 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Freehand Ultrasound using Visual Inertial and Deep Inertial Odometry for Measuring Patellar Tracking
Apr 24, 2024Patellofemoral joint (PFJ) issues affect one in four people, with 20% experiencing chronic knee pain despite treatment. Poor outcomes and pain after knee replacement surgery are often linked to patellar mal-tracking. Traditional imaging methods like CT and MRI face challenges, including cost and metal artefacts, and there's currently no ideal way to observe joint motion without issues such as soft tissue artefacts or radiation exposure. A new system to monitor joint motion could significantly improve understanding of PFJ dynamics, aiding in better patient care and outcomes. Combining 2D ultrasound with motion tracking for 3D reconstruction of the joint using semantic segmentation and position registration can be a solution. However, the need for expensive external infrastructure to estimate the trajectories of the scanner remains the main limitation to implementing 3D bone reconstruction from handheld ultrasound scanning clinically. We proposed the Visual-Inertial Odometry (VIO) and the deep learning-based inertial-only odometry methods as alternatives to motion capture for tracking a handheld ultrasound scanner. The 3D reconstruction generated by these methods has demonstrated potential for assessing the PFJ and for further measurements from free-hand ultrasound scans. The results show that the VIO method performs as well as the motion capture method, with average reconstruction errors of 1.25 mm and 1.21 mm, respectively. The VIO method is the first infrastructure-free method for 3D reconstruction of bone from wireless handheld ultrasound scanning with an accuracy comparable to methods that require external infrastructure.
Deep IMU Bias Inference for Robust Visual-Inertial Odometry with Factor Graphs
Nov 08, 2022
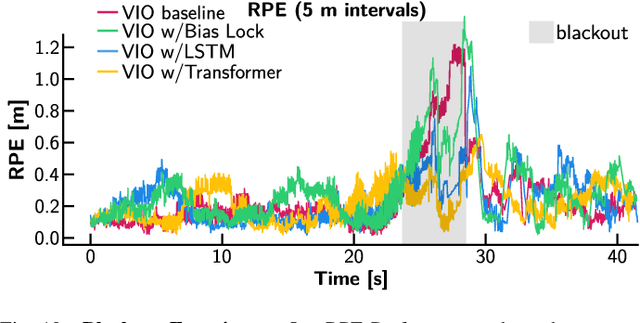
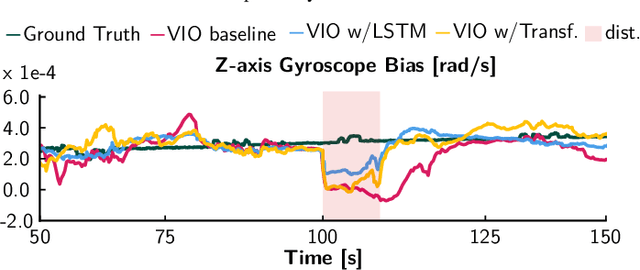
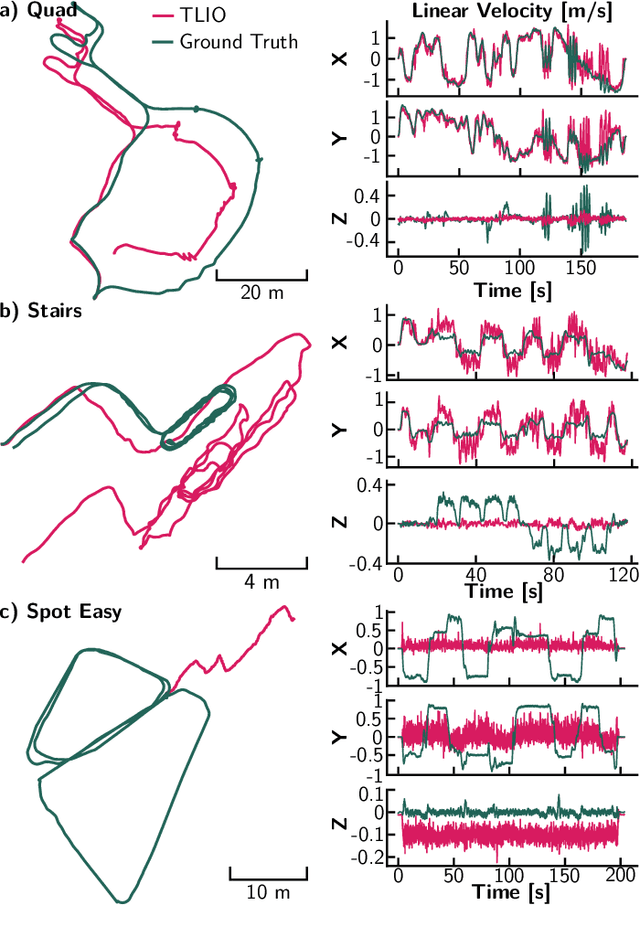
Visual Inertial Odometry (VIO) is one of the most established state estimation methods for mobile platforms. However, when visual tracking fails, VIO algorithms quickly diverge due to rapid error accumulation during inertial data integration. This error is typically modeled as a combination of additive Gaussian noise and a slowly changing bias which evolves as a random walk. In this work, we propose to train a neural network to learn the true bias evolution. We implement and compare two common sequential deep learning architectures: LSTMs and Transformers. Our approach follows from recent learning-based inertial estimators, but, instead of learning a motion model, we target IMU bias explicitly, which allows us to generalize to locomotion patterns unseen in training. We show that our proposed method improves state estimation in visually challenging situations across a wide range of motions by quadrupedal robots, walking humans, and drones. Our experiments show an average 15% reduction in drift rate, with much larger reductions when there is total vision failure. Importantly, we also demonstrate that models trained with one locomotion pattern (human walking) can be applied to another (quadruped robot trotting) without retraining.
