 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Prioritization in Visual Counterfactual Explanations with Weighted Segmentation and Auto-Adaptive Region Selection
Nov 17, 2025In the domain of non-generative visual counterfactual explanations (CE), traditional techniques frequently involve the substitution of sections within a query image with corresponding sections from distractor images. Such methods have historically overlooked the semantic relevance of the replacement regions to the target object, thereby impairing the model's interpretability and hindering the editing workflow. Addressing these challenges, the present study introduces an innovative methodology named as Weighted Semantic Map with Auto-adaptive Candidate Editing Network (WSAE-Net). Characterized by two significant advancements: the determination of an weighted semantic map and the auto-adaptive candidate editing sequence. First, the generation of the weighted semantic map is designed to maximize the reduction of non-semantic feature units that need to be computed, thereby optimizing computational efficiency. Second, the auto-adaptive candidate editing sequences are designed to determine the optimal computational order among the feature units to be processed, thereby ensuring the efficient generation of counterfactuals while maintaining the semantic relevance of the replacement feature units to the target object. Through comprehensive experimentation, our methodology demonstrates superior performance, contributing to a more lucid and in-depth understanding of visual counterfactual explanations.
Towards Fine-Grained Interpretability: Counterfactual Explanations for Misclassification with Saliency Partition
Nov 11, 2025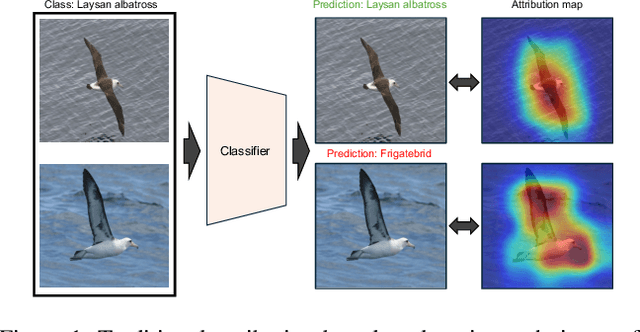
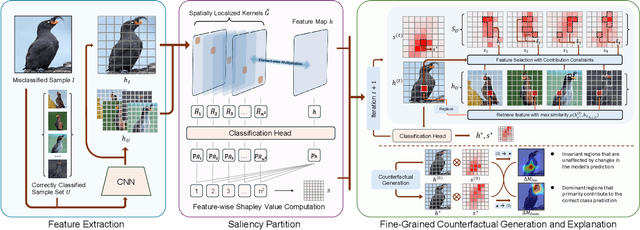

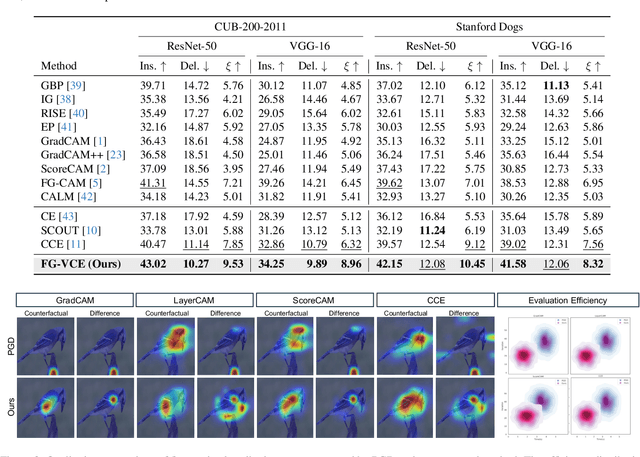
Attribution-based explanation techniques capture key patterns to enhance visual interpretability; however, these patterns often lack the granularity needed for insight in fine-grained tasks, particularly in cases of model misclassification, where explanations may be insufficiently detailed. To address this limitation, we propose a fine-grained counterfactual explanation framework that generates both object-level and part-level interpretability, addressing two fundamental questions: (1) which fine-grained features contribute to model misclassification, and (2) where dominant local features influence counterfactual adjustments. Our approach yields explainable counterfactuals in a non-generative manner by quantifying similarity and weighting component contributions within regions of interest between correctly classified and misclassified samples. Furthermore, we introduce a saliency partition module grounded in Shapley value contributions, isolating features with region-specific relevance. Extensive experiments demonstrate the superiority of our approach in capturing more granular, intuitively meaningful regions, surpassing fine-grained methods.
