 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMORE: Mobile Manipulation Rearrangement Through Grounded Language Reasoning
May 05, 2025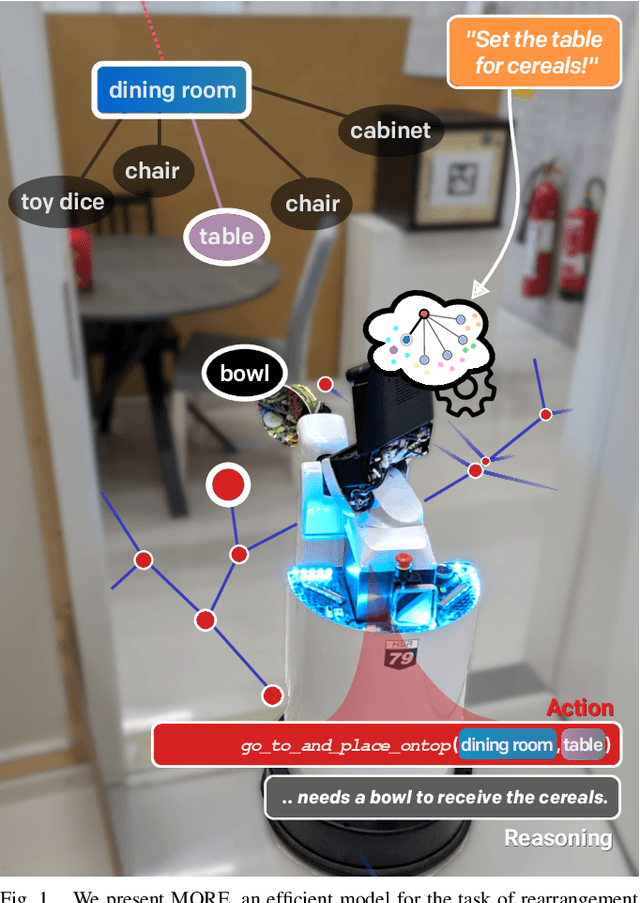
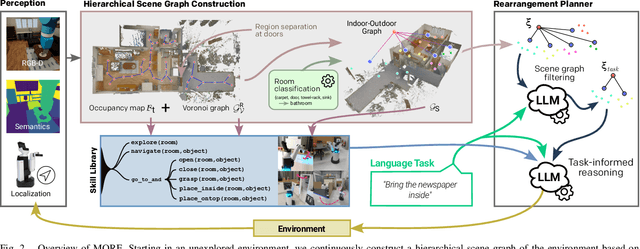
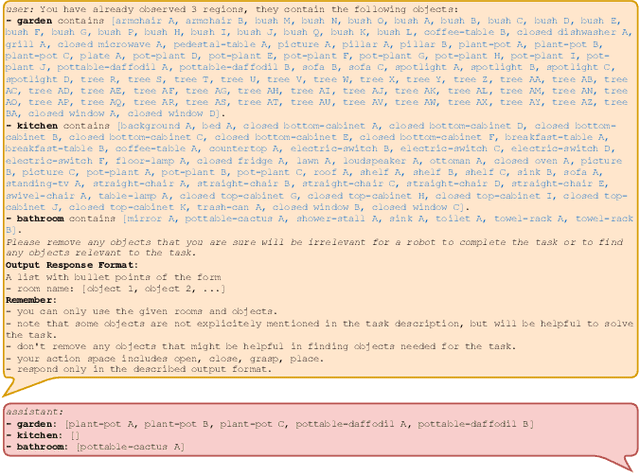
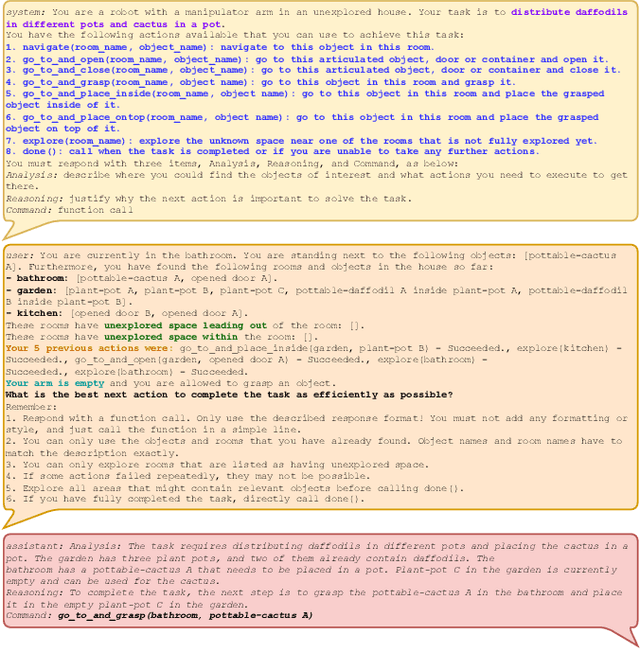
Autonomous long-horizon mobile manipulation encompasses a multitude of challenges, including scene dynamics, unexplored areas, and error recovery. Recent works have leveraged foundation models for scene-level robotic reasoning and planning. However, the performance of these methods degrades when dealing with a large number of objects and large-scale environments. To address these limitations, we propose MORE, a novel approach for enhancing the capabilities of language models to solve zero-shot mobile manipulation planning for rearrangement tasks. MORE leverages scene graphs to represent environments, incorporates instance differentiation, and introduces an active filtering scheme that extracts task-relevant subgraphs of object and region instances. These steps yield a bounded planning problem, effectively mitigating hallucinations and improving reliability. Additionally, we introduce several enhancements that enable planning across both indoor and outdoor environments. We evaluate MORE on 81 diverse rearrangement tasks from the BEHAVIOR-1K benchmark, where it becomes the first approach to successfully solve a significant share of the benchmark, outperforming recent foundation model-based approaches. Furthermore, we demonstrate the capabilities of our approach in several complex real-world tasks, mimicking everyday activities. We make the code publicly available at https://more-model.cs.uni-freiburg.de.
