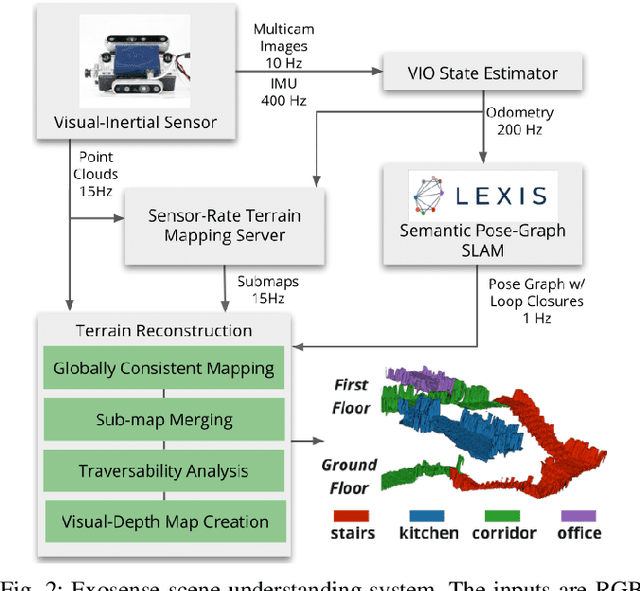
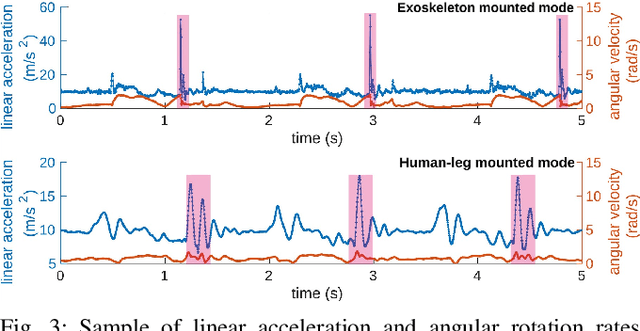
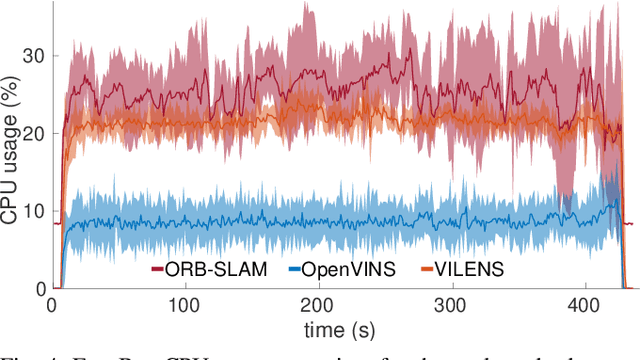
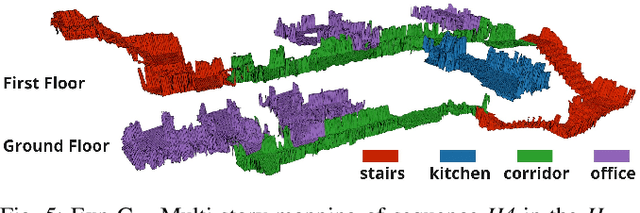
Exoskeletons for daily use by those with mobility impairments are being developed. They will require accurate and robust scene understanding systems. Current research has used vision to identify immediate terrain and geometric obstacles, however these approaches are constrained to detections directly in front of the user and are limited to classifying a finite range of terrain types (e.g., stairs, ramps and level-ground). This paper presents Exosense, a vision-centric scene understanding system which is capable of generating rich, globally-consistent elevation maps, incorporating both semantic and terrain traversability information. It features an elastic Atlas mapping framework associated with a visual SLAM pose graph, embedded with open-vocabulary room labels from a Vision-Language Model (VLM). The device's design includes a wide field-of-view (FoV) fisheye multi-camera system to mitigate the challenges introduced by the exoskeleton walking pattern. We demonstrate the system's robustness to the challenges of typical periodic walking gaits, and its ability to construct accurate semantically-rich maps in indoor settings. Additionally, we showcase its potential for motion planning -- providing a step towards safe navigation for exoskeletons.
Language-EXtended Indoor SLAM (LEXIS): A Versatile System for Real-time Visual Scene Understanding
Sep 26, 2023



Versatile and adaptive semantic understanding would enable autonomous systems to comprehend and interact with their surroundings. Existing fixed-class models limit the adaptability of indoor mobile and assistive autonomous systems. In this work, we introduce LEXIS, a real-time indoor Simultaneous Localization and Mapping (SLAM) system that harnesses the open-vocabulary nature of Large Language Models (LLMs) to create a unified approach to scene understanding and place recognition. The approach first builds a topological SLAM graph of the environment (using visual-inertial odometry) and embeds Contrastive Language-Image Pretraining (CLIP) features in the graph nodes. We use this representation for flexible room classification and segmentation, serving as a basis for room-centric place recognition. This allows loop closure searches to be directed towards semantically relevant places. Our proposed system is evaluated using both public, simulated data and real-world data, covering office and home environments. It successfully categorizes rooms with varying layouts and dimensions and outperforms the state-of-the-art (SOTA). For place recognition and trajectory estimation tasks we achieve equivalent performance to the SOTA, all also utilizing the same pre-trained model. Lastly, we demonstrate the system's potential for planning.