 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA prototype-based model for set classification
Aug 25, 2024Classification of sets of inputs (e.g., images and texts) is an active area of research within both computer vision (CV) and natural language processing (NLP). A common way to represent a set of vectors is to model them as linear subspaces. In this contribution, we present a prototype-based approach for learning on the manifold formed from such linear subspaces, the Grassmann manifold. Our proposed method learns a set of subspace prototypes capturing the representative characteristics of classes and a set of relevance factors automating the selection of the dimensionality of the subspaces. This leads to a transparent classifier model which presents the computed impact of each input vector on its decision. Through experiments on benchmark image and text datasets, we have demonstrated the efficiency of our proposed classifier, compared to the transformer-based models in terms of not only performance and explainability but also computational resource requirements.
Interpretable Models Capable of Handling Systematic Missingness in Imbalanced Classes and Heterogeneous Datasets
Jun 04, 2022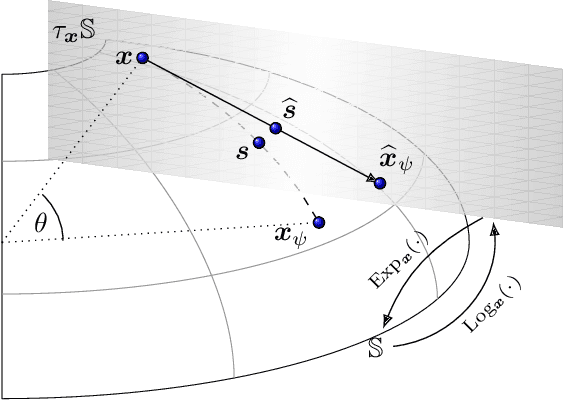
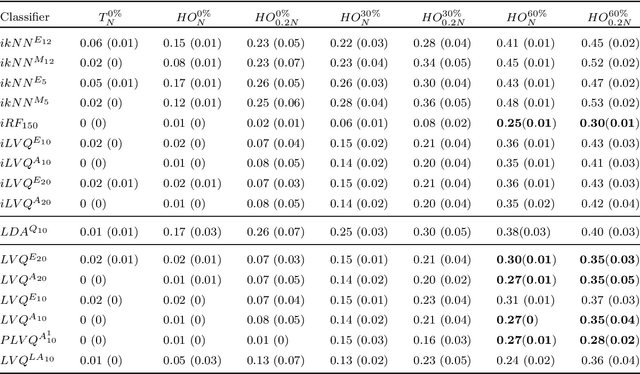

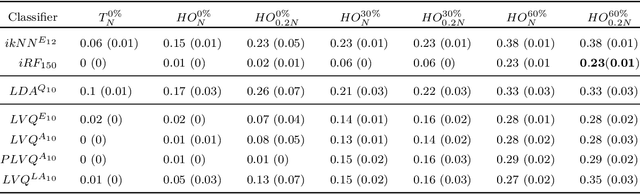
Application of interpretable machine learning techniques on medical datasets facilitate early and fast diagnoses, along with getting deeper insight into the data. Furthermore, the transparency of these models increase trust among application domain experts. Medical datasets face common issues such as heterogeneous measurements, imbalanced classes with limited sample size, and missing data, which hinder the straightforward application of machine learning techniques. In this paper we present a family of prototype-based (PB) interpretable models which are capable of handling these issues. The models introduced in this contribution show comparable or superior performance to alternative techniques applicable in such situations. However, unlike ensemble based models, which have to compromise on easy interpretation, the PB models here do not. Moreover we propose a strategy of harnessing the power of ensembles while maintaining the intrinsic interpretability of the PB models, by averaging the model parameter manifolds. All the models were evaluated on a synthetic (publicly available dataset) in addition to detailed analyses of two real-world medical datasets (one publicly available). Results indicated that the models and strategies we introduced addressed the challenges of real-world medical data, while remaining computationally inexpensive and transparent, as well as similar or superior in performance compared to their alternatives.
Visualisation and knowledge discovery from interpretable models
May 08, 2020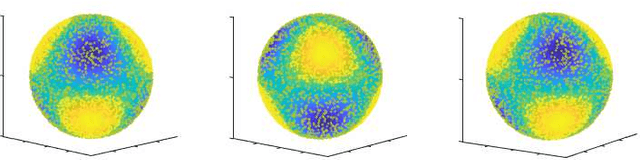

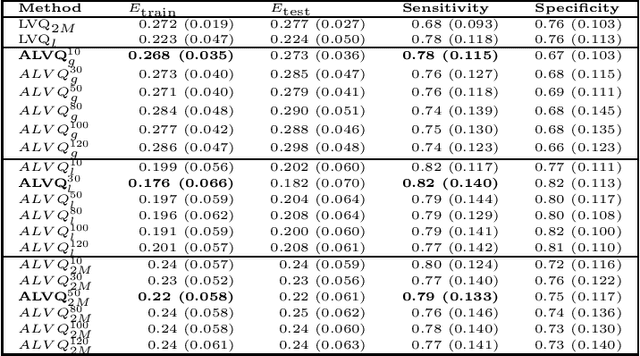
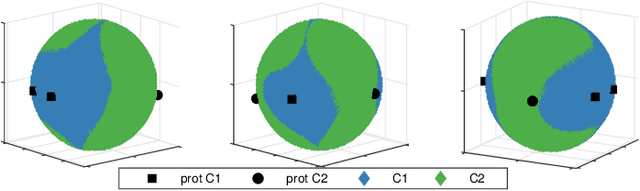
Increasing number of sectors which affect human lives, are using Machine Learning (ML) tools. Hence the need for understanding their working mechanism and evaluating their fairness in decision-making, are becoming paramount, ushering in the era of Explainable AI (XAI). In this contribution we introduced a few intrinsically interpretable models which are also capable of dealing with missing values, in addition to extracting knowledge from the dataset and about the problem. These models are also capable of visualisation of the classifier and decision boundaries: they are the angle based variants of Learning Vector Quantization. We have demonstrated the algorithms on a synthetic dataset and a real-world one (heart disease dataset from the UCI repository). The newly developed classifiers helped in investigating the complexities of the UCI dataset as a multiclass problem. The performance of the developed classifiers were comparable to those reported in literature for this dataset, with additional value of interpretability, when the dataset was treated as a binary class problem.