Factor Graph Fusion of Raw GNSS Sensing with IMU and Lidar for Precise Robot Localization without a Base Station
Oct 05, 2022
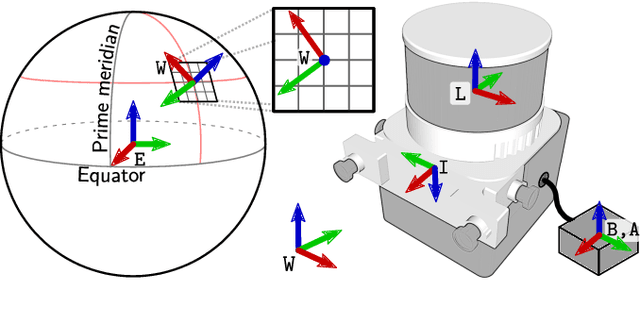
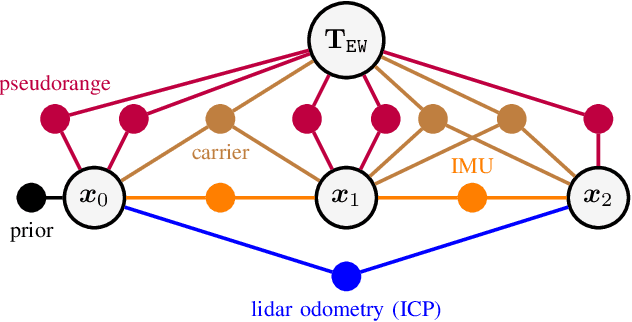

Accurate localization is a core component of a robot's navigation system. To this end, global navigation satellite systems (GNSS) can provide absolute measurements outdoors and, therefore, eliminate long-term drift. However, fusing GNSS data with other sensor data is not trivial, especially when a robot moves between areas with and without sky view. We propose a robust approach that tightly fuses raw GNSS receiver data with inertial measurements and, optionally, lidar observations for precise and smooth mobile robot localization. A factor graph with two types of GNSS factors is proposed. First, factors based on pseudoranges, which allow for global localization on Earth. Second, factors based on carrier phases, which enable highly accurate relative localization, which is useful when other sensing modalities are challenged. Unlike traditional differential GNSS, this approach does not require a connection to a base station. On a public urban driving dataset, our approach achieves accuracy comparable to a state-of-the-art algorithm that fuses visual inertial odometry with GNSS data -- despite our approach not using the camera, just inertial and GNSS data. We also demonstrate the robustness of our approach using data from a car and a quadruped robot moving in environments with little sky visibility, such as a forest. The accuracy in the global Earth frame is still 1-2 m, while the estimated trajectories are discontinuity-free and smooth. We also show how lidar measurements can be tightly integrated. We believe this is the first system that fuses raw GNSS observations (as opposed to fixes) with lidar.
