 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Estimation and Manipulation of Articulated Objects
Jan 04, 2026From refrigerators to kitchen drawers, humans interact with articulated objects effortlessly every day while completing household chores. For automating these tasks, service robots must be capable of manipulating arbitrary articulated objects. Recent deep learning methods have been shown to predict valuable priors on the affordance of articulated objects from vision. In contrast, many other works estimate object articulations by observing the articulation motion, but this requires the robot to already be capable of manipulating the object. In this article, we propose a novel approach combining these methods by using a factor graph for online estimation of articulation which fuses learned visual priors and proprioceptive sensing during interaction into an analytical model of articulation based on Screw Theory. With our method, a robotic system makes an initial prediction of articulation from vision before touching the object, and then quickly updates the estimate from kinematic and force sensing during manipulation. We evaluate our method extensively in both simulations and real-world robotic manipulation experiments. We demonstrate several closed-loop estimation and manipulation experiments in which the robot was capable of opening previously unseen drawers. In real hardware experiments, the robot achieved a 75% success rate for autonomous opening of unknown articulated objects.
ContactFusion: Stochastic Poisson Surface Maps from Visual and Contact Sensing
Mar 20, 2025Robust and precise robotic assembly entails insertion of constituent components. Insertion success is hindered when noise in scene understanding exceeds tolerance limits, especially when fabricated with tight tolerances. In this work, we propose ContactFusion which combines global mapping with local contact information, fusing point clouds with force sensing. Our method entails a Rejection Sampling based contact occupancy sensing procedure which estimates contact locations on the end-effector from Force/Torque sensing at the wrist. We demonstrate how to fuse contact with visual information into a Stochastic Poisson Surface Map (SPSMap) - a map representation that can be updated with the Stochastic Poisson Surface Reconstruction (SPSR) algorithm. We first validate the contact occupancy sensor in simulation and show its ability to detect the contact location on the robot from force sensing information. Then, we evaluate our method in a peg-in-hole task, demonstrating an improvement in the hole pose estimate with the fusion of the contact information with the SPSMap.
Learning Few-Shot Object Placement with Intra-Category Transfer
Nov 05, 2024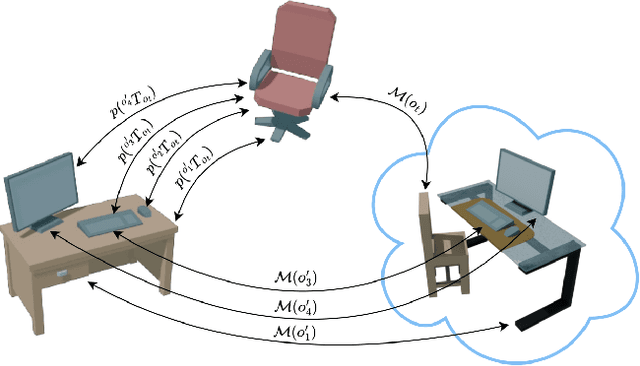
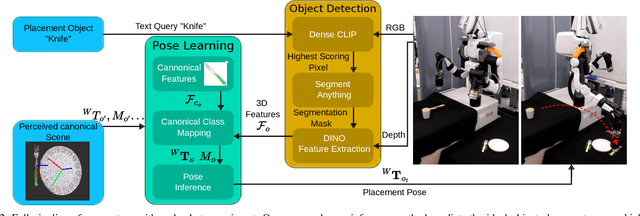
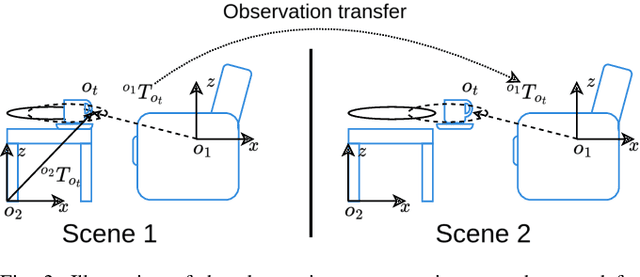
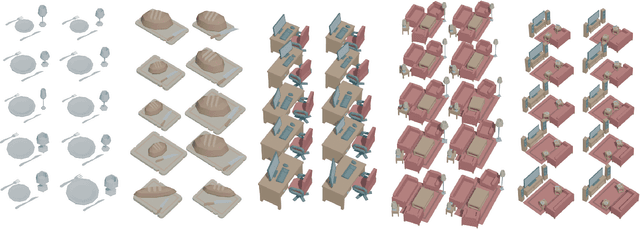
Efficient learning from demonstration for long-horizon tasks remains an open challenge in robotics. While significant effort has been directed toward learning trajectories, a recent resurgence of object-centric approaches has demonstrated improved sample efficiency, enabling transferable robotic skills. Such approaches model tasks as a sequence of object poses over time. In this work, we propose a scheme for transferring observed object arrangements to novel object instances by learning these arrangements on canonical class frames. We then employ this scheme to enable a simple yet effective approach for training models from as few as five demonstrations to predict arrangements of a wide range of objects including tableware, cutlery, furniture, and desk spaces. We propose a method for optimizing the learned models to enables efficient learning of tasks such as setting a table or tidying up an office with intra-category transfer, even in the presence of distractors. We present extensive experimental results in simulation and on a real robotic system for table setting which, based on human evaluations, scored 73.3% compared to a human baseline. We make the code and trained models publicly available at http://oplict.cs.uni-freiburg.de.