The Oxford Spires Dataset: Benchmarking Large-Scale LiDAR-Visual Localisation, Reconstruction and Radiance Field Methods
Nov 15, 2024
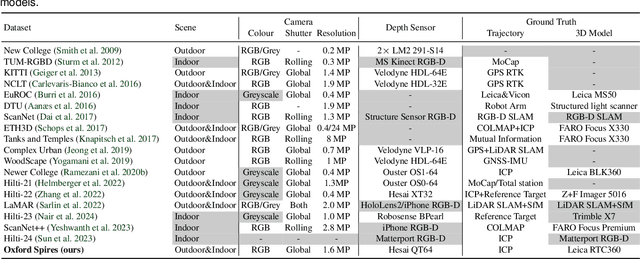
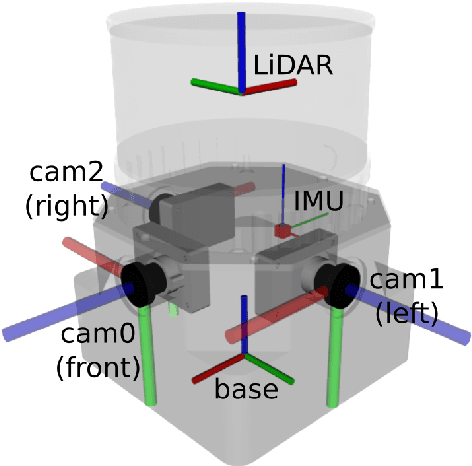
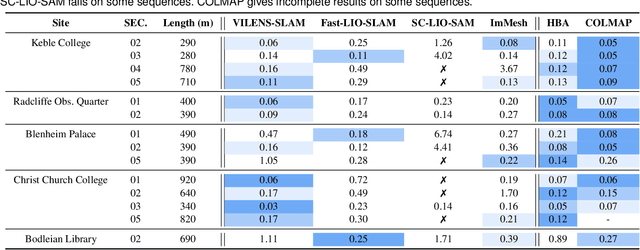
This paper introduces a large-scale multi-modal dataset captured in and around well-known landmarks in Oxford using a custom-built multi-sensor perception unit as well as a millimetre-accurate map from a Terrestrial LiDAR Scanner (TLS). The perception unit includes three synchronised global shutter colour cameras, an automotive 3D LiDAR scanner, and an inertial sensor - all precisely calibrated. We also establish benchmarks for tasks involving localisation, reconstruction, and novel-view synthesis, which enable the evaluation of Simultaneous Localisation and Mapping (SLAM) methods, Structure-from-Motion (SfM) and Multi-view Stereo (MVS) methods as well as radiance field methods such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting. To evaluate 3D reconstruction the TLS 3D models are used as ground truth. Localisation ground truth is computed by registering the mobile LiDAR scans to the TLS 3D models. Radiance field methods are evaluated not only with poses sampled from the input trajectory, but also from viewpoints that are from trajectories which are distant from the training poses. Our evaluation demonstrates a key limitation of state-of-the-art radiance field methods: we show that they tend to overfit to the training poses/images and do not generalise well to out-of-sequence poses. They also underperform in 3D reconstruction compared to MVS systems using the same visual inputs. Our dataset and benchmarks are intended to facilitate better integration of radiance field methods and SLAM systems. The raw and processed data, along with software for parsing and evaluation, can be accessed at https://dynamic.robots.ox.ac.uk/datasets/oxford-spires/.
Visual Localization in 3D Maps: Comparing Point Cloud, Mesh, and NeRF Representations
Aug 21, 2024



This paper introduces and assesses a cross-modal global visual localization system that can localize camera images within a color 3D map representation built using both visual and lidar sensing. We present three different state-of-the-art methods for creating the color 3D maps: point clouds, meshes, and neural radiance fields (NeRF). Our system constructs a database of synthetic RGB and depth image pairs from these representations. This database serves as the basis for global localization. We present an automatic approach that builds this database by synthesizing novel images of the scene and exploiting the 3D structure encoded in the different representations. Next, we present a global localization system that relies on the synthetic image database to accurately estimate the 6 DoF camera poses of monocular query images. Our localization approach relies on different learning-based global descriptors and feature detectors which enable robust image retrieval and matching despite the domain gap between (real) query camera images and the synthetic database images. We assess the system's performance through extensive real-world experiments in both indoor and outdoor settings, in order to evaluate the effectiveness of each map representation and the benefits against traditional structure-from-motion localization approaches. Our results show that all three map representations can achieve consistent localization success rates of 55% and higher across various environments. NeRF synthesized images show superior performance, localizing query images at an average success rate of 72%. Furthermore, we demonstrate that our synthesized database enables global localization even when the map creation data and the localization sequence are captured when travelling in opposite directions. Our system, operating in real-time on a mobile laptop equipped with a GPU, achieves a processing rate of 1Hz.