Hilti-Oxford Dataset: A Millimetre-Accurate Benchmark for Simultaneous Localization and Mapping
Aug 21, 2022



Simultaneous Localization and Mapping (SLAM) is being deployed in real-world applications, however many state-of-the-art solutions still struggle in many common scenarios. A key necessity in progressing SLAM research is the availability of high-quality datasets and fair and transparent benchmarking. To this end, we have created the Hilti-Oxford Dataset, to push state-of-the-art SLAM systems to their limits. The dataset has a variety of challenges ranging from sparse and regular construction sites to a 17th century neoclassical building with fine details and curved surfaces. To encourage multi-modal SLAM approaches, we designed a data collection platform featuring a lidar, five cameras, and an IMU (Inertial Measurement Unit). With the goal of benchmarking SLAM algorithms for tasks where accuracy and robustness are paramount, we implemented a novel ground truth collection method that enables our dataset to accurately measure SLAM pose errors with millimeter accuracy. To further ensure accuracy, the extrinsics of our platform were verified with a micrometer-accurate scanner, and temporal calibration was managed online using hardware time synchronization. The multi-modality and diversity of our dataset attracted a large field of academic and industrial researchers to enter the second edition of the Hilti SLAM challenge, which concluded in June 2022. The results of the challenge show that while the top three teams could achieve accuracy of 2cm or better for some sequences, the performance dropped off in more difficult sequences.
Team CERBERUS Wins the DARPA Subterranean Challenge: Technical Overview and Lessons Learned
Jul 11, 2022
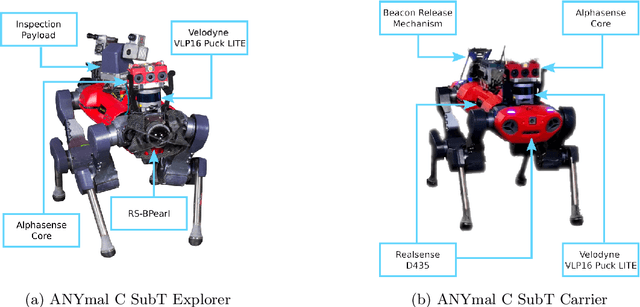
This article presents the CERBERUS robotic system-of-systems, which won the DARPA Subterranean Challenge Final Event in 2021. The Subterranean Challenge was organized by DARPA with the vision to facilitate the novel technologies necessary to reliably explore diverse underground environments despite the grueling challenges they present for robotic autonomy. Due to their geometric complexity, degraded perceptual conditions combined with lack of GPS support, austere navigation conditions, and denied communications, subterranean settings render autonomous operations particularly demanding. In response to this challenge, we developed the CERBERUS system which exploits the synergy of legged and flying robots, coupled with robust control especially for overcoming perilous terrain, multi-modal and multi-robot perception for localization and mapping in conditions of sensor degradation, and resilient autonomy through unified exploration path planning and local motion planning that reflects robot-specific limitations. Based on its ability to explore diverse underground environments and its high-level command and control by a single human supervisor, CERBERUS demonstrated efficient exploration, reliable detection of objects of interest, and accurate mapping. In this article, we report results from both the preliminary runs and the final Prize Round of the DARPA Subterranean Challenge, and discuss highlights and challenges faced, alongside lessons learned for the benefit of the community.
CERBERUS: Autonomous Legged and Aerial Robotic Exploration in the Tunnel and Urban Circuits of the DARPA Subterranean Challenge
Jan 18, 2022

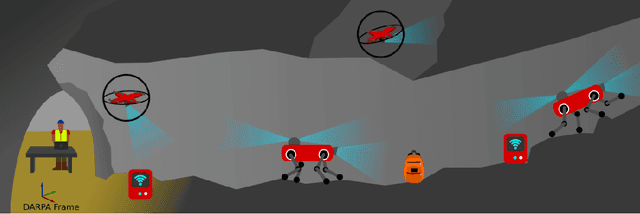

Autonomous exploration of subterranean environments constitutes a major frontier for robotic systems as underground settings present key challenges that can render robot autonomy hard to achieve. This has motivated the DARPA Subterranean Challenge, where teams of robots search for objects of interest in various underground environments. In response, the CERBERUS system-of-systems is presented as a unified strategy towards subterranean exploration using legged and flying robots. As primary robots, ANYmal quadruped systems are deployed considering their endurance and potential to traverse challenging terrain. For aerial robots, both conventional and collision-tolerant multirotors are utilized to explore spaces too narrow or otherwise unreachable by ground systems. Anticipating degraded sensing conditions, a complementary multi-modal sensor fusion approach utilizing camera, LiDAR, and inertial data for resilient robot pose estimation is proposed. Individual robot pose estimates are refined by a centralized multi-robot map optimization approach to improve the reported location accuracy of detected objects of interest in the DARPA-defined coordinate frame. Furthermore, a unified exploration path planning policy is presented to facilitate the autonomous operation of both legged and aerial robots in complex underground networks. Finally, to enable communication between the robots and the base station, CERBERUS utilizes a ground rover with a high-gain antenna and an optical fiber connection to the base station, alongside breadcrumbing of wireless nodes by our legged robots. We report results from the CERBERUS system-of-systems deployment at the DARPA Subterranean Challenge Tunnel and Urban Circuits, along with the current limitations and the lessons learned for the benefit of the community.