An explainable approach to detect case law on housing and eviction issues within the HUDOC database
Oct 03, 2024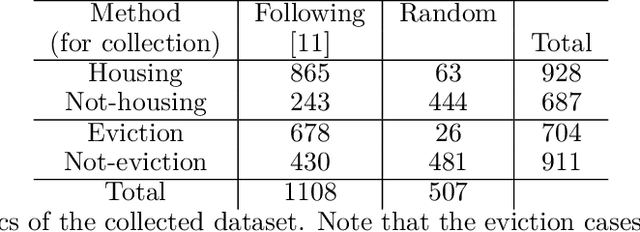
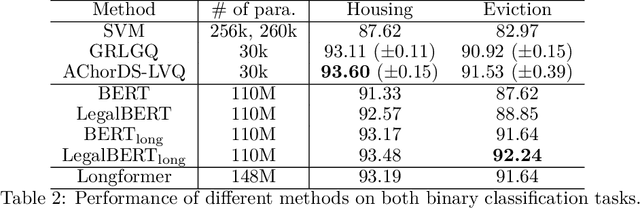
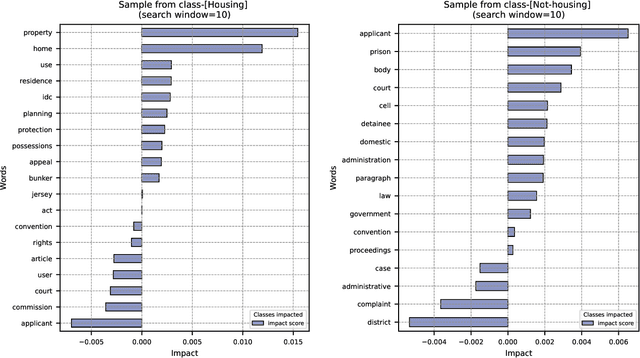
Case law is instrumental in shaping our understanding of human rights, including the right to adequate housing. The HUDOC database provides access to the textual content of case law from the European Court of Human Rights (ECtHR), along with some metadata. While this metadata includes valuable information, such as the application number and the articles addressed in a case, it often lacks detailed substantive insights, such as the specific issues a case covers. This underscores the need for detailed analysis to extract such information. However, given the size of the database - containing over 40,000 cases - an automated solution is essential. In this study, we focus on the right to adequate housing and aim to build models to detect cases related to housing and eviction issues. Our experiments show that the resulting models not only provide performance comparable to more sophisticated approaches but are also interpretable, offering explanations for their decisions by highlighting the most influential words. The application of these models led to the identification of new cases that were initially overlooked during data collection. This suggests that NLP approaches can be effectively applied to categorise case law based on the specific issues they address.
