 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolmoB0T: Large-Scale Simulation Enables Zero-Shot Manipulation
Mar 17, 2026A prevailing view in robot learning is that simulation alone is not enough; effective sim-to-real transfer is widely believed to require at least some real-world data collection or task-specific fine-tuning to bridge the gap between simulated and physical environments. We challenge that assumption. With sufficiently large-scale and diverse simulated synthetic training data, we show that zero-shot transfer to the real world is not only possible, but effective for both static and mobile manipulation. We introduce MolmoBot-Engine, a fully open-source pipeline for procedural data generation across robots, tasks, and diverse simulated environments in MolmoSpaces. With it, we release MolmoBot-Data, a dataset of 1.8 million expert trajectories for articulated object manipulation and pick-and-place tasks. We train three policy classes: MolmoBot, a Molmo2-based multi-frame vision-language model with a flow-matching action head; MolmoBot-Pi0, which replicates the $π_0$ architecture to enable direct comparison; and MolmoBot-SPOC, a lightweight policy suitable for edge deployment and amenable to RL fine-tuning. We evaluate on two robotic platforms: the Franka FR3 for tabletop manipulation tasks and the Rainbow Robotics RB-Y1 mobile manipulator for door opening, drawer manipulation, cabinet interaction, and mobile pick-and-place. Without any real-world fine-tuning, our policies achieve zero-shot transfer to unseen objects and environments. On tabletop pick-and-place, MolmoBot achieves a success rate of 79.2% in real world evaluations across 4 settings, outperforming $π_{0.5}$ at 39.2%. Our results demonstrate that procedural environment generation combined with diverse articulated assets can produce robust manipulation policies that generalize broadly to the real world. Technical Blog: https://allenai.org/blog/molmobot-robot-manipulation
MolmoSpaces: A Large-Scale Open Ecosystem for Robot Navigation and Manipulation
Feb 11, 2026Deploying robots at scale demands robustness to the long tail of everyday situations. The countless variations in scene layout, object geometry, and task specifications that characterize real environments are vast and underrepresented in existing robot benchmarks. Measuring this level of generalization requires infrastructure at a scale and diversity that physical evaluation alone cannot provide. We introduce MolmoSpaces, a fully open ecosystem to support large-scale benchmarking of robot policies. MolmoSpaces consists of over 230k diverse indoor environments, ranging from handcrafted household scenes to procedurally generated multiroom houses, populated with 130k richly annotated object assets, including 48k manipulable objects with 42M stable grasps. Crucially, these environments are simulator-agnostic, supporting popular options such as MuJoCo, Isaac, and ManiSkill. The ecosystem supports the full spectrum of embodied tasks: static and mobile manipulation, navigation, and multiroom long-horizon tasks requiring coordinated perception, planning, and interaction across entire indoor environments. We also design MolmoSpaces-Bench, a benchmark suite of 8 tasks in which robots interact with our diverse scenes and richly annotated objects. Our experiments show MolmoSpaces-Bench exhibits strong sim-to-real correlation (R = 0.96, \r{ho} = 0.98), confirm newer and stronger zero-shot policies outperform earlier versions in our benchmarks, and identify key sensitivities to prompt phrasing, initial joint positions, and camera occlusion. Through MolmoSpaces and its open-source assets and tooling, we provide a foundation for scalable data generation, policy training, and benchmark creation for robot learning research.
cVLA: Towards Efficient Camera-Space VLAs
Jul 02, 2025Vision-Language-Action (VLA) models offer a compelling framework for tackling complex robotic manipulation tasks, but they are often expensive to train. In this paper, we propose a novel VLA approach that leverages the competitive performance of Vision Language Models (VLMs) on 2D images to directly infer robot end-effector poses in image frame coordinates. Unlike prior VLA models that output low-level controls, our model predicts trajectory waypoints, making it both more efficient to train and robot embodiment agnostic. Despite its lightweight design, our next-token prediction architecture effectively learns meaningful and executable robot trajectories. We further explore the underutilized potential of incorporating depth images, inference-time techniques such as decoding strategies, and demonstration-conditioned action generation. Our model is trained on a simulated dataset and exhibits strong sim-to-real transfer capabilities. We evaluate our approach using a combination of simulated and real data, demonstrating its effectiveness on a real robotic system.
When and How Does CLIP Enable Domain and Compositional Generalization?
Feb 13, 2025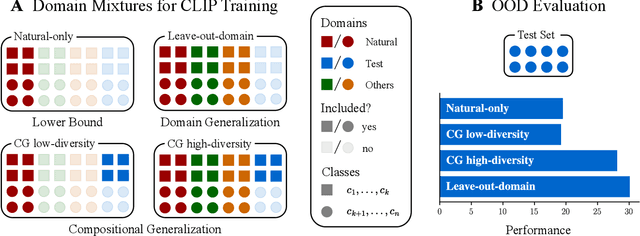

