 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Control Barrier Function Regulation with Vision-Language Models for Safe, Adaptive, and Realtime Visual Navigation
Mar 22, 2026Robots operating in dynamic, unstructured environments must balance safety and efficiency under potentially limited sensing. While control barrier functions (CBFs) provide principled collision avoidance via safety filtering, their behavior is often governed by fixed parameters that can be overly conservative in benign scenes or overly permissive near hazards. We present AlphaAdj, a vision-to-control navigation framework that uses egocentric RGB input to adapt the conservativeness of a CBF safety filter in real time. A vision-language model(VLM) produces a bounded scalar risk estimate from the current camera view, which we map to dynamically update a CBF parameter that modulates how strongly safety constraints are enforced. To address asynchronous inference and non-trivial VLM latency in practice, we combine a geometric, speed-aware dynamic cap and a staleness-gated fusion policy with lightweight implementation choices that reduce end-to-end inference overhead. We evaluate AlphaAdj across multiple static and dynamic obstacle scenarios in a variety of environments, comparing against fixed-parameter and uncapped ablations. Results show that AlphaAdj maintains collision-free navigation while improving efficiency (in terms of path length and time to goal) by up to 18.5% relative to fixed settings and improving robustness and success rate relative to an uncapped baseline.
Empowering Dynamic Urban Navigation with Stereo and Mid-Level Vision
Dec 11, 2025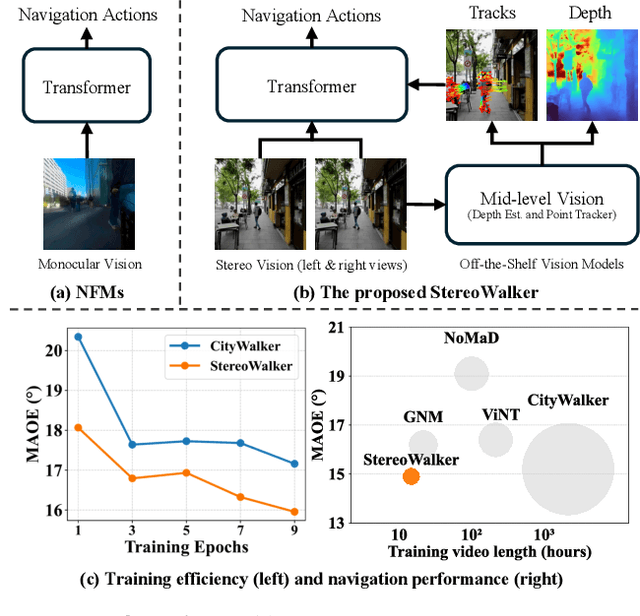
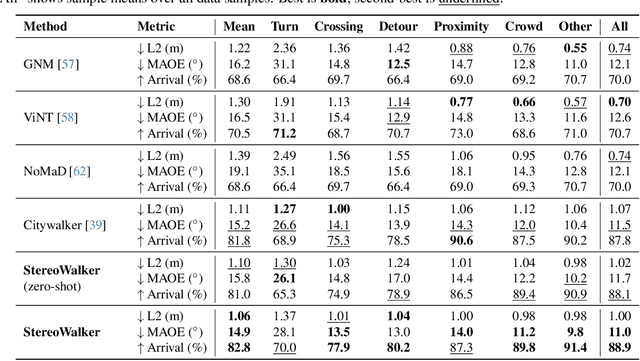
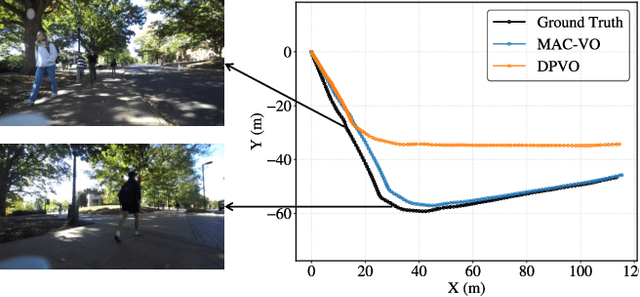
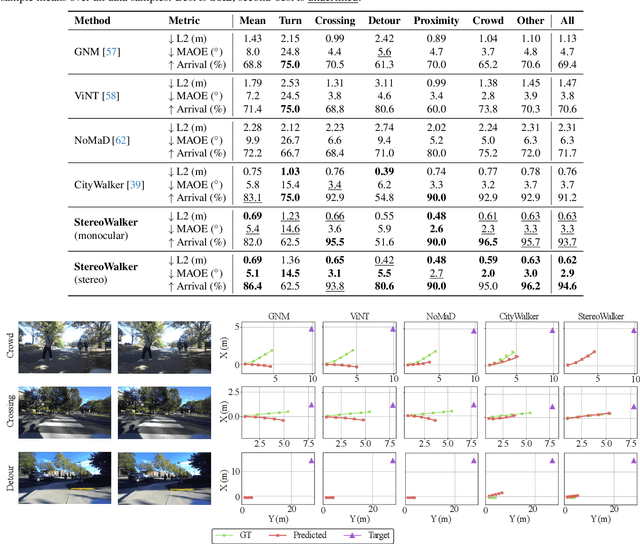
The success of foundation models in language and vision motivated research in fully end-to-end robot navigation foundation models (NFMs). NFMs directly map monocular visual input to control actions and ignore mid-level vision modules (tracking, depth estimation, etc) entirely. While the assumption that vision capabilities will emerge implicitly is compelling, it requires large amounts of pixel-to-action supervision that are difficult to obtain. The challenge is especially pronounced in dynamic and unstructured settings, where robust navigation requires precise geometric and dynamic understanding, while the depth-scale