Exosense: A Vision-Centric Scene Understanding System For Safe Exoskeleton Navigation
Mar 21, 2024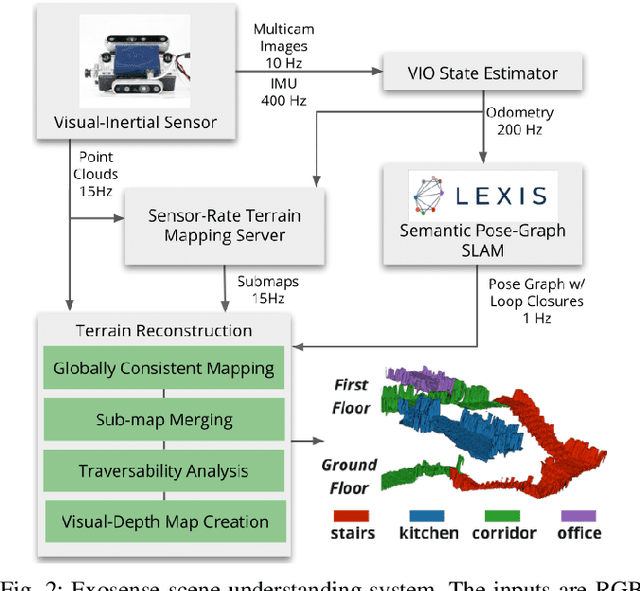
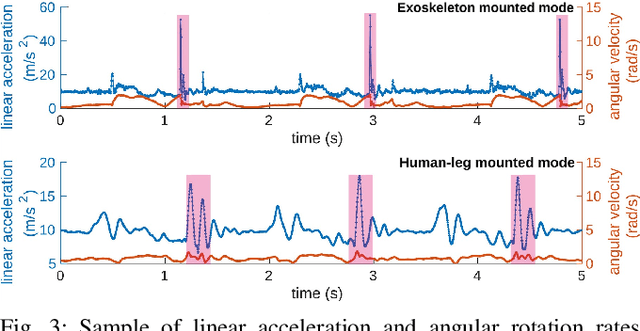
Exoskeletons for daily use by those with mobility impairments are being developed. They will require accurate and robust scene understanding systems. Current research has used vision to identify immediate terrain and geometric obstacles, however these approaches are constrained to detections directly in front of the user and are limited to classifying a finite range of terrain types (e.g., stairs, ramps and level-ground). This paper presents Exosense, a vision-centric scene understanding system which is capable of generating rich, globally-consistent elevation maps, incorporating both semantic and terrain traversability information. It features an elastic Atlas mapping framework associated with a visual SLAM pose graph, embedded with open-vocabulary room labels from a Vision-Language Model (VLM). The device's design includes a wide field-of-view (FoV) fisheye multi-camera system to mitigate the challenges introduced by the exoskeleton walking pattern. We demonstrate the system's robustness to the challenges of typical periodic walking gaits, and its ability to construct accurate semantically-rich maps in indoor settings. Additionally, we showcase its potential for motion planning -- providing a step towards safe navigation for exoskeletons.
LiSTA: Geometric Object-Based Change Detection in Cluttered Environments
Mar 05, 2024We present LiSTA (LiDAR Spatio-Temporal Analysis), a system to detect probabilistic object-level change over time using multi-mission SLAM. Many applications require such a system, including construction, robotic navigation, long-term autonomy, and environmental monitoring. We focus on the semi-static scenario where objects are added, subtracted, or changed in position over weeks or months. Our system combines multi-mission LiDAR SLAM, volumetric differencing, object instance description, and correspondence grouping using learned descriptors to keep track of an open set of objects. Object correspondences between missions are determined by clustering the object's learned descriptors. We demonstrate our approach using datasets collected in a simulated environment and a real-world dataset captured using a LiDAR system mounted on a quadruped robot monitoring an industrial facility containing static, semi-static, and dynamic objects. Our method demonstrates superior performance in detecting changes in semi-static environments compared to existing methods.