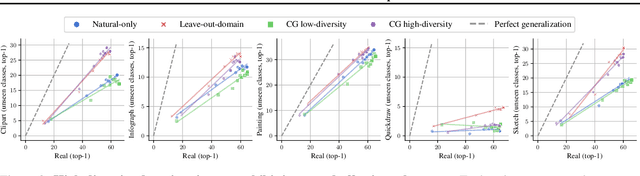

The remarkable generalization performance of contrastive vision-language models like CLIP is often attributed to the diversity of their training distributions. However, key questions remain unanswered: Can CLIP generalize to an entirely unseen domain when trained on a diverse mixture of domains (domain generalization)? Can it generalize to unseen classes within partially seen domains (compositional generalization)? What factors affect such generalization? To answer these questions, we trained CLIP models on systematically constructed training distributions with controlled domain diversity and object class exposure. Our experiments show that domain diversity is essential for both domain and compositional generalization, yet compositional generalization can be surprisingly weaker than domain generalization when the training distribution contains a suboptimal subset of the test domain. Through data-centric and mechanistic analyses, we find that successful generalization requires learning of shared representations already in intermediate layers and shared circuitry.
Learning Few-Shot Object Placement with Intra-Category Transfer
Nov 05, 2024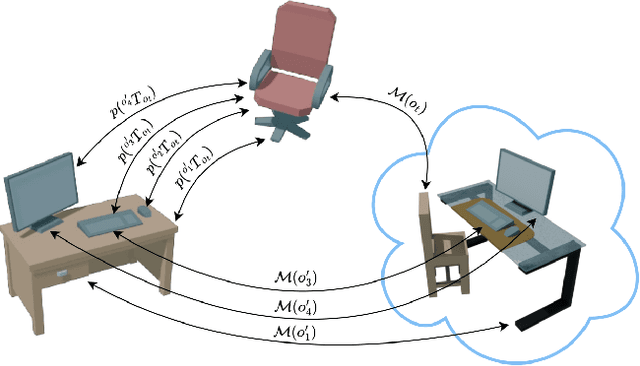
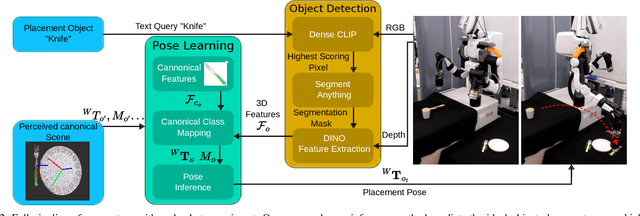
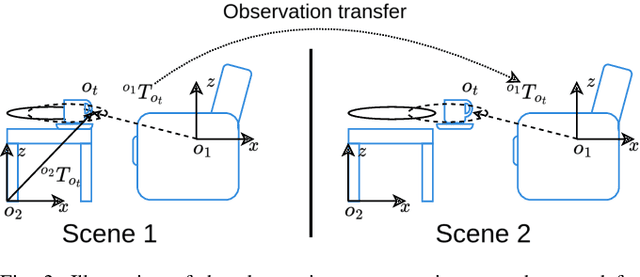
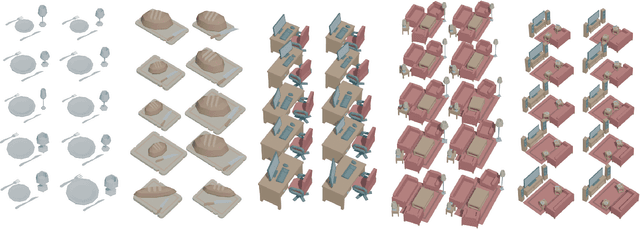
Efficient learning from demonstration for long-horizon tasks remains an open challenge in robotics. While significant effort has been directed toward learning trajectories, a recent resurgence of object-centric approaches has demonstrated improved sample efficiency, enabling transferable robotic skills. Such approaches model tasks as a sequence of object poses over time. In this work, we propose a scheme for transferring observed object arrangements to novel object instances by learning these arrangements on canonical class frames. We then employ this scheme to enable a simple yet effective approach for training models from as few as five demonstrations to predict arrangements of a wide range of objects including tableware, cutlery, furniture, and desk spaces. We propose a method for optimizing the learned models to enables efficient learning of tasks such as setting a table or tidying up an office with intra-category transfer, even in the presence of distractors. We present extensive experimental results in simulation and on a real robotic system for table setting which, based on human evaluations, scored 73.3% compared to a human baseline. We make the code and trained models publicly available at http://oplict.cs.uni-freiburg.de.
Learning Robotic Manipulation Policies from Point Clouds with Conditional Flow Matching
Sep 11, 2024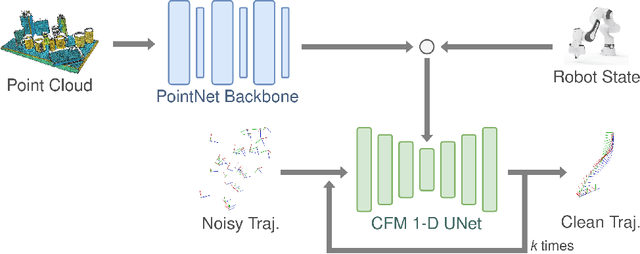



