 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyNet: Learning Diverse Solution Strategies for Neural Combinatorial Optimization
Feb 21, 2024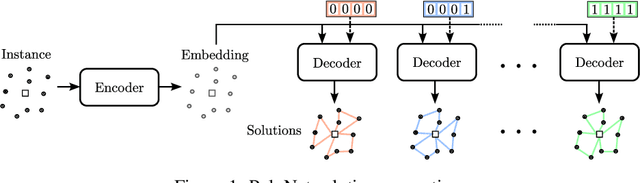


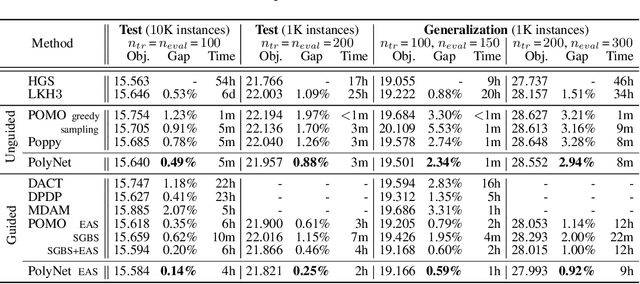
Reinforcement learning-based methods for constructing solutions to combinatorial optimization problems are rapidly approaching the performance of human-designed algorithms. To further narrow the gap, learning-based approaches must efficiently explore the solution space during the search process. Recent approaches artificially increase exploration by enforcing diverse solution generation through handcrafted rules, however, these rules can impair solution quality and are difficult to design for more complex problems. In this paper, we introduce PolyNet, an approach for improving exploration of the solution space by learning complementary solution strategies. In contrast to other works, PolyNet uses only a single-decoder and a training schema that does not enforce diverse solution generation through handcrafted rules. We evaluate PolyNet on four combinatorial optimization problems and observe that the implicit diversity mechanism allows PolyNet to find better solutions than approaches the explicitly enforce diverse solution generation.
Learning Embeddings for Sequential Tasks Using Population of Agents
Jun 05, 2023We present an information-theoretic framework to learn fixed-dimensional embeddings for tasks in reinforcement learning. We leverage the idea that two tasks are similar to each other if observing an agent's performance on one task reduces our uncertainty about its performance on the other. This intuition is captured by our information-theoretic criterion which uses a diverse population of agents to measure similarity between tasks in sequential decision-making settings. In addition to qualitative assessment, we empirically demonstrate the effectiveness of our techniques based on task embeddings by quantitative comparisons against strong baselines on two application scenarios: predicting an agent's performance on a test task by observing its performance on a small quiz of tasks, and selecting tasks with desired characteristics from a given set of options.
METEOR: A Massive Dense & Heterogeneous Behavior Dataset for Autonomous Driving
Sep 30, 2021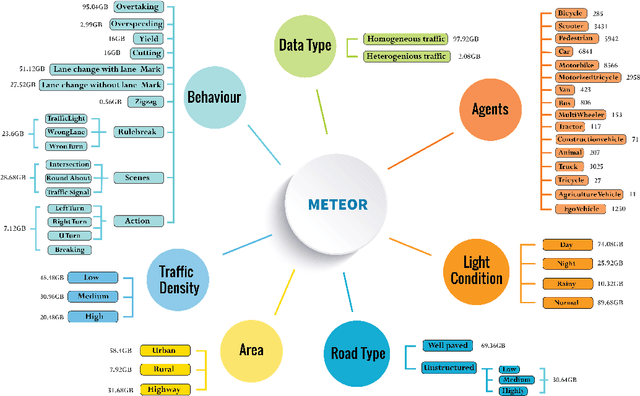