ambiguity in monocular views further limits accurate spatial reasoning. In this paper, we show that relying on monocular vision and ignoring mid-level vision priors is inefficient. We present StereoWalker, which augments NFMs with stereo inputs and explicit mid-level vision such as depth estimation and dense pixel tracking. Our intuition is straightforward: stereo inputs resolve the depth-scale ambiguity, and modern mid-level vision models provide reliable geometric and motion structure in dynamic scenes. We also curate a large stereo navigation dataset with automatic action annotation from Internet stereo videos to support training of StereoWalker and to facilitate future research. Through our experiments, we find that mid-level vision enables StereoWalker to achieve a comparable performance as the state-of-the-art using only 1.5% of the training data, and surpasses the state-of-the-art using the full data. We also observe that stereo vision yields higher navigation performance than monocular input.
FACA: Fair and Agile Multi-Robot Collision Avoidance in Constrained Environments with Dynamic Priorities
Nov 18, 2025



Multi-robot systems are increasingly being used for critical applications such as rescuing injured people, delivering food and medicines, and monitoring key areas. These applications usually involve navigating at high speeds through constrained spaces such as small gaps. Navigating such constrained spaces becomes particularly challenging when the space is crowded with multiple heterogeneous agents all of which have urgent priorities. What makes the problem even harder is that during an active response situation, roles and priorities can quickly change on a dime without informing the other agents. In order to complete missions in such environments, robots must not only be safe, but also agile, able to dodge and change course at a moment's notice. In this paper, we propose FACA, a fair and agile collision avoidance approach where robots coordinate their tasks by talking to each other via natural language (just as people do). In FACA, robots balance safety with agility via a novel artificial potential field algorithm that creates an automatic ``roundabout'' effect whenever a conflict arises. Our experiments show that FACA achieves a improvement in efficiency, completing missions more than 3.5X faster than baselines with a time reduction of over 70% while maintaining robust safety margins.
