 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulated 3D Scene Graphs for Open-World Mobile Manipulation
Feb 18, 2026Semantics has enabled 3D scene understanding and affordance-driven object interaction. However, robots operating in real-world environments face a critical limitation: they cannot anticipate how objects move. Long-horizon mobile manipulation requires closing the gap between semantics, geometry, and kinematics. In this work, we present MoMa-SG, a novel framework for building semantic-kinematic 3D scene graphs of articulated scenes containing a myriad of interactable objects. Given RGB-D sequences containing multiple object articulations, we temporally segment object interactions and infer object motion using occlusion-robust point tracking. We then lift point trajectories into 3D and estimate articulation models using a novel unified twist estimation formulation that robustly estimates revolute and prismatic joint parameters in a single optimization pass. Next, we associate objects with estimated articulations and detect contained objects by reasoning over parent-child relations at identified opening states. We also introduce the novel Arti4D-Semantic dataset, which uniquely combines hierarchical object semantics including parent-child relation labels with object axis annotations across 62 in-the-wild RGB-D sequences containing 600 object interactions and three distinct observation paradigms. We extensively evaluate the performance of MoMa-SG on two datasets and ablate key design choices of our approach. In addition, real-world experiments on both a quadruped and a mobile manipulator demonstrate that our semantic-kinematic scene graphs enable robust manipulation of articulated objects in everyday home environments. We provide code and data at: https://momasg.cs.uni-freiburg.de.
MORE: Mobile Manipulation Rearrangement Through Grounded Language Reasoning
May 05, 2025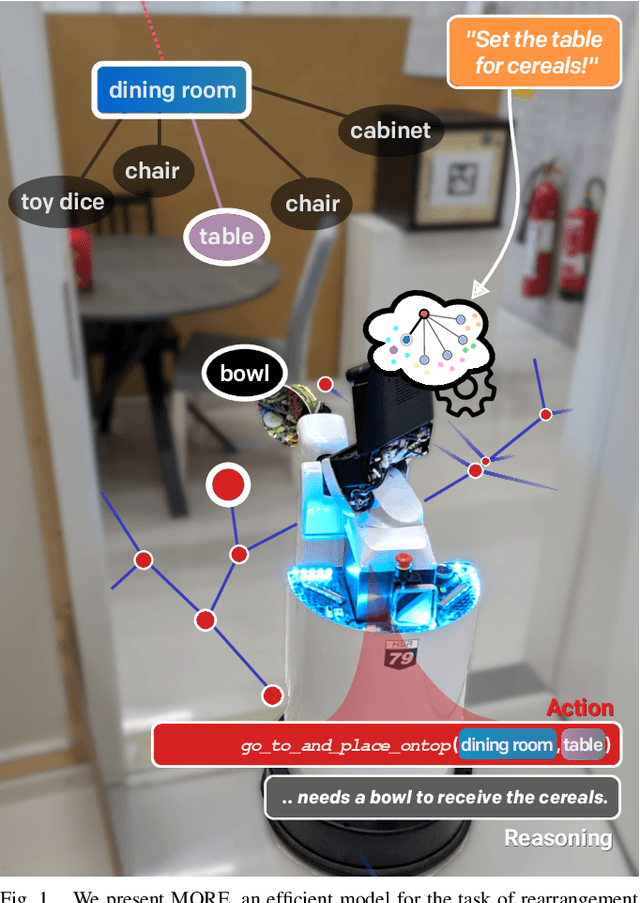
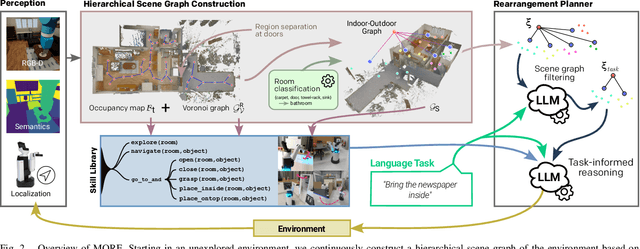
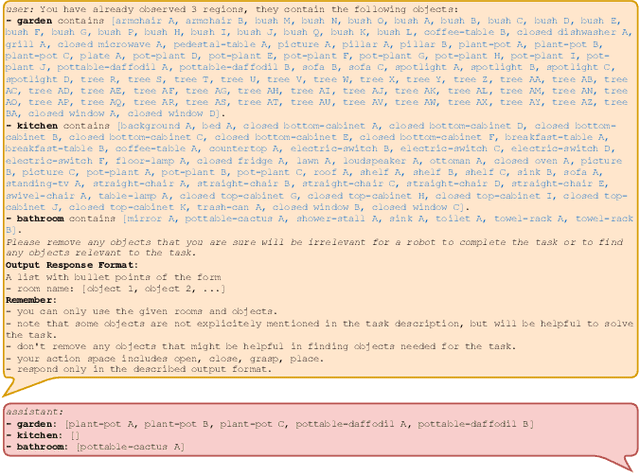
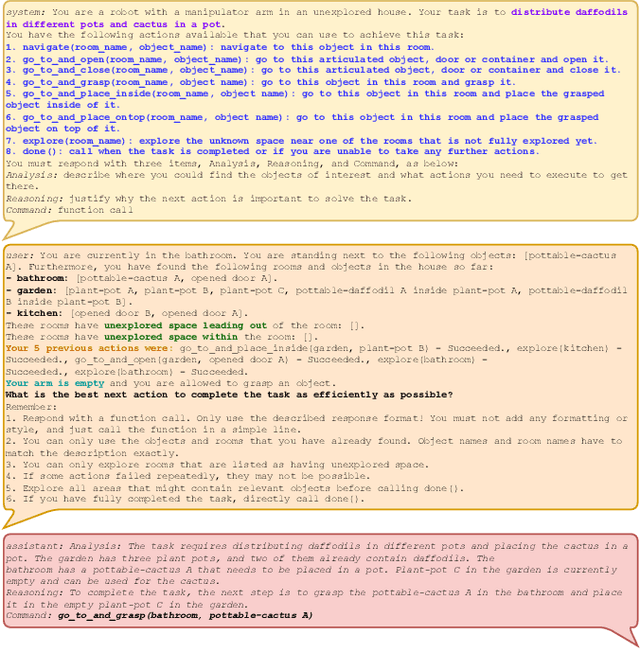
Autonomous long-horizon mobile manipulation encompasses a multitude of challenges, including scene dynamics, unexplored areas, and error recovery. Recent works have leveraged foundation models for scene-level robotic reasoning and planning. However, the performance of these methods degrades when dealing with a large number of objects and large-scale environments. To address these limitations, we propose MORE, a novel approach for enhancing the capabilities of language models to solve zero-shot