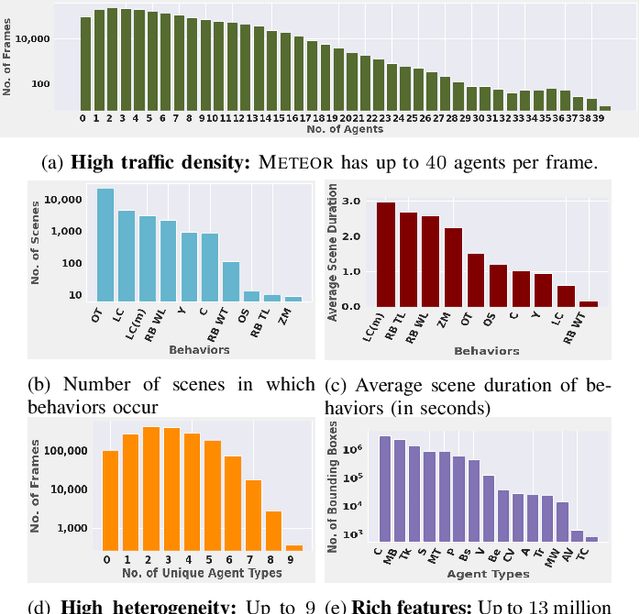

We present a new and complex traffic dataset, METEOR, which captures traffic patterns in unstructured scenarios in India. METEOR consists of more than 1000 one-minute video clips, over 2 million annotated frames with ego-vehicle trajectories, and more than 13 million bounding boxes for surrounding vehicles or traffic agents. METEOR is a unique dataset in terms of capturing the heterogeneity of microscopic and macroscopic traffic characteristics. Furthermore, we provide annotations for rare and interesting driving behaviors such as cut-ins, yielding, overtaking, overspeeding, zigzagging, sudden lane changing, running traffic signals, driving in the wrong lanes, taking wrong turns, lack of right-of-way rules at intersections, etc. We also present diverse traffic scenarios corresponding to rainy weather, nighttime driving, driving in rural areas with unmarked roads, and high-density traffic scenarios. We use our novel dataset to evaluate the performance of object detection and behavior prediction algorithms. We show that state-of-the-art object detectors fail in these challenging conditions and also propose a new benchmark test: action-behavior prediction with a baseline mAP score of 70.74.
Semi-supervised Grasp Detection by Representation Learning in a Vector Quantized Latent Space
Jan 30, 2020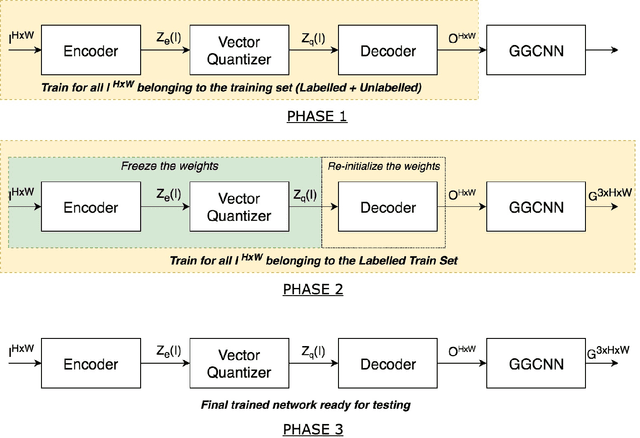
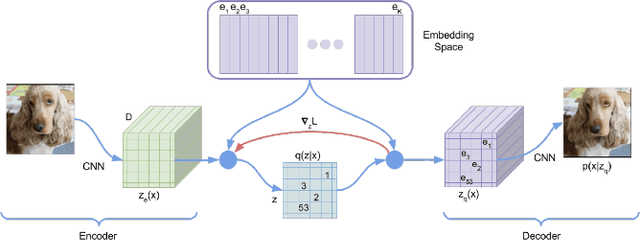
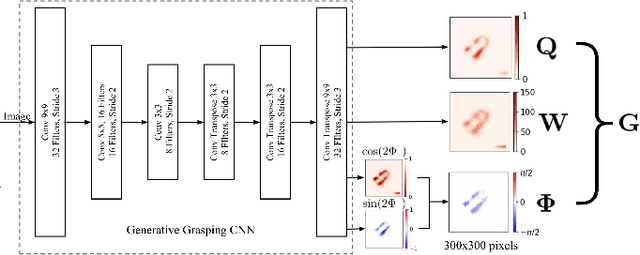
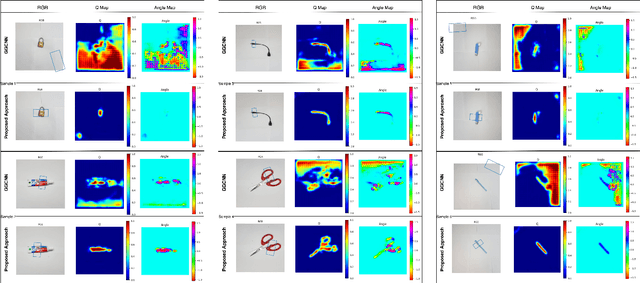
For a robot to perform complex manipulation tasks, it is necessary for it to have a good grasping ability. However, vision based robotic grasp detection is hindered by the unavailability of sufficient labelled data. Furthermore, the application of semi-supervised learning techniques to grasp detection is under-explored. In this paper, a semi-supervised learning based grasp detection approach has been presented, which models a discrete latent space using a Vector Quantized Variational AutoEncoder (VQ-VAE). To the best of our knowledge, this is the first time a Variational AutoEncoder (VAE) has been applied in the domain of robotic grasp detection. The VAE helps the model in generalizing beyond the Cornell Grasping Dataset (CGD) despite having a limited amount of labelled data by also utilizing the unlabelled data. This claim has been validated by testing the model on images, which are not available in the CGD. Along with this, we augment the Generative Grasping Convolutional Neural Network (GGCNN) architecture with the decoder structure used in the VQ-VAE model with the intuition that it should help to regress in the vector-quantized latent space. Subsequently, the model performs significantly better than the existing approaches which do not make use of unlabelled images to improve the grasp.