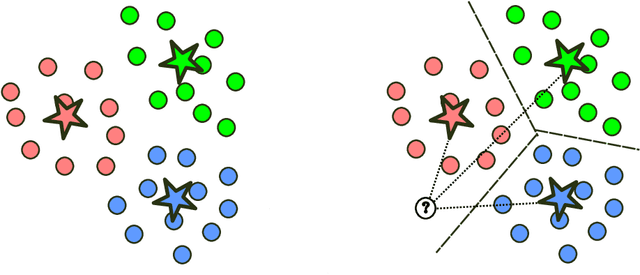
A prototype-based model for set classification
Aug 25, 2024Classification of sets of inputs (e.g., images and texts) is an active area of research within both computer vision (CV) and natural language processing (NLP). A common way to represent a set of vectors is to model them as linear subspaces. In this contribution, we present a prototype-based approach for learning on the manifold formed from such linear subspaces, the Grassmann manifold. Our proposed method learns a set of subspace prototypes capturing the representative characteristics of classes and a set of relevance factors automating the selection of the dimensionality of the subspaces. This leads to a transparent classifier model which presents the computed impact of each input vector on its decision. Through experiments on benchmark image and text datasets, we have demonstrated the efficiency of our proposed classifier, compared to the transformer-based models in terms of not only performance and explainability but also computational resource requirements.
Strategizing EV Charging and Renewable Integration in Texas
Oct 25, 2023Exploring the convergence of electric vehicles (EVs), renewable energy, and smart grid technologies in the context of Texas, this study addresses challenges hindering the widespread adoption of EVs. Acknowledging their environmental benefits, the research focuses on grid stability concerns, uncoordinated charging patterns, and the complicated relationship between EVs and renewable energy sources. Dynamic time warping (DTW) clustering and k-means clustering methodologies categorize days based on total load and net load, offering nuanced insights into daily electricity consumption and renewable energy generation patterns. By establishing optimal charging and vehicle-to-grid (V2G) windows tailored to specific load characteristics, the study provides a sophisticated methodology for strategic decision-making in energy consumption and renewable integration. The findings contribute to the ongoing discourse on achieving a sustainable and resilient energy future through the seamless integration of EVs into smart grids.
Empowering Distributed Solutions in Renewable Energy Systems and Grid Optimization
Oct 24, 2023This study delves into the shift from centralized to decentralized approaches in the electricity industry, with a particular focus on how machine learning (ML) advancements play a crucial role in empowering renewable energy sources and improving grid management. ML models have become increasingly important in predicting renewable energy generation and consumption, utilizing various techniques like artificial neural networks, support vector machines, and decision trees. Furthermore, data preprocessing methods, such as data splitting, normalization, decomposition, and discretization, are employed to enhance prediction accuracy. The incorporation of big data and ML into smart grids offers several advantages, including heightened energy efficiency, more effective responses to demand, and better integration of renewable energy sources. Nevertheless, challenges like handling large data volumes, ensuring cybersecurity, and obtaining specialized expertise must be addressed. The research investigates various ML applications within the realms of solar energy, wind energy, and electric distribution and storage, illustrating their potential to optimize energy systems. To sum up, this research demonstrates the evolving landscape of the electricity sector as it shifts from centralized to decentralized solutions through the application of ML innovations and distributed decision-making, ultimately shaping a more efficient and sustainable energy future.
