 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Curriculum with Task Correlations for Deep Reinforcement Learning
May 03, 2024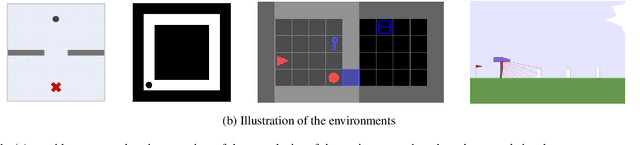


Curriculum design for reinforcement learning (RL) can speed up an agent's learning process and help it learn to perform well on complex tasks. However, existing techniques typically require domain-specific hyperparameter tuning, involve expensive optimization procedures for task selection, or are suitable only for specific learning objectives. In this work, we consider curriculum design in contextual multi-task settings where the agent's final performance is measured w.r.t. a target distribution over complex tasks. We base our curriculum design on the Zone of Proximal Development concept, which has proven to be effective in accelerating the learning process of RL agents for uniform distribution over all tasks. We propose a novel curriculum, ProCuRL-Target, that effectively balances the need for selecting tasks that are not too difficult for the agent while progressing the agent's learning toward the target distribution via leveraging task correlations. We theoretically justify the task selection strategy of ProCuRL-Target by analyzing a simple learning setting with REINFORCE learner model. Our experimental results across various domains with challenging target task distributions affirm the effectiveness of our curriculum strategy over state-of-the-art baselines in accelerating the training process of deep RL agents.
Reward Model Learning vs. Direct Policy Optimization: A Comparative Analysis of Learning from Human Preferences
Mar 04, 2024In this paper, we take a step towards a deeper understanding of learning from human preferences by systematically comparing the paradigm of reinforcement learning from human feedback (RLHF) with the recently proposed paradigm of direct preference optimization (DPO). We focus our attention on the class of loglinear policy parametrization and linear reward functions. In order to compare the two paradigms, we first derive minimax statistical bounds on the suboptimality gap induced by both RLHF and DPO, assuming access to an oracle that exactly solves the optimization problems. We provide a detailed discussion on the relative comparison between the two paradigms, simultaneously taking into account the sample size, policy and reward class dimensions, and the regularization temperature. Moreover, we extend our analysis to the approximate optimization setting and derive exponentially decaying convergence rates for both RLHF and DPO. Next, we analyze the setting where the ground-truth reward is not realizable and find that, while RLHF incurs a constant additional error, DPO retains its asymptotically decaying gap by just tuning the temperature accordingly. Finally, we extend our comparison to the Markov decision process setting, where we generalize our results with exact optimization. To the best of our knowledge, we are the first to provide such a comparative analysis for RLHF and DPO.
Learning Embeddings for Sequential Tasks Using Population of Agents
Jun 05, 2023We present an information-theoretic framework to learn fixed-dimensional embeddings for tasks in reinforcement learning. We leverage the idea that two tasks are similar to each other if observing an agent's performance on one task reduces our uncertainty about its performance on the other. This intuition is captured by our information-theoretic criterion which uses a diverse population of agents to measure similarity between tasks in sequential decision-making settings. In addition to qualitative assessment, we empirically demonstrate the effectiveness of our techniques based on task embeddings by quantitative comparisons against strong baselines on two application scenarios: predicting an agent's performance on a test task by observing its performance on a small quiz of tasks, and selecting tasks with desired characteristics from a given set of options.
Neural Task Synthesis for Visual Programming
Jun 01, 2023



Generative neural models hold great promise in enhancing programming education by synthesizing new content for students. We seek to design neural models that can automatically generate programming tasks for a given specification in the context of visual programming domains. Despite the recent successes of large generative models like GPT-4, our initial results show that these models are ineffective in synthesizing visual programming tasks and struggle with logical and spatial reasoning. We propose a novel neuro-symbolic technique, NeurTaskSyn, that can synthesize programming tasks for a specification given in the form of desired programming concepts exercised by its solution code and constraints on the visual task. NeurTaskSyn has two components: the first component is trained via imitation learning procedure to generate possible solution codes, and the second component is trained via reinforcement learning procedure to guide an underlying symbolic execution engine that generates visual tasks for these codes. We demonstrate the effectiveness of NeurTaskSyn through an extensive empirical evaluation and a qualitative study on reference tasks taken from the Hour of Code: Classic Maze challenge by Code-dot-org and the Intro to Programming with Karel course by CodeHS-dot-com.
Proximal Curriculum for Reinforcement Learning Agents
Apr 25, 2023
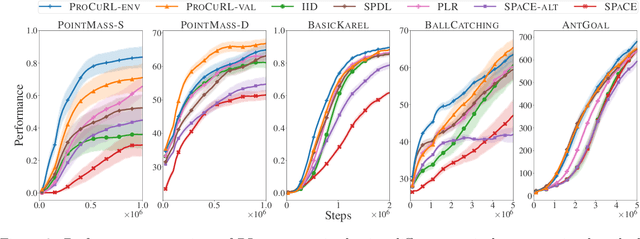
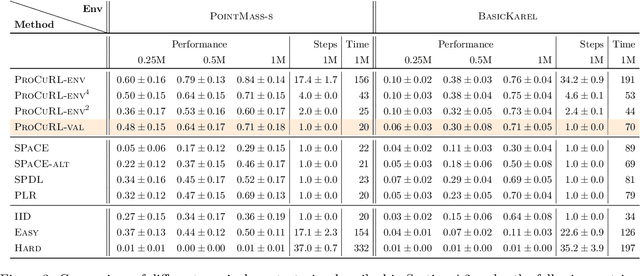
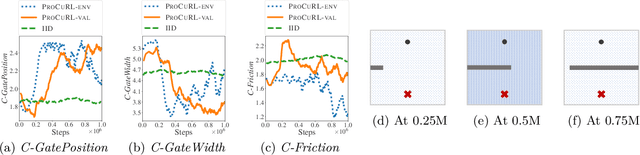
We consider the problem of curriculum design for reinforcement learning (RL) agents in contextual multi-task settings. Existing techniques on automatic curriculum design typically require domain-specific hyperparameter tuning or have limited theoretical underpinnings. To tackle these limitations, we design our curriculum strategy, ProCuRL, inspired by the pedagogical concept of Zone of Proximal Development (ZPD). ProCuRL captures the intuition that learning progress is maximized when picking tasks that are neither too hard nor too easy for the learner. We mathematically derive ProCuRL by analyzing two simple learning settings. We also present a practical variant of ProCuRL that can be directly integrated with deep RL frameworks with minimal hyperparameter tuning. Experimental results on a variety of domains demonstrate the effectiveness of our curriculum strategy over state-of-the-art baselines in accelerating the training process of deep RL agents.