mobile manipulation planning for rearrangement tasks. MORE leverages scene graphs to represent environments, incorporates instance differentiation, and introduces an active filtering scheme that extracts task-relevant subgraphs of object and region instances. These steps yield a bounded planning problem, effectively mitigating hallucinations and improving reliability. Additionally, we introduce several enhancements that enable planning across both indoor and outdoor environments. We evaluate MORE on 81 diverse rearrangement tasks from the BEHAVIOR-1K benchmark, where it becomes the first approach to successfully solve a significant share of the benchmark, outperforming recent foundation model-based approaches. Furthermore, we demonstrate the capabilities of our approach in several complex real-world tasks, mimicking everyday activities. We make the code publicly available at https://more-model.cs.uni-freiburg.de.
Task-Driven Co-Design of Mobile Manipulators
Dec 21, 2024Recent interest in mobile manipulation has resulted in a wide range of new robot designs. A large family of these designs focuses on modular platforms that combine existing mobile bases with static manipulator arms. They combine these modules by mounting the arm in a tabletop configuration. However, the operating workspaces and heights for common mobile manipulation tasks, such as opening articulated objects, significantly differ from tabletop manipulation tasks. As a result, these standard arm mounting configurations can result in kinematics with restricted joint ranges and motions. To address these problems, we present the first Concurrent Design approach for mobile manipulators to optimize key arm-mounting parameters. Our approach directly targets task performance across representative household tasks by training a powerful multitask-capable reinforcement learning policy in an inner loop while optimizing over a distribution of design configurations guided by Bayesian Optimization and HyperBand (BOHB) in an outer loop. This results in novel designs that significantly improve performance across both seen and unseen test tasks, and outperform designs generated by heuristic-based performance indices that are cheaper to evaluate but only weakly correlated with the motions of interest. We evaluate the physical feasibility of the resulting designs and show that they are practical and remain modular, affordable, and compatible with existing commercial components. We open-source the approach and generated designs to facilitate further improvements of these platforms.