Implicit Poisoning Attacks in Two-Agent Reinforcement Learning: Adversarial Policies for Training-Time Attacks
Feb 27, 2023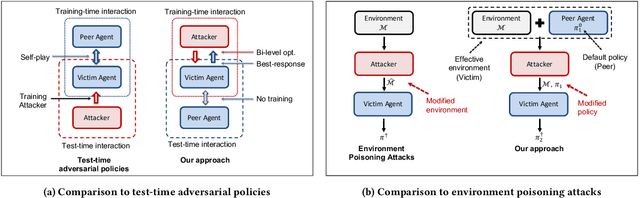

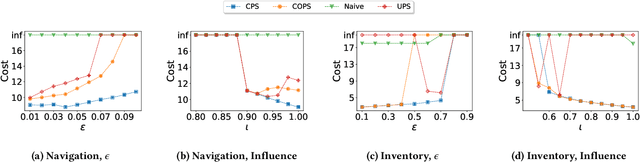
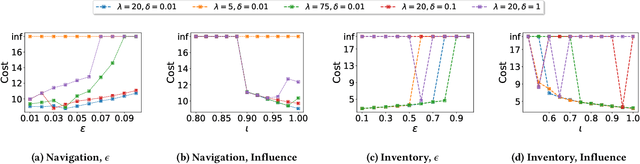
In targeted poisoning attacks, an attacker manipulates an agent-environment interaction to force the agent into adopting a policy of interest, called target policy. Prior work has primarily focused on attacks that modify standard MDP primitives, such as rewards or transitions. In this paper, we study targeted poisoning attacks in a two-agent setting where an attacker implicitly poisons the effective environment of one of the agents by modifying the policy of its peer. We develop an optimization framework for designing optimal attacks, where the cost of the attack measures how much the solution deviates from the assumed default policy of the peer agent. We further study the computational properties of this optimization framework. Focusing on a tabular setting, we show that in contrast to poisoning attacks based on MDP primitives (transitions and (unbounded) rewards), which are always feasible, it is NP-hard to determine the feasibility of implicit poisoning attacks. We provide characterization results that establish sufficient conditions for the feasibility of the attack problem, as well as an upper and a lower bound on the optimal cost of the attack. We propose two algorithmic approaches for finding an optimal adversarial policy: a model-based approach with tabular policies and a model-free approach with parametric/neural policies. We showcase the efficacy of the proposed algorithms through experiments.
PALMER: Perception-Action Loop with Memory for Long-Horizon Planning
Dec 08, 2022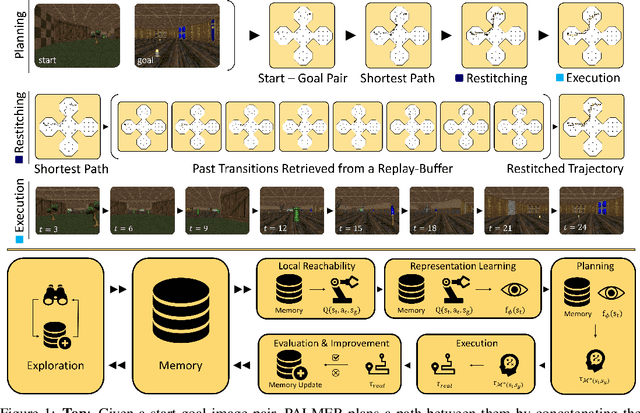

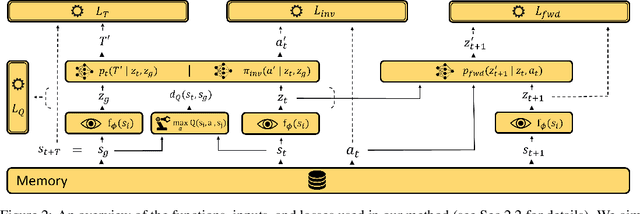
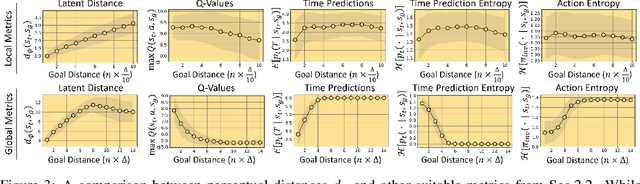