3D Freehand Ultrasound using Visual Inertial and Deep Inertial Odometry for Measuring Patellar Tracking
Apr 24, 2024Patellofemoral joint (PFJ) issues affect one in four people, with 20% experiencing chronic knee pain despite treatment. Poor outcomes and pain after knee replacement surgery are often linked to patellar mal-tracking. Traditional imaging methods like CT and MRI face challenges, including cost and metal artefacts, and there's currently no ideal way to observe joint motion without issues such as soft tissue artefacts or radiation exposure. A new system to monitor joint motion could significantly improve understanding of PFJ dynamics, aiding in better patient care and outcomes. Combining 2D ultrasound with motion tracking for 3D reconstruction of the joint using semantic segmentation and position registration can be a solution. However, the need for expensive external infrastructure to estimate the trajectories of the scanner remains the main limitation to implementing 3D bone reconstruction from handheld ultrasound scanning clinically. We proposed the Visual-Inertial Odometry (VIO) and the deep learning-based inertial-only odometry methods as alternatives to motion capture for tracking a handheld ultrasound scanner. The 3D reconstruction generated by these methods has demonstrated potential for assessing the PFJ and for further measurements from free-hand ultrasound scans. The results show that the VIO method performs as well as the motion capture method, with average reconstruction errors of 1.25 mm and 1.21 mm, respectively. The VIO method is the first infrastructure-free method for 3D reconstruction of bone from wireless handheld ultrasound scanning with an accuracy comparable to methods that require external infrastructure.
Online Estimation of Articulated Objects with Factor Graphs using Vision and Proprioceptive Sensing
Sep 28, 2023From dishwashers to cabinets, humans interact with articulated objects every day, and for a robot to assist in common manipulation tasks, it must learn a representation of articulation. Recent deep learning learning methods can provide powerful vision-based priors on the affordance of articulated objects from previous, possibly simulated, experiences. In contrast, many works estimate articulation by observing the object in motion, requiring the robot to already be interacting with the object. In this work, we propose to use the best of both worlds by introducing an online estimation method that merges vision-based affordance predictions from a neural network with interactive kinematic sensing in an analytical model. Our work has the benefit of using vision to predict an articulation model before touching the object, while also being able to update the model quickly from kinematic sensing during the interaction. In this paper, we implement a full system using shared autonomy for robotic opening of articulated objects, in particular objects in which the articulation is not apparent from vision alone. We implemented our system on a real robot and performed several autonomous closed-loop experiments in which the robot had to open a door with unknown joint while estimating the articulation online. Our system achieved an 80% success rate for autonomous opening of unknown articulated objects.