Language-EXtended Indoor SLAM (LEXIS): A Versatile System for Real-time Visual Scene Understanding
Sep 26, 2023



Versatile and adaptive semantic understanding would enable autonomous systems to comprehend and interact with their surroundings. Existing fixed-class models limit the adaptability of indoor mobile and assistive autonomous systems. In this work, we introduce LEXIS, a real-time indoor Simultaneous Localization and Mapping (SLAM) system that harnesses the open-vocabulary nature of Large Language Models (LLMs) to create a unified approach to scene understanding and place recognition. The approach first builds a topological SLAM graph of the environment (using visual-inertial odometry) and embeds Contrastive Language-Image Pretraining (CLIP) features in the graph nodes. We use this representation for flexible room classification and segmentation, serving as a basis for room-centric place recognition. This allows loop closure searches to be directed towards semantically relevant places. Our proposed system is evaluated using both public, simulated data and real-world data, covering office and home environments. It successfully categorizes rooms with varying layouts and dimensions and outperforms the state-of-the-art (SOTA). For place recognition and trajectory estimation tasks we achieve equivalent performance to the SOTA, all also utilizing the same pre-trained model. Lastly, we demonstrate the system's potential for planning.
InstaLoc: One-shot Global Lidar Localisation in Indoor Environments through Instance Learning
May 16, 2023



Localization for autonomous robots in prior maps is crucial for their functionality. This paper offers a solution to this problem for indoor environments called InstaLoc, which operates on an individual lidar scan to localize it within a prior map. We draw on inspiration from how humans navigate and position themselves by recognizing the layout of distinctive objects and structures. Mimicking the human approach, InstaLoc identifies and matches object instances in the scene with those from a prior map. As far as we know, this is the first method to use panoptic segmentation directly inferring on 3D lidar scans for indoor localization. InstaLoc operates through two networks based on spatially sparse tensors to directly infer dense 3D lidar point clouds. The first network is a panoptic segmentation network that produces object instances and their semantic classes. The second smaller network produces a descriptor for each object instance. A consensus based matching algorithm then matches the instances to the prior map and estimates a six degrees of freedom (DoF) pose for the input cloud in the prior map. The significance of InstaLoc is that it has two efficient networks. It requires only one to two hours of training on a mobile GPU and runs in real-time at 1 Hz. Our method achieves between two and four times more detections when localizing, as compared to baseline methods, and achieves higher precision on these detections.
Hilti-Oxford Dataset: A Millimetre-Accurate Benchmark for Simultaneous Localization and Mapping
Aug 21, 2022



Simultaneous Localization and Mapping (SLAM) is being deployed in real-world applications, however many state-of-the-art solutions still struggle in many common scenarios. A key necessity in progressing SLAM research is the availability of high-quality datasets and fair and transparent benchmarking. To this end, we have created the Hilti-Oxford Dataset, to push state-of-the-art SLAM systems to their limits. The dataset has a variety of challenges ranging from sparse and regular construction sites to a 17th century neoclassical building with fine details and curved surfaces. To encourage multi-modal SLAM approaches, we designed a data collection platform featuring a lidar, five cameras, and an IMU (Inertial Measurement Unit). With the goal of benchmarking SLAM algorithms for tasks where accuracy and robustness are paramount, we implemented a novel ground truth collection method that enables our dataset to accurately measure SLAM pose errors with millimeter accuracy. To further ensure accuracy, the extrinsics of our platform were verified with a micrometer-accurate scanner, and temporal calibration was managed online using hardware time synchronization. The multi-modality and diversity of our dataset attracted a large field of academic and industrial researchers to enter the second edition of the Hilti SLAM challenge, which concluded in June 2022. The results of the challenge show that while the top three teams could achieve accuracy of 2cm or better for some sequences, the performance dropped off in more difficult sequences.