To achieve autonomy in a priori unknown real-world scenarios, agents should be able to: i) act from high-dimensional sensory observations (e.g., images), ii) learn from past experience to adapt and improve, and iii) be capable of long horizon planning. Classical planning algorithms (e.g. PRM, RRT) are proficient at handling long-horizon planning. Deep learning based methods in turn can provide the necessary representations to address the others, by modeling statistical contingencies between observations. In this direction, we introduce a general-purpose planning algorithm called PALMER that combines classical sampling-based planning algorithms with learning-based perceptual representations. For training these perceptual representations, we combine Q-learning with contrastive representation learning to create a latent space where the distance between the embeddings of two states captures how easily an optimal policy can traverse between them. For planning with these perceptual representations, we re-purpose classical sampling-based planning algorithms to retrieve previously observed trajectory segments from a replay buffer and restitch them into approximately optimal paths that connect any given pair of start and goal states. This creates a tight feedback loop between representation learning, memory, reinforcement learning, and sampling-based planning. The end result is an experiential framework for long-horizon planning that is significantly more robust and sample efficient compared to existing methods.
Detection of extragalactic Ultra-Compact Dwarfs and Globular Clusters using Explainable AI techniques
Jan 07, 2022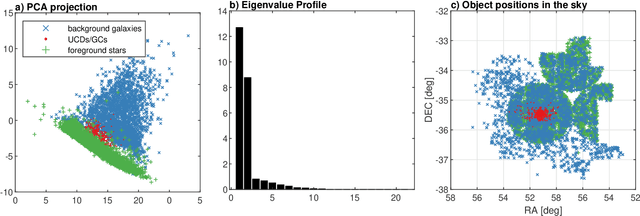
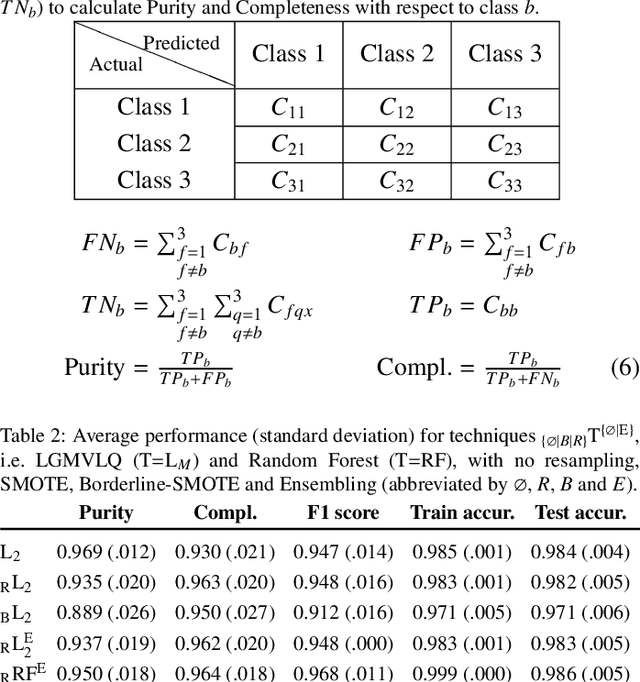
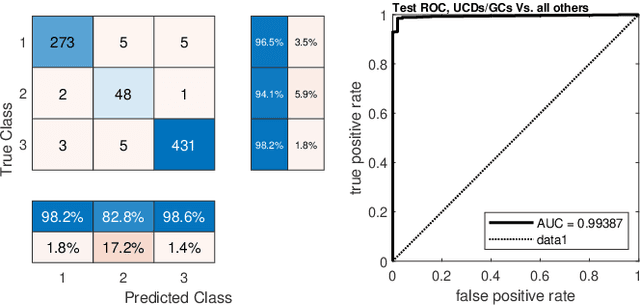
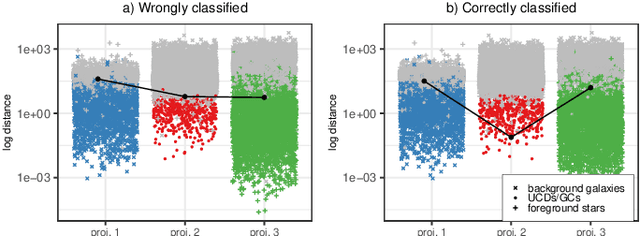
Compact stellar systems such as Ultra-compact dwarfs (UCDs) and Globular Clusters (GCs) around galaxies are known to be the tracers of the merger events that have been forming these galaxies. Therefore, identifying such systems allows to study galaxies mass assembly, formation and evolution. However, in the lack of spectroscopic information detecting UCDs/GCs using imaging data is very uncertain. Here, we aim to train a machine learning model to separate these objects from the foreground stars and background