Deep IMU Bias Inference for Robust Visual-Inertial Odometry with Factor Graphs
Nov 08, 2022
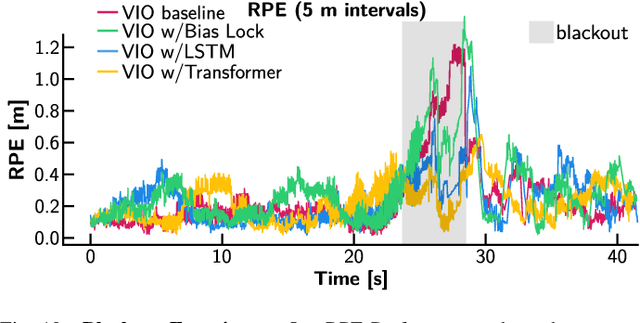
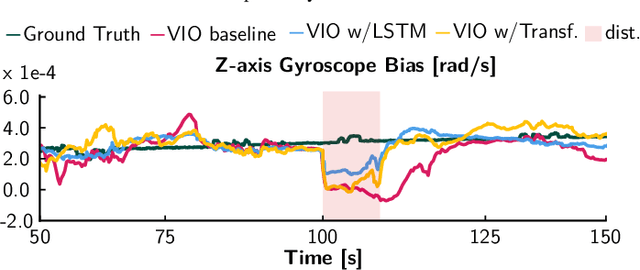
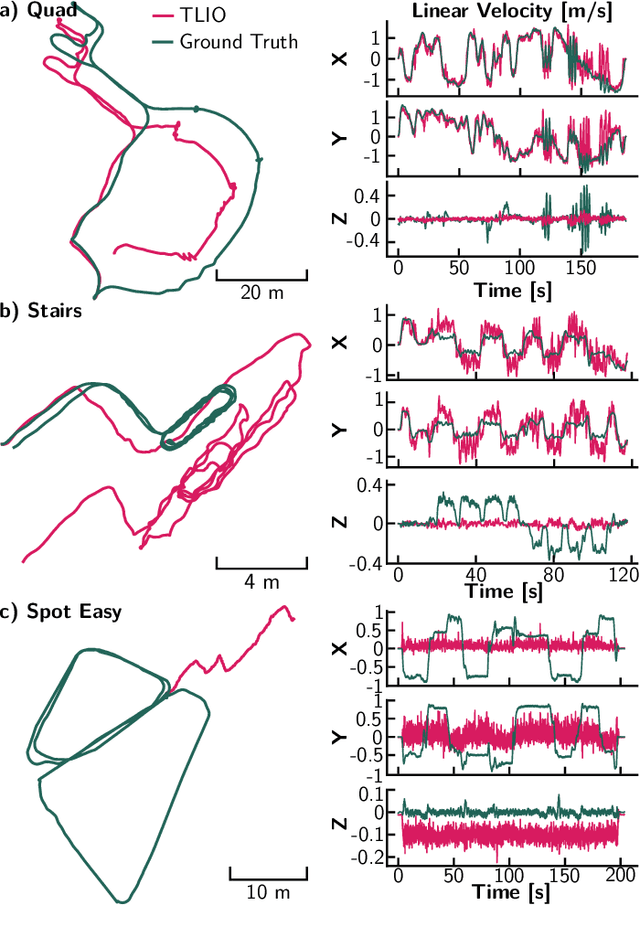
Visual Inertial Odometry (VIO) is one of the most established state estimation methods for mobile platforms. However, when visual tracking fails, VIO algorithms quickly diverge due to rapid error accumulation during inertial data integration. This error is typically modeled as a combination of additive Gaussian noise and a slowly changing bias which evolves as a random walk. In this work, we propose to train a neural network to learn the true bias evolution. We implement and compare two common sequential deep learning architectures: LSTMs and Transformers. Our approach follows from recent learning-based inertial estimators, but, instead of learning a motion model, we target IMU bias explicitly, which allows us to generalize to locomotion patterns unseen in training. We show that our proposed method improves state estimation in visually challenging situations across a wide range of motions by quadrupedal robots, walking humans, and drones. Our experiments show an average 15% reduction in drift rate, with much larger reductions when there is total vision failure. Importantly, we also demonstrate that models trained with one locomotion pattern (human walking) can be applied to another (quadruped robot trotting) without retraining.