Multi-Camera LiDAR Inertial Extension to the Newer College Dataset
Dec 16, 2021



In this paper, we present a multi-camera LiDAR inertial dataset of 4.5km walking distance as an expansion to the Newer College Dataset. The global shutter multi-camera device is hardware synchronized with the IMU and the LiDAR. This dataset also provides six Degrees of Freedom (DoF) ground truth poses, at the LiDAR frequency of 10hz. Three data collections are described and example usage of multi-camera visual-inertial odometry is demonstrated. This expansion dataset contains small and narrow passages, large scale open spaces as well as vegetated areas to test localization and mapping systems. Furthermore, some sequences present challenging situations such as abrupt lighting change, textureless surfaces, and aggressive motion. The dataset is available at: https://ori-drs.github.io/newer-college-dataset
Learning Inertial Odometry for Dynamic Legged Robot State Estimation
Nov 01, 2021


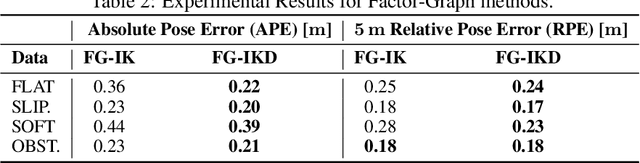
This paper introduces a novel proprioceptive state estimator for legged robots based on a learned displacement measurement from IMU data. Recent research in pedestrian tracking has shown that motion can be inferred from inertial data using convolutional neural networks. A learned inertial displacement measurement can improve state estimation in challenging scenarios where leg odometry is unreliable, such as slipping and compressible terrains. Our work learns to estimate a displacement measurement from IMU data which is then fused with traditional leg odometry. Our approach greatly reduces the drift of proprioceptive state estimation, which is critical for legged robots deployed in vision and lidar denied environments such as foggy sewers or dusty mines. We compared results from an EKF and an incremental fixed-lag factor graph estimator using data from several real robot experiments crossing challenging terrains. Our results show a reduction of relative pose error by 37% in challenging scenarios when compared to a traditional kinematic-inertial estimator without learned measurement. We also demonstrate a 22% reduction in error when used with vision systems in visually degraded environments such as an underground mine.
Balancing the Budget: Feature Selection and Tracking for Multi-Camera Visual-Inertial Odometry
Sep 13, 2021
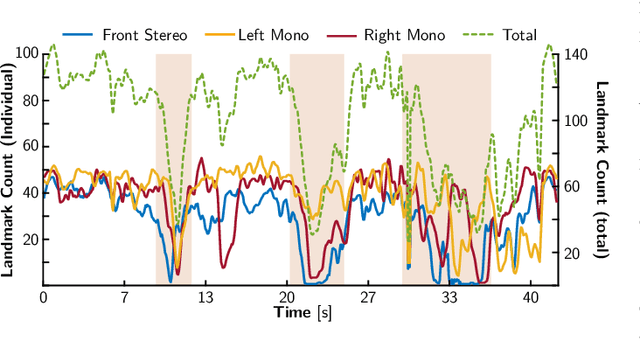
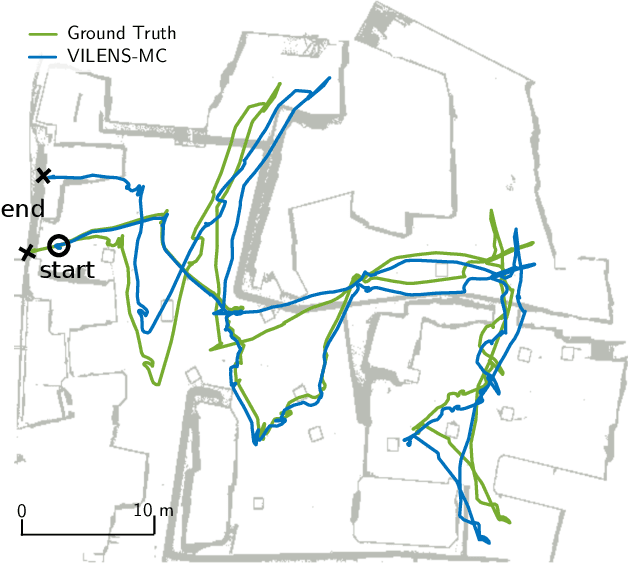
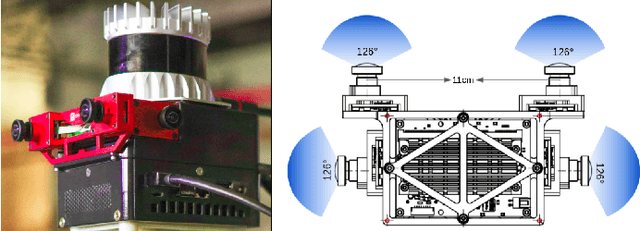