galaxies using the multi-wavelength imaging data of the Fornax galaxy cluster in 6 filters, namely u, g, r, i, J and Ks. The classes of objects are highly imbalanced which is problematic for many automatic classification techniques. Hence, we employ Synthetic Minority Over-sampling to handle the imbalance of the training data. Then, we compare two classifiers, namely Localized Generalized Matrix Learning Vector Quantization (LGMLVQ) and Random Forest (RF). Both methods are able to identify UCDs/GCs with a precision and a recall of >93 percent and provide relevances that reflect the importance of each feature dimension %(colors and angular sizes) for the classification. Both methods detect angular sizes as important markers for this classification problem. While it is astronomical expectation that color indices of u-i and i-Ks are the most important colors, our analysis shows that colors such as g-r are more informative, potentially because of higher signal-to-noise ratio. Besides the excellent performance the LGMLVQ method allows further interpretability by providing the feature importance for each individual class, class-wise representative samples and the possibility for non-linear visualization of the data as demonstrated in this contribution. We conclude that employing machine learning techniques to identify UCDs/GCs can lead to promising results.
Medical Imaging and Computational Image Analysis in COVID-19 Diagnosis: A Review
Oct 01, 2020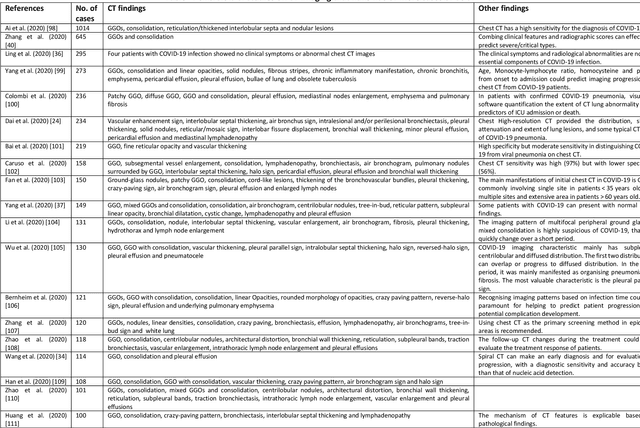
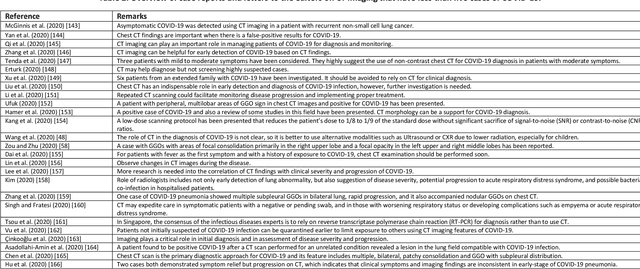

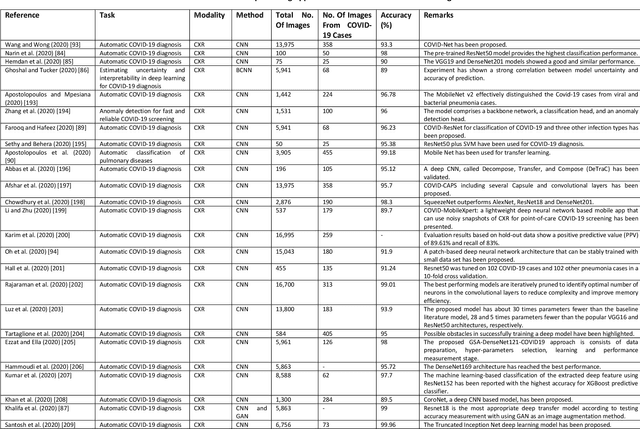
Coronavirus disease (COVID-19) is an infectious disease caused by a newly discovered coronavirus. The disease presents with symptoms such as shortness of breath, fever, dry cough, and chronic fatigue, amongst others. Sometimes the symptoms of the disease increase so much they lead to the death of the patients. The disease may be asymptomatic in some patients in the early stages, which can lead to increased transmission of the disease to others. Many studies have tried to use medical imaging for