Team CERBERUS Wins the DARPA Subterranean Challenge: Technical Overview and Lessons Learned
Jul 11, 2022
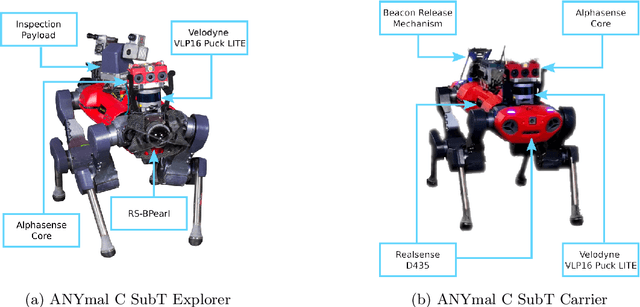
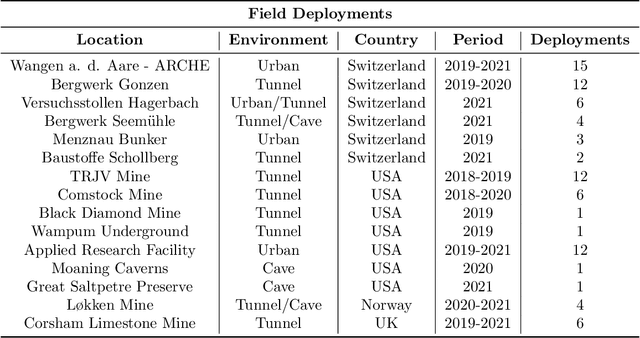
This article presents the CERBERUS robotic system-of-systems, which won the DARPA Subterranean Challenge Final Event in 2021. The Subterranean Challenge was organized by DARPA with the vision to facilitate the novel technologies necessary to reliably explore diverse underground environments despite the grueling challenges they present for robotic autonomy. Due to their geometric complexity, degraded perceptual conditions combined with lack of GPS support, austere navigation conditions, and denied communications, subterranean settings render autonomous operations particularly demanding. In response to this challenge, we developed the CERBERUS system which exploits the synergy of legged and flying robots, coupled with robust control especially for overcoming perilous terrain, multi-modal and multi-robot perception for localization and mapping in conditions of sensor degradation, and resilient autonomy through unified exploration path planning and local motion planning that reflects robot-specific limitations. Based on its ability to explore diverse underground environments and its high-level command and control by a single human supervisor, CERBERUS demonstrated efficient exploration, reliable detection of objects of interest, and accurate mapping. In this article, we report results from both the preliminary runs and the final Prize Round of the DARPA Subterranean Challenge, and discuss highlights and challenges faced, alongside lessons learned for the benefit of the community.
CERBERUS: Autonomous Legged and Aerial Robotic Exploration in the Tunnel and Urban Circuits of the DARPA Subterranean Challenge
Jan 18, 2022

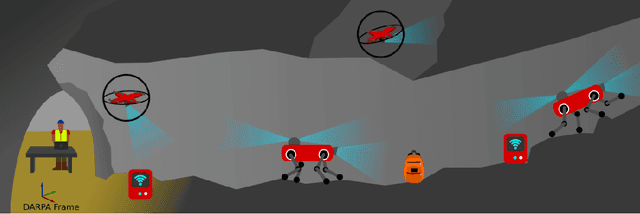

Autonomous exploration of subterranean environments constitutes a major frontier for robotic systems as underground settings present key challenges that can render robot autonomy hard to achieve. This has motivated the DARPA Subterranean Challenge, where teams of robots search for objects of interest in various underground environments. In response, the CERBERUS system-of-systems is presented as a unified strategy towards subterranean exploration using legged and flying robots. As primary robots, ANYmal quadruped systems are deployed considering their endurance and potential to traverse challenging terrain. For aerial robots, both conventional and collision-tolerant multirotors are utilized to explore spaces too narrow or otherwise unreachable by ground systems. Anticipating degraded sensing conditions, a complementary multi-modal sensor fusion approach utilizing camera, LiDAR, and inertial data for resilient robot pose estimation is proposed. Individual robot pose estimates are refined by a centralized multi-robot map optimization approach to improve the reported location accuracy of detected objects of interest in the DARPA-defined coordinate frame. Furthermore, a unified exploration path planning policy is presented to facilitate the autonomous operation of both legged and aerial robots in complex underground networks. Finally, to enable communication between the robots and the base station, CERBERUS utilizes a ground rover with a high-gain antenna and an optical fiber connection to the base station, alongside breadcrumbing of wireless nodes by our legged robots. We report results from the CERBERUS system-of-systems deployment at the DARPA Subterranean Challenge Tunnel and Urban Circuits, along with the current limitations and the lessons learned for the benefit of the community.