Team CERBERUS Wins the DARPA Subterranean Challenge: Technical Overview and Lessons Learned
Jul 11, 2022
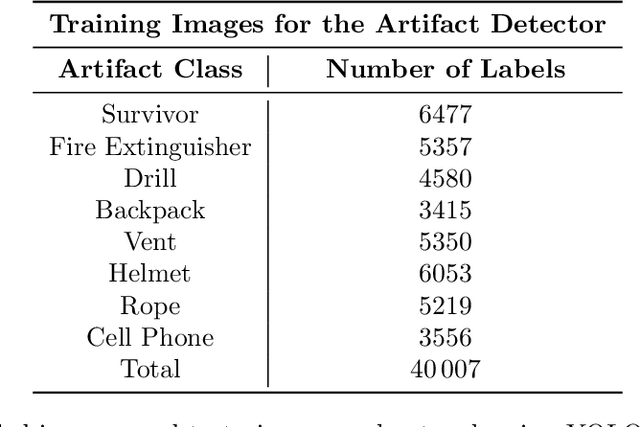
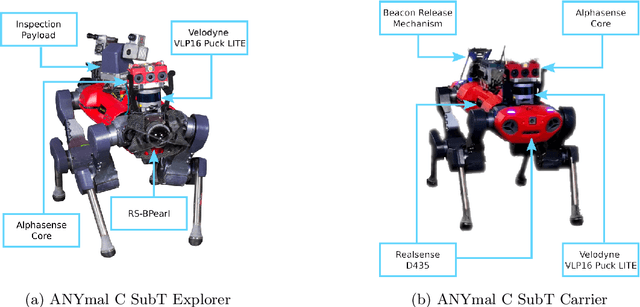
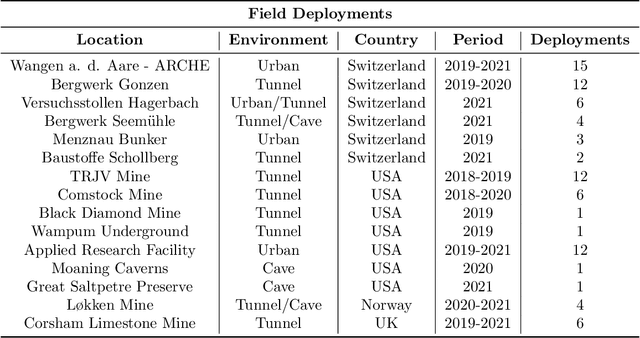
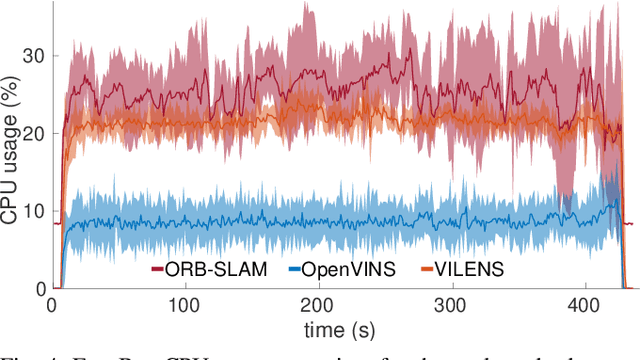
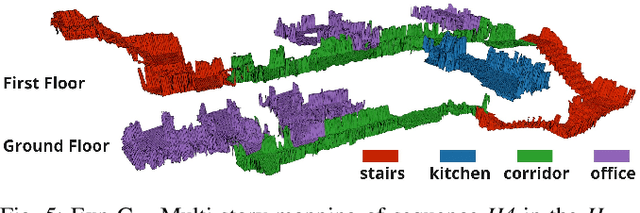
This article presents the CERBERUS robotic system-of-systems, which won the DARPA Subterranean Challenge Final Event in 2021. The Subterranean Challenge was organized by DARPA with the vision to facilitate the novel technologies necessary to reliably explore diverse underground environments despite the grueling challenges they present for robotic autonomy. Due to their geometric complexity, degraded perceptual conditions combined with lack of GPS support, austere navigation conditions, and denied communications, subterranean settings render autonomous operations particularly demanding. In response to this challenge, we developed the CERBERUS system which exploits the synergy of legged and flying robots, coupled with robust control especially for overcoming perilous terrain, multi-modal and multi-robot perception for localization and mapping in conditions of sensor degradation, and resilient autonomy through unified exploration path planning and local motion planning that reflects robot-specific limitations. Based on its ability to explore diverse underground environments and its high-level command and control by a single human supervisor, CERBERUS demonstrated efficient exploration, reliable detection of objects of interest, and accurate mapping. In this article, we report results from both the preliminary runs and the final Prize Round of the DARPA Subterranean Challenge, and discuss highlights and challenges faced, alongside lessons learned for the benefit of the community.