Learning Robotic Manipulation Policies from Point Clouds with Conditional Flow Matching
Sep 11, 2024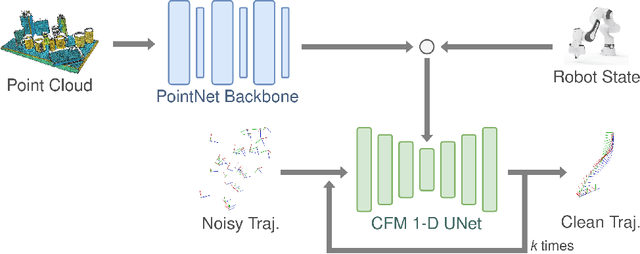



Learning from expert demonstrations is a promising approach for training robotic manipulation policies from limited data. However, imitation learning algorithms require a number of design choices ranging from the input modality, training objective, and 6-DoF end-effector pose representation. Diffusion-based methods have gained popularity as they enable predicting long-horizon trajectories and handle multimodal action distributions. Recently, Conditional Flow Matching (CFM) (or Rectified Flow) has been proposed as a more flexible generalization of diffusion models. In this paper, we investigate the application of CFM in the context of robotic policy learning and specifically study the interplay with the other design choices required to build an imitation learning algorithm. We show that CFM gives the best performance when combined with point cloud input observations. Additionally, we study the feasibility of a CFM formulation on the SO(3) manifold and evaluate its suitability with a simplified example. We perform extensive experiments on RLBench which demonstrate that our proposed PointFlowMatch approach achieves a state-of-the-art average success rate of 67.8% over eight tasks, double the performance of the next best method.
Perception Matters: Enhancing Embodied AI with Uncertainty-Aware Semantic Segmentation
Aug 05, 2024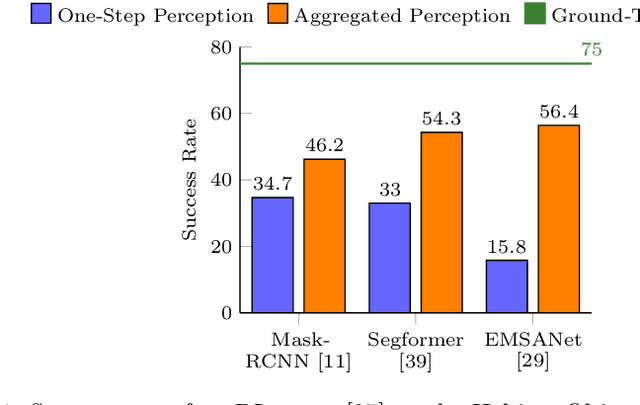

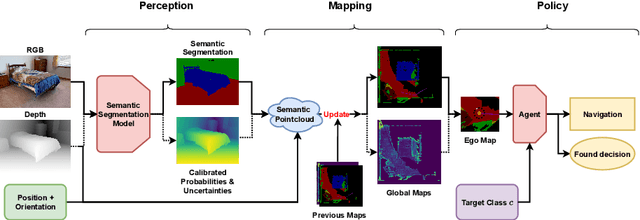
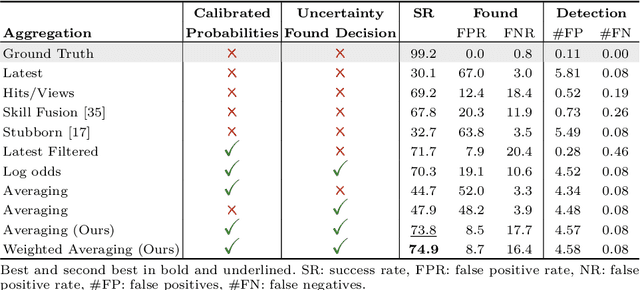
Embodied AI has made significant progress acting in unexplored environments. However, tasks such as object search have largely focused on efficient policy learning. In this work, we identify several gaps in current search methods: They largely focus on dated perception models, neglect temporal aggregation, and transfer from ground truth directly to noisy perception at test time, without accounting for the resulting overconfidence in the perceived state. We address the identified problems through calibrated perception probabilities and uncertainty across aggregation and found decisions, thereby adapting the models for sequential tasks. The resulting methods can be directly integrated with pretrained models across a wide family of existing search approaches at no additional training cost. We perform extensive evaluations of aggregation methods across both different semantic perception models and policies, confirming the importance of calibrated uncertainties in both the aggregation and found decisions. We make the code and trained models available at http://semantic-search.cs.uni-freiburg.de.