Learning Inertial Odometry for Dynamic Legged Robot State Estimation
Nov 01, 2021


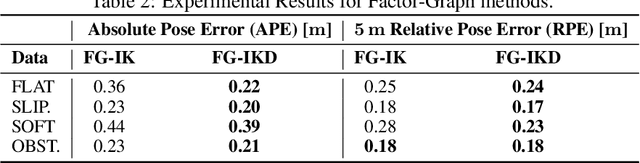
This paper introduces a novel proprioceptive state estimator for legged robots based on a learned displacement measurement from IMU data. Recent research in pedestrian tracking has shown that motion can be inferred from inertial data using convolutional neural networks. A learned inertial displacement measurement can improve state estimation in challenging scenarios where leg odometry is unreliable, such as slipping and compressible terrains. Our work learns to estimate a displacement measurement from IMU data which is then fused with traditional leg odometry. Our approach greatly reduces the drift of proprioceptive state estimation, which is critical for legged robots deployed in vision and lidar denied environments such as foggy sewers or dusty mines. We compared results from an EKF and an incremental fixed-lag factor graph estimator using data from several real robot experiments crossing challenging terrains. Our results show a reduction of relative pose error by 37% in challenging scenarios when compared to a traditional kinematic-inertial estimator without learned measurement. We also demonstrate a 22% reduction in error when used with vision systems in visually degraded environments such as an underground mine.
Navigating by Touch: Haptic Monte Carlo Localization via Geometric Sensing and Terrain Classification
Aug 18, 2021
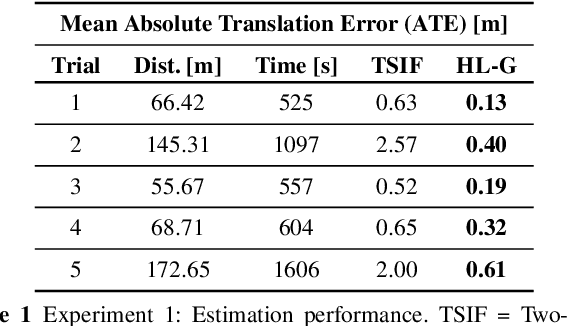
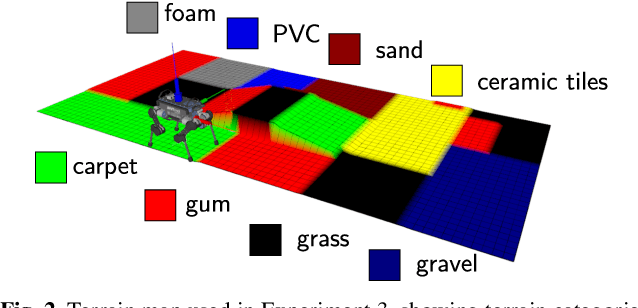
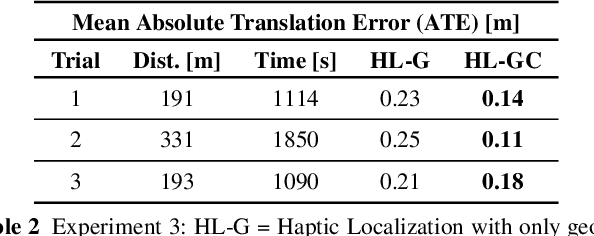
Legged robot navigation in extreme environments can hinder the use of cameras and laser scanners due to darkness, air obfuscation or sensor damage. In these conditions, proprioceptive sensing will continue to work reliably. In this paper, we propose a purely proprioceptive localization algorithm which fuses information from both geometry and terrain class, to localize a legged robot within a prior map. First, a terrain classifier computes the probability that a foot has stepped on a particular terrain class from sensed foot forces. Then, a Monte Carlo-based estimator fuses this terrain class probability with the geometric information of the foot contact points. Results are demonstrated showing this approach operating online and onboard a ANYmal B300 quadruped robot traversing a series of terrain courses with different geometries and terrain types over more than 1.2km. The method keeps the localization error below 20cm using only the information coming from the feet, IMU, and joints of the quadruped.