Learning from expert demonstrations is a promising approach for training robotic manipulation policies from limited data. However, imitation learning algorithms require a number of design choices ranging from the input modality, training objective, and 6-DoF end-effector pose representation. Diffusion-based methods have gained popularity as they enable predicting long-horizon trajectories and handle multimodal action distributions. Recently, Conditional Flow Matching (CFM) (or Rectified Flow) has been proposed as a more flexible generalization of diffusion models. In this paper, we investigate the application of CFM in the context of robotic policy learning and specifically study the interplay with the other design choices required to build an imitation learning algorithm. We show that CFM gives the best performance when combined with point cloud input observations. Additionally, we study the feasibility of a CFM formulation on the SO(3) manifold and evaluate its suitability with a simplified example. We perform extensive experiments on RLBench which demonstrate that our proposed PointFlowMatch approach achieves a state-of-the-art average success rate of 67.8% over eight tasks, double the performance of the next best method.
Concept Bottleneck Models Without Predefined Concepts
Jul 04, 2024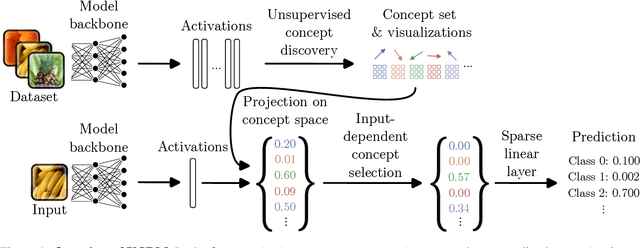