The Art of Imitation: Learning Long-Horizon Manipulation Tasks from Few Demonstrations
Jul 18, 2024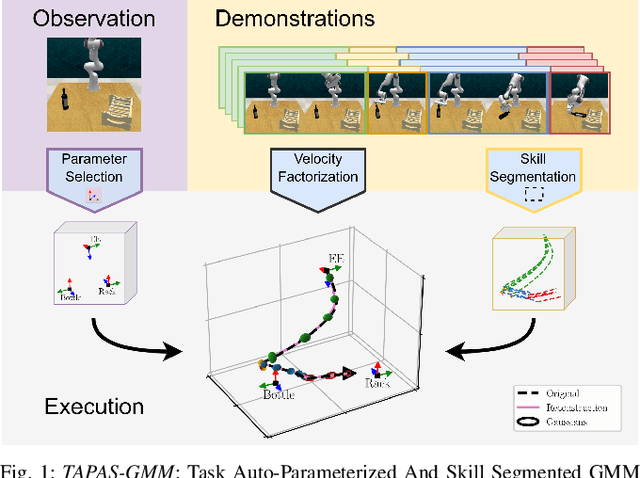
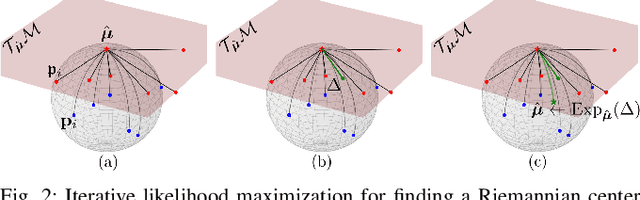
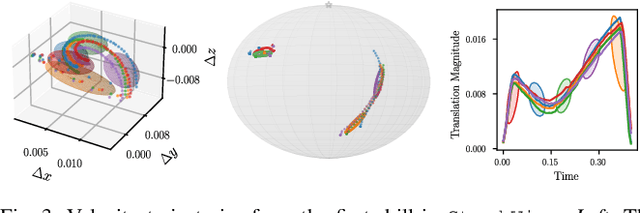
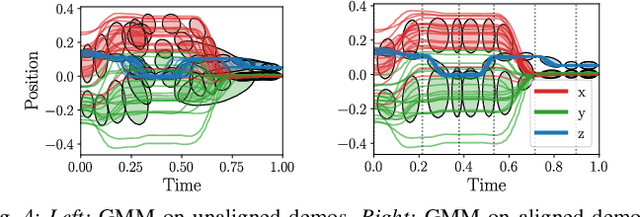
Task Parametrized Gaussian Mixture Models (TP-GMM) are a sample-efficient method for learning object-centric robot manipulation tasks. However, there are several open challenges to applying TP-GMMs in the wild. In this work, we tackle three crucial challenges synergistically. First, end-effector velocities are non-Euclidean and thus hard to model using standard GMMs. We thus propose to factorize the robot's end-effector velocity into its direction and magnitude, and model them using Riemannian GMMs. Second, we leverage the factorized velocities to segment and sequence skills from complex demonstration trajectories. Through the segmentation, we further align skill trajectories and hence leverage time as a powerful inductive bias. Third, we present a method to automatically detect relevant task parameters per skill from visual observations. Our approach enables learning complex manipulation tasks from just five demonstrations while using only RGB-D observations. Extensive experimental evaluations on RLBench demonstrate that our approach achieves state-of-the-art performance with 20-fold improved sample efficiency. Our policies generalize across different environments, object instances, and object positions, while the learned skills are reusable.