We present a multi-camera visual-inertial odometry system based on factor graph optimization which estimates motion by using all cameras simultaneously while retaining a fixed overall feature budget. We focus on motion tracking in challenging environments such as in narrow corridors and dark spaces with aggressive motions and abrupt lighting changes. These scenarios cause traditional monocular or stereo odometry to fail. While tracking motion across extra cameras should theoretically prevent failures, it causes additional complexity and computational burden. To overcome these challenges, we introduce two novel methods to improve multi-camera feature tracking. First, instead of tracking features separately in each camera, we track features continuously as they move from one camera to another. This increases accuracy and achieves a more compact factor graph representation. Second, we select a fixed budget of tracked features which are spread across the cameras to ensure that the limited computational budget is never exceeded. We have found that using a smaller set of informative features can maintain the same tracking accuracy while reducing back-end optimization time. Our proposed method was extensively tested using a hardware-synchronized device containing an IMU and four cameras (a front stereo pair and two lateral) in scenarios including an underground mine, large open spaces, and building interiors with narrow stairs and corridors. Compared to stereo-only state-of-the-art VIO methods, our approach reduces the drift rate (RPE) by up to 80% in translation and 39% in rotation.
Navigating by Touch: Haptic Monte Carlo Localization via Geometric Sensing and Terrain Classification
Aug 18, 2021
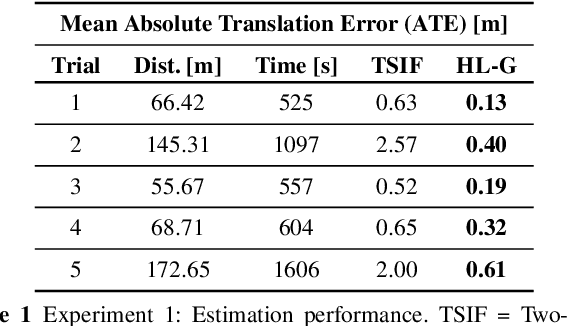
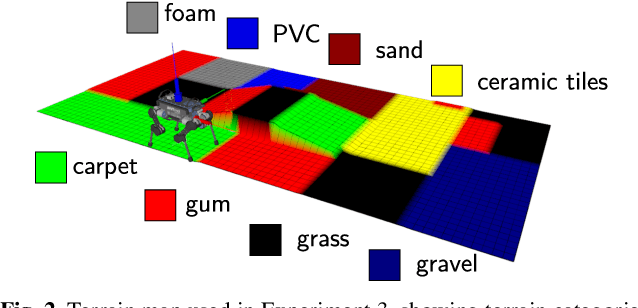
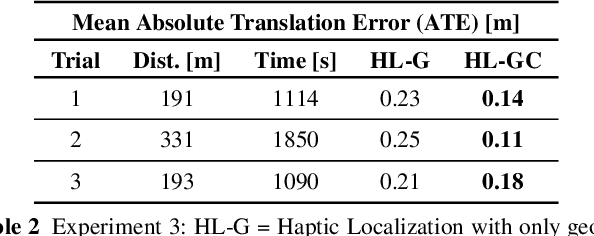
Legged robot navigation in extreme environments can hinder the use of cameras and laser scanners due to darkness, air obfuscation or sensor damage. In these conditions, proprioceptive sensing will continue to work reliably. In this paper, we propose a purely proprioceptive localization algorithm which fuses information from both geometry and terrain class, to localize a legged robot within a prior map. First, a terrain classifier computes the probability that a foot has stepped on a particular terrain class from sensed foot forces. Then, a Monte Carlo-based estimator fuses this terrain class probability with the geometric information of the foot contact points. Results are demonstrated showing this approach operating online and onboard a ANYmal B300 quadruped robot traversing a series of terrain courses with different geometries and terrain types over more than 1.2km. The method keeps the localization error below 20cm using only the information coming from the feet, IMU, and joints of the quadruped.