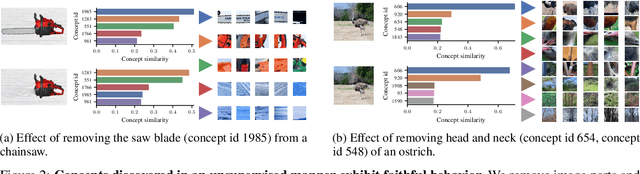

There has been considerable recent interest in interpretable concept-based models such as Concept Bottleneck Models (CBMs), which first predict human-interpretable concepts and then map them to output classes. To reduce reliance on human-annotated concepts, recent works have converted pretrained black-box models into interpretable CBMs post-hoc. However, these approaches predefine a set of concepts, assuming which concepts a black-box model encodes in its representations. In this work, we eliminate this assumption by leveraging unsupervised concept discovery to automatically extract concepts without human annotations or a predefined set of concepts. We further introduce an input-dependent concept selection mechanism that ensures only a small subset of concepts is used across all classes. We show that our approach improves downstream performance and narrows the performance gap to black-box models, while using significantly fewer concepts in the classification. Finally, we demonstrate how large vision-language models can intervene on the final model weights to correct model errors.
Two Effects, One Trigger: On the Modality Gap, Object Bias, and Information Imbalance in Contrastive Vision-Language Representation Learning
Apr 11, 2024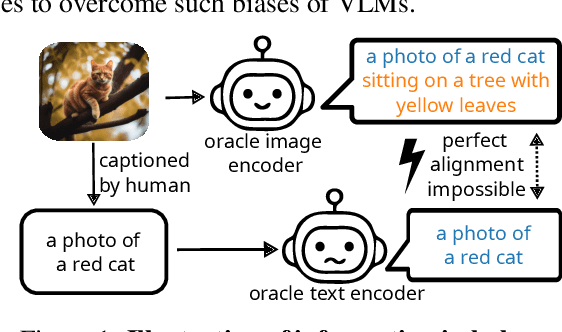



Contrastive vision-language models like CLIP have gained popularity for their versatile applicable learned representations in various downstream tasks. Despite their successes in some tasks, like zero-shot image recognition, they also perform surprisingly poor on other tasks, like attribute detection. Previous work has attributed these challenges to the modality gap, a separation of image and text in the shared representation space, and a bias towards objects over other factors, such as attributes. In this work we investigate both phenomena. We find that only a few embedding dimensions drive the modality gap. Further, we propose a measure for object bias and find that object bias does not lead to worse performance on other concepts, such as attributes. But what leads to the emergence of the modality gap and object bias? To answer this question we carefully designed an experimental setting which allows us to control the amount of shared information between the modalities. This revealed that the driving factor behind both, the modality gap and the object bias, is the information imbalance between images and captions.
DITTO: Demonstration Imitation by Trajectory Transformation
Mar 22, 2024



Teaching robots new skills quickly and conveniently is crucial for the broader adoption of robotic systems. In this work, we address the problem of one-shot imitation from a single human demonstration, given by an RGB-D video recording through a two-stage process. In the first stage which is offline, we extract the trajectory of the demonstration. This entails segmenting manipulated objects and determining their relative motion in relation to secondary objects such as containers. Subsequently, in the live online trajectory generation stage, we first \mbox{re-detect} all objects, then we warp the demonstration trajectory to the current scene, and finally, we trace the trajectory with the robot. To complete these steps, our method makes leverages several ancillary models, including those for segmentation, relative object pose estimation, and grasp prediction. We systematically evaluate different combinations of correspondence and re-detection methods to validate our design decision across a diverse range of tasks. Specifically, we collect demonstrations of ten different tasks including pick-and-place tasks as well as articulated object manipulation. Finally, we perform extensive evaluations on a real robot system to demonstrate the effectiveness and utility of our approach in real-world scenarios. We make the code publicly available at http://ditto.cs.uni-freiburg.de.
Latent Diffusion Counterfactual Explanations
Oct 10, 2023



Counterfactual explanations have emerged as a promising method for elucidating the behavior of opaque black-box models. Recently, several works leveraged pixel-space diffusion models for counterfactual generation. To handle noisy, adversarial gradients during counterfactual generation -- causing unrealistic artifacts or mere adversarial perturbations -- they required either auxiliary adversarially robust models or computationally intensive guidance schemes. However, such requirements limit their applicability, e.g., in scenarios with restricted access to the model's training data. To address these limitations, we introduce Latent Diffusion Counterfactual Explanations (LDCE). LDCE harnesses the capabilities of recent class- or text-conditional foundation latent diffusion models to expedite counterfactual generation and focus on the important, semantic parts of the data. Furthermore, we propose a novel consensus guidance mechanism to filter out noisy, adversarial gradients that are misaligned with the diffusion model's implicit classifier. We demonstrate the versatility of LDCE across a wide spectrum of models trained on diverse datasets with different learning paradigms. Finally, we showcase how LDCE can provide insights into model errors, enhancing our understanding of black-box model behavior.