early diagnosis of COVID-19. This study attempts to review papers on automatic methods for medical image analysis and diagnosis of COVID-19. For this purpose, PubMed, Google Scholar, arXiv and medRxiv were searched to find related studies by the end of April 2020, and the essential points of the collected studies were summarised. The contribution of this study is four-fold: 1) to use as a tutorial of the field for both clinicians and technologists, 2) to comprehensively review the characteristics of COVID-19 as presented in medical images, 3) to examine automated artificial intelligence-based approaches for COVID-19 diagnosis based on the accuracy and the method used, 4) to express the research limitations in this field and the methods used to overcome them. COVID-19 reveals signs in medical images can be used for early diagnosis of the disease even in asymptomatic patients. Using automated machine learning-based methods can diagnose the disease with high accuracy from medical images and reduce time, cost and error of diagnostic procedure. It is recommended to collect bulk imaging data from patients in the shortest possible time to improve the performance of COVID-19 automated diagnostic methods.
An expert system for recommending suitable ornamental fish addition to an aquarium based on aquarium condition
May 07, 2014

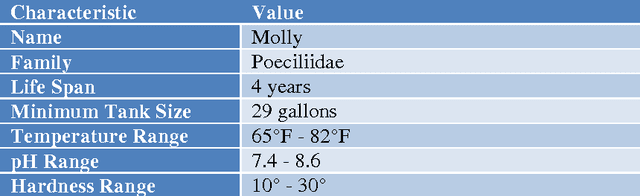
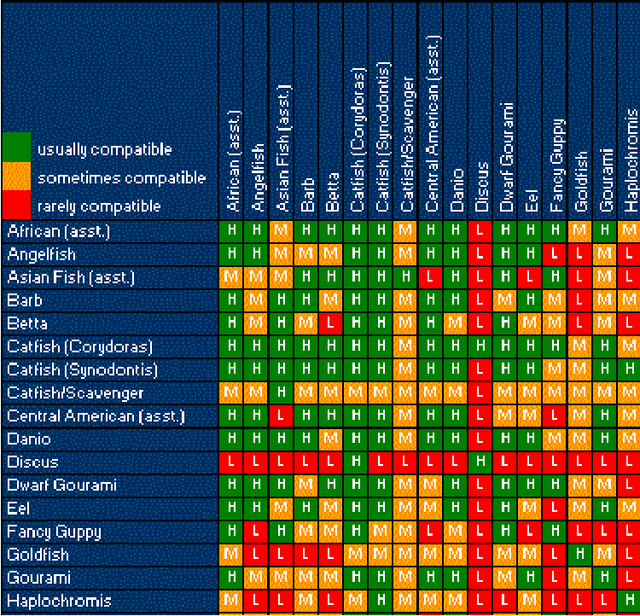
Expert systems prove to be suitable replacement for human experts when human experts are unavailable for different reasons. Various expert system has been developed for wide range of application. Although some expert systems in the field of fishery and aquaculture has been developed but a system that aids user in process of selecting a new addition to their aquarium tank never been designed. This paper proposed an expert system that suggests new addition to an aquarium tank based on current environmental condition of aquarium and currently existing fishes in aquarium. The system suggest the best fit for aquarium condition and most compatible to other fishes in aquarium.