DITTO: Demonstration Imitation by Trajectory Transformation
Mar 22, 2024



Teaching robots new skills quickly and conveniently is crucial for the broader adoption of robotic systems. In this work, we address the problem of one-shot imitation from a single human demonstration, given by an RGB-D video recording through a two-stage process. In the first stage which is offline, we extract the trajectory of the demonstration. This entails segmenting manipulated objects and determining their relative motion in relation to secondary objects such as containers. Subsequently, in the live online trajectory generation stage, we first \mbox{re-detect} all objects, then we warp the demonstration trajectory to the current scene, and finally, we trace the trajectory with the robot. To complete these steps, our method makes leverages several ancillary models, including those for segmentation, relative object pose estimation, and grasp prediction. We systematically evaluate different combinations of correspondence and re-detection methods to validate our design decision across a diverse range of tasks. Specifically, we collect demonstrations of ten different tasks including pick-and-place tasks as well as articulated object manipulation. Finally, we perform extensive evaluations on a real robot system to demonstrate the effectiveness and utility of our approach in real-world scenarios. We make the code publicly available at http://ditto.cs.uni-freiburg.de.
Bayesian Optimization for Sample-Efficient Policy Improvement in Robotic Manipulation
Mar 21, 2024Sample efficient learning of manipulation skills poses a major challenge in robotics. While recent approaches demonstrate impressive advances in the type of task that can be addressed and the sensing modalities that can be incorporated, they still require large amounts of training data. Especially with regard to learning actions on robots in the real world, this poses a major problem due to the high costs associated with both demonstrations and real-world robot interactions. To address this challenge, we introduce BOpt-GMM, a hybrid approach that combines imitation learning with own experience collection. We first learn a skill model as a dynamical system encoded in a Gaussian Mixture Model from a few demonstrations. We then improve this model with Bayesian optimization building on a small number of autonomous skill executions in a sparse reward setting. We demonstrate the sample efficiency of our approach on multiple complex manipulation skills in both simulations and real-world experiments. Furthermore, we make the code and pre-trained models publicly available at http://bopt-gmm. cs.uni-freiburg.de.
Language-Grounded Dynamic Scene Graphs for Interactive Object Search with Mobile Manipulation
Mar 14, 2024



To fully leverage the capabilities of mobile manipulation robots, it is imperative that they are able to autonomously execute long-horizon tasks in large unexplored environments. While large language models (LLMs) have shown emergent reasoning skills on arbitrary tasks, existing work primarily concentrates on explored environments, typically focusing on either navigation or manipulation tasks in isolation. In this work, we propose MoMa-LLM, a novel approach that grounds language models within structured representations derived from open-vocabulary scene graphs, dynamically updated as the environment is explored. We tightly interleave these representations with an object-centric action space. The resulting approach is zero-shot, open-vocabulary, and readily extendable to a spectrum of mobile manipulation and household robotic tasks. We demonstrate the effectiveness of MoMa-LLM in a novel semantic interactive search task in large realistic indoor environments. In extensive experiments in both simulation and the real world, we show substantially improved search efficiency compared to conventional baselines and state-of-the-art approaches, as well as its applicability to more abstract tasks. We make the code publicly available at http://moma-llm.cs.uni-freiburg.de.
CenterGrasp: Object-Aware Implicit Representation Learning for Simultaneous Shape Reconstruction and 6-DoF Grasp Estimation
Dec 13, 2023Reliable object grasping is a crucial capability for autonomous robots. However, many existing grasping approaches focus on general clutter removal without explicitly modeling objects and thus only relying on the visible local geometry. We introduce CenterGrasp, a novel framework that combines object awareness and holistic grasping. CenterGrasp learns a general object prior by encoding shapes and valid grasps in a continuous latent space. It consists of an RGB-D image encoder that leverages recent advances to detect objects and infer their pose and latent code, and a decoder to predict shape and grasps for each object in the scene. We perform extensive experiments on simulated as well as real-world cluttered scenes and demonstrate strong scene reconstruction and 6-DoF grasp-pose estimation performance. Compared to the state of the art, CenterGrasp achieves an improvement of 38.5 mm in shape reconstruction and 33 percentage points on average in grasp success. We make the code and trained models publicly available at http://centergrasp.cs.uni-freiburg.de.