Prompt-Driven Domain Adaptation for End-to-End Autonomous Driving via In-Context RL
Nov 16, 2025
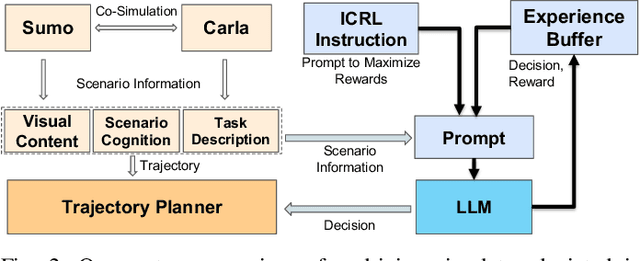


Despite significant progress and advances in autonomous driving, many end-to-end systems still struggle with domain adaptation (DA), such as transferring a policy trained under clear weather to adverse weather conditions. Typical DA strategies in the literature include collecting additional data in the target domain or re-training the model, or both. Both these strategies quickly become impractical as we increase scale and complexity of driving. These limitations have encouraged investigation into few-shot and zero-shot prompt-driven DA at inference time involving LLMs and VLMs. These methods work by adding a few state-action trajectories during inference to the prompt (similar to in-context learning). However, there are two limitations of such an approach: $(i)$ prompt-driven DA methods are currently restricted to perception tasks such as detection and segmentation and $(ii)$ they require expert few-shot data. In this work, we present a new approach to inference-time few-shot prompt-driven DA for closed-loop autonomous driving in adverse weather condition using in-context reinforcement learning (ICRL). Similar to other prompt-driven DA methods, our approach does not require any updates to the model parameters nor does it require additional data collection in adversarial weather regime. Furthermore, our approach advances the state-of-the-art in prompt-driven DA by extending to closed driving using general trajectories observed during inference. Our experiments using the CARLA simulator show that ICRL results in safer, more efficient, and more comfortable driving policies in the target domain compared to state-of-the-art prompt-driven DA baselines.
Are LLMs The Way Forward? A Case Study on LLM-Guided Reinforcement Learning for Decentralized Autonomous Driving
Nov 16, 2025Autonomous vehicle navigation in complex environments such as dense and fast-moving highways and merging scenarios remains an active area of research. A key limitation of RL is its reliance on well-specified reward functions, which often fail to capture the full semantic and social complexity of diverse, out-of-distribution situations. As a result, a rapidly growing line of research explores using Large Language Models (LLMs) to replace or supplement RL for direct planning and control, on account of their ability to reason about rich semantic context. However, LLMs present significant drawbacks: they can be unstable in zero-shot safety-critical settings, produce inconsistent outputs, and often depend on expensive API calls with network latency. This motivates our investigation into whether small, locally deployed LLMs (< 14B parameters) can meaningfully support autonomous highway driving through reward shaping rather than direct control. We present a case study comparing RL-only, LLM-only, and hybrid approaches, where LLMs augment RL rewards by scoring state-action transitions during training, while standard RL policies execute at test time. Our findings reveal that RL-only agents achieve moderate success rates (73-89%) with reasonable efficiency, LLM-only agents can reach higher success rates (up to 94%) but with severely degraded speed performance, and hybrid approaches consistently fall between these extremes. Critically, despite explicit efficiency instructions, LLM-influenced approaches exhibit systematic conservative bias with substantial model-dependent variability, highlighting important limitations of current small LLMs for safety-critical control tasks.
DR. Nav: Semantic-Geometric Representations for Proactive Dead-End Recovery and Navigation
Nov 16, 2025We present DR. Nav (Dead-End Recovery-aware Navigation), a novel approach to autonomous navigation in scenarios where dead-end detection and recovery are critical, particularly in unstructured environments where robots must handle corners, vegetation occlusions, and blocked junctions. DR. Nav introduces a proactive strategy for navigation in unmapped environments without prior assumptions. Our method unifies dead-end prediction and recovery by generating a single, continuous, real-time semantic cost map. Specifically, DR. Nav leverages cross-modal RGB-LiDAR fusion with attention-based filtering to estimate per-cell dead-end likelihoods and recovery points, which are continuously updated through Bayesian inference to enhance robustness. Unlike prior mapping methods that only encode traversability, DR. Nav explicitly incorporates recovery-aware risk into the navigation cost map, enabling robots to anticipate unsafe regions and plan safer alternative trajectories. We evaluate DR. Nav across multiple dense indoor and outdoor scenarios and demonstrate an increase of 83.33% in accuracy in detection, a 52.4% reduction in time-to-goal (path efficiency), compared to state-of-the-art planners such as DWA, MPPI, and Nav2 DWB. Furthermore, the dead-end classifier functions
Finite Sample Analysis of Linear Temporal Difference Learning with Arbitrary Features
May 27, 2025Linear TD($\lambda$) is one of the most fundamental reinforcement learning algorithms for policy evaluation. Previously, convergence rates are typically established under the assumption of linearly independent features, which does not hold in many practical scenarios. This paper instead establishes the first $L^2$ convergence rates for linear TD($\lambda$) operating under arbitrary features, without making any algorithmic modification or additional assumptions. Our results apply to both the discounted and average-reward settings. To address the potential non-uniqueness of solutions resulting from arbitrary features, we develop a novel stochastic approximation result featuring convergence rates to the solution set instead of a single point.
Experience Replay Addresses Loss of Plasticity in Continual Learning
Mar 25, 2025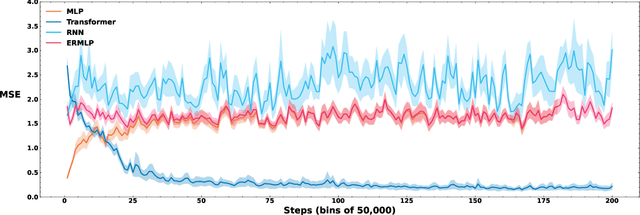
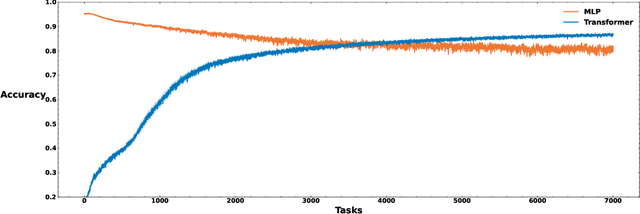
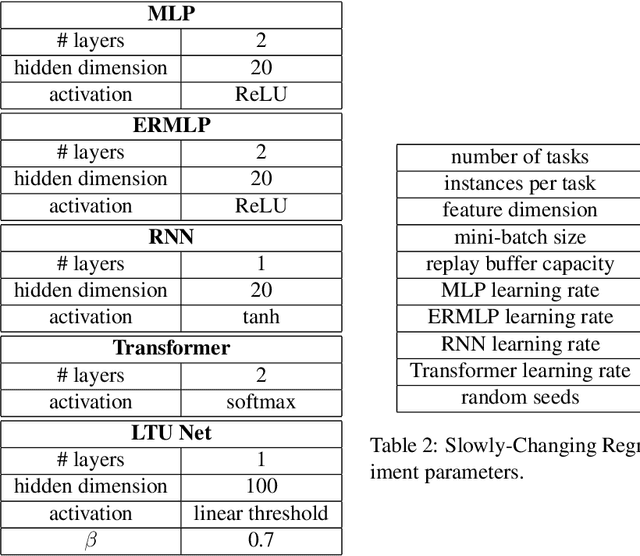
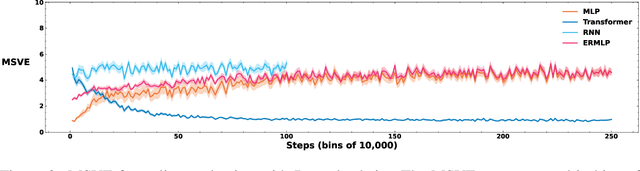
Loss of plasticity is one of the main challenges in continual learning with deep neural networks, where neural networks trained via backpropagation gradually lose their ability to adapt to new tasks and perform significantly worse than their freshly initialized counterparts. The main contribution of this paper is to propose a new hypothesis that experience replay addresses the loss of plasticity in continual learning. Here, experience replay is a form of memory. We provide supporting evidence for this hypothesis. In particular, we demonstrate in multiple different tasks, including regression, classification, and policy evaluation, that by simply adding an experience replay and processing the data in the experience replay with Transformers, the loss of plasticity disappears. Notably, we do not alter any standard components of deep learning. For example, we do not change backpropagation. We do not modify the activation functions. And we do not use any regularization. We conjecture that experience replay and Transformers can address the loss of plasticity because of the in-context learning phenomenon.
LIVEPOINT: Fully Decentralized, Safe, Deadlock-Free Multi-Robot Control in Cluttered Environments with High-Dimensional Inputs
Mar 17, 2025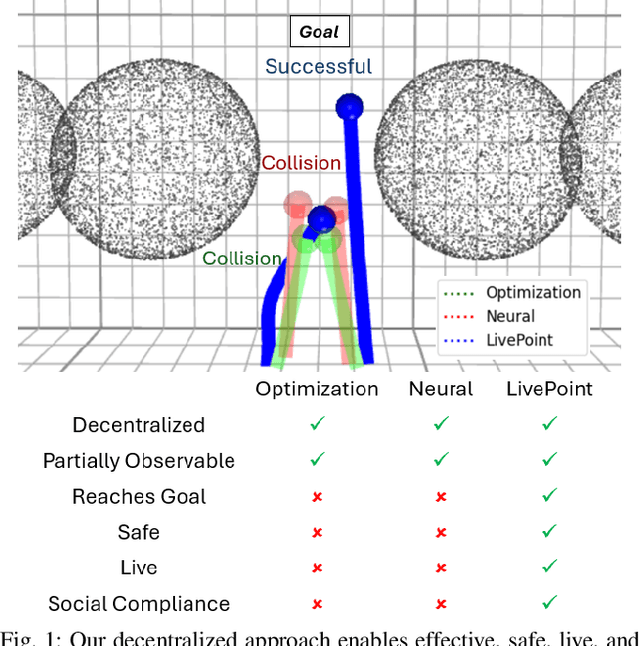
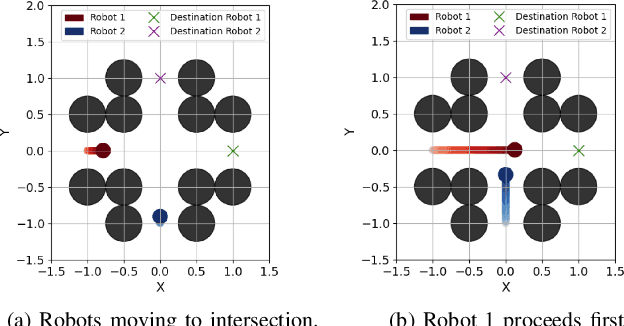
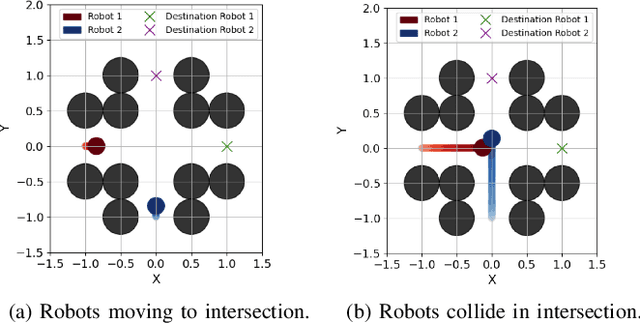
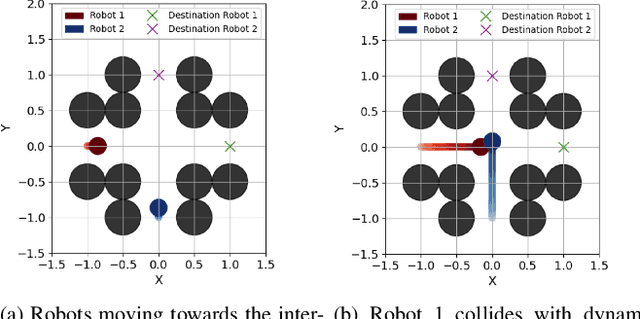
Fully decentralized, safe, and deadlock-free multi-robot navigation in dynamic, cluttered environments is a critical challenge in robotics. Current methods require exact state measurements in order to enforce safety and liveness e.g. via control barrier functions (CBFs), which is challenging to achieve directly from onboard sensors like lidars and cameras. This work introduces LIVEPOINT, a decentralized control framework that synthesizes universal CBFs over point clouds to enable safe, deadlock-free real-time multi-robot navigation in dynamic, cluttered environments. Further, LIVEPOINT ensures minimally invasive deