 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Offline Reinforcement Learning with Corruption Robustness
Dec 31, 2025We investigate robustness to strong data corruption in offline sparse reinforcement learning (RL). In our setting, an adversary may arbitrarily perturb a fraction of the collected trajectories from a high-dimensional but sparse Markov decision process, and our goal is to estimate a near optimal policy. The main challenge is that, in the high-dimensional regime where the number of samples $N$ is smaller than the feature dimension $d$, exploiting sparsity is essential for obtaining non-vacuous guarantees but has not been systematically studied in offline RL. We analyse the problem under uniform coverage and sparse single-concentrability assumptions. While Least Square Value Iteration (LSVI), a standard approach for robust offline RL, performs well under uniform coverage, we show that integrating sparsity into LSVI is unnatural, and its analysis may break down due to overly pessimistic bonuses. To overcome this, we propose actor-critic methods with sparse robust estimator oracles, which avoid the use of pointwise pessimistic bonuses and provide the first non-vacuous guarantees for sparse offline RL under single-policy concentrability coverage. Moreover, we extend our results to the contaminated setting and show that our algorithm remains robust under strong contamination. Our results provide the first non-vacuous guarantees in high-dimensional sparse MDPs with single-policy concentrability coverage and corruption, showing that learning a near-optimal policy remains possible in regimes where traditional robust offline RL techniques may fail.
On Corruption-Robustness in Performative Reinforcement Learning
May 08, 2025In performative Reinforcement Learning (RL), an agent faces a policy-dependent environment: the reward and transition functions depend on the agent's policy. Prior work on performative RL has studied the convergence of repeated retraining approaches to a performatively stable policy. In the finite sample regime, these approaches repeatedly solve for a saddle point of a convex-concave objective, which estimates the Lagrangian of a regularized version of the reinforcement learning problem. In this paper, we aim to extend such repeated retraining approaches, enabling them to operate under corrupted data. More specifically, we consider Huber's $\epsilon$-contamination model, where an $\epsilon$ fraction of data points is corrupted by arbitrary adversarial noise. We propose a repeated retraining approach based on convex-concave optimization under corrupted gradients and a novel problem-specific robust mean estimator for the gradients. We prove that our approach exhibits last-iterate convergence to an approximately stable policy, with the approximation error linear in $\sqrt{\epsilon}$. We experimentally demonstrate the importance of accounting for corruption in performative RL.
Independent Learning in Performative Markov Potential Games
Apr 29, 2025
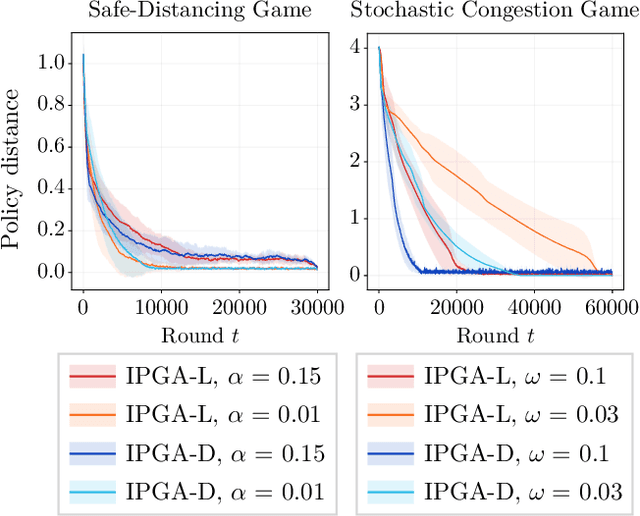
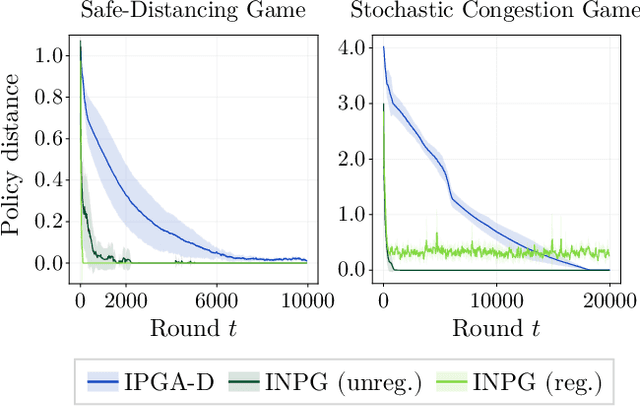
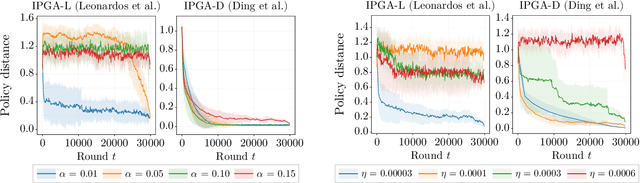
Performative Reinforcement Learning (PRL) refers to a scenario in which the deployed policy changes the reward and transition dynamics of the underlying environment. In this work, we study multi-agent PRL by incorporating performative effects into Markov Potential Games (MPGs). We introduce the notion of a performatively stable equilibrium (PSE) and show that it always exists under a reasonable sensitivity assumption. We then provide convergence results for state-of-the-art algorithms used to solve MPGs. Specifically, we show that independent policy gradient ascent (IPGA) and independent natural policy gradient (INPG) converge to an approximate PSE in the best-iterate sense, with an additional term that accounts for the performative effects. Furthermore, we show that INPG asymptotically converges to a PSE in the last-iterate sense. As the performative effects vanish, we recover the convergence rates from prior work. For a special case of our game, we provide finite-time last-iterate convergence results for a repeated retraining approach, in which agents independently optimize a surrogate objective. We conduct extensive experiments to validate our theoretical findings.
Policy Teaching via Data Poisoning in Learning from Human Preferences
Mar 13, 2025
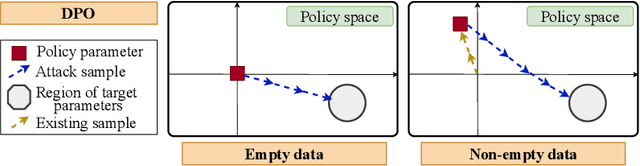
We study data poisoning attacks in learning from human preferences. More specifically, we consider the problem of teaching/enforcing a target policy $\pi^\dagger$ by synthesizing preference data. We seek to understand the susceptibility of different preference-based learning paradigms to poisoned preference data by analyzing the number of samples required by the attacker to enforce $\pi^\dagger$. We first propose a general data poisoning formulation in learning from human preferences and then study it for two popular paradigms, namely: (a) reinforcement learning from human feedback (RLHF) that operates by learning a reward model using preferences; (b) direct preference optimization (DPO) that directly optimizes policy using preferences. We conduct a theoretical analysis of the effectiveness of data poisoning in a setting where the attacker is allowed to augment a pre-existing dataset and also study its special case where the attacker can synthesize the entire preference dataset from scratch. As our main results, we provide lower/upper bounds on the number of samples required to enforce $\pi^\dagger$. Finally, we discuss the implications of our results in terms of the susceptibility of these learning paradigms under such data poisoning attacks.
Strategyproof Reinforcement Learning from Human Feedback
Mar 12, 2025We study Reinforcement Learning from Human Feedback (RLHF), where multiple individuals with diverse preferences provide feedback strategically to sway the final policy in their favor. We show that existing RLHF methods are not strategyproof, which can result in learning a substantially misaligned policy even when only one out of $k$ individuals reports their preferences strategically. In turn, we also find that any strategyproof RLHF algorithm must perform $k$-times worse than the optimal policy, highlighting an inherent trade-off between incentive alignment and policy alignment. We then propose a pessimistic median algorithm that, under appropriate coverage assumptions, is approximately strategyproof and converges to the optimal policy as the number of individuals and samples increases.
Surprisingly Popular Voting for Concentric Rank-Order Models
Nov 13, 2024



An important problem on social information sites is the recovery of ground truth from individual reports when the experts are in the minority. The wisdom of the crowd, i.e. the collective opinion of a group of individuals fails in such a scenario. However, the surprisingly popular (SP) algorithm~\cite{prelec2017solution} can recover the ground truth even when the experts are in the minority, by asking the individuals to report additional prediction reports--their beliefs about the reports of others. Several recent works have extended the surprisingly popular algorithm to an equivalent voting rule (SP-voting) to recover the ground truth ranking over a set of $m$ alternatives. However, we are yet to fully understand when SP-voting can recover the ground truth ranking, and if so, how many samples (votes and predictions) it needs. We answer this question by proposing two rank-order models and analyzing the sample complexity of SP-voting under these models. In particular, we propose concentric mixtures of Mallows and Plackett-Luce models with $G (\ge 2)$ groups. Our models generalize previously proposed concentric mixtures of Mallows models with $2$ groups, and we highlight the importance of $G > 2$ groups by identifying three distinct groups (expert, intermediate, and non-expert) from existing datasets. Next, we provide conditions on the parameters of the underlying models so that SP-voting can recover ground-truth rankings with high probability, and also derive sample complexities under the same. We complement the theoretical results by evaluating SP-voting on simulated and real datasets.
Performative Reinforcement Learning with Linear Markov Decision Process
Nov 07, 2024We study the setting of \emph{performative reinforcement learning} where the deployed policy affects both the reward, and the transition of the underlying Markov decision process. Prior work~\parencite{MTR23} has addressed this problem under the tabular setting and established last-iterate convergence of repeated retraining with iteration complexity explicitly depending on the number of states. In this work, we generalize the results to \emph{linear Markov decision processes} which is the primary theoretical model of large-scale MDPs. The main challenge with linear MDP is that the regularized objective is no longer strongly convex and we want a bound that scales with the dimension of the features, rather than states which can be infinite. Our first result shows that repeatedly optimizing a regularized objective converges to a \emph{performatively stable policy}. In the absence of strong convexity, our analysis leverages a new recurrence relation that uses a specific linear combination of optimal dual solutions for proving convergence. We then tackle the finite sample setting where the learner has access to a set of trajectories drawn from the current policy. We consider a reparametrized version of the primal problem, and construct an empirical Lagrangian which is to be optimized from the samples. We show that, under a \emph{bounded coverage} condition, repeatedly solving a saddle point of this empirical Lagrangian converges to a performatively stable solution, and also construct a primal-dual algorithm that solves the empirical Lagrangian efficiently. Finally, we show several applications of the general framework of performative RL including multi-agent systems.
Symmetric Linear Bandits with Hidden Symmetry
May 22, 2024High-dimensional linear bandits with low-dimensional structure have received considerable attention in recent studies due to their practical significance. The most common structure in the literature is sparsity. However, it may not be available in practice. Symmetry, where the reward is invariant under certain groups of transformations on the set of arms, is another important inductive bias in the high-dimensional case that covers many standard structures, including sparsity. In this work, we study high-dimensional symmetric linear bandits where the symmetry is hidden from the learner, and the correct symmetry needs to be learned in an online setting. We examine the structure of a collection of hidden symmetry and provide a method based on model selection within the collection of low-dimensional subspaces. Our algorithm achieves a regret bound of $ O(d_0^{1/3} T^{2/3} \log(d))$, where $d$ is the ambient dimension which is potentially very large, and $d_0$ is the dimension of the true low-dimensional subspace such that $d_0 \ll d$. With an extra assumption on well-separated models, we can further improve the regret to $ O(d_0\sqrt{T\log(d)} )$.
Corruption-Robust Offline Two-Player Zero-Sum Markov Games
Mar 04, 2024We study data corruption robustness in offline two-player zero-sum Markov games. Given a dataset of realized trajectories of two players, an adversary is allowed to modify an $\epsilon$-fraction of it. The learner's goal is to identify an approximate Nash Equilibrium policy pair from the corrupted data. We consider this problem in linear Markov games under different degrees of data coverage and corruption. We start by providing an information-theoretic lower bound on the suboptimality gap of any learner. Next, we propose robust versions of the Pessimistic Minimax Value Iteration algorithm, both under coverage on the corrupted data and under coverage only on the clean data, and show that they achieve (near)-optimal suboptimality gap bounds with respect to $\epsilon$. We note that we are the first to provide such a characterization of the problem of learning approximate Nash Equilibrium policies in offline two-player zero-sum Markov games under data corruption.
Reward Model Learning vs. Direct Policy Optimization: A Comparative Analysis of Learning from Human Preferences
Mar 04, 2024In this paper, we take a step towards a deeper understanding of learning from human preferences by systematically comparing the paradigm of reinforcement learning from human feedback (RLHF) with the recently proposed paradigm of direct preference optimization (DPO). We focus our attention on the class of loglinear policy parametrization and linear reward functions. In order to compare the two paradigms, we first derive minimax statistical bounds on the suboptimality gap induced by both RLHF and DPO, assuming access to an oracle that exactly solves the optimization problems. We provide a detailed discussion on the relative comparison between the two paradigms, simultaneously taking into account the sample size, policy and reward class dimensions, and the regularization temperature. Moreover, we extend our analysis to the approximate optimization setting and derive exponentially decaying convergence rates for both RLHF and DPO. Next, we analyze the setting where the ground-truth reward is not realizable and find that, while RLHF incurs a constant additional error, DPO retains its asymptotically decaying gap by just tuning the temperature accordingly. Finally, we extend our comparison to the Markov decision process setting, where we generalize our results with exact optimization. To the best of our knowledge, we are the first to provide such a comparative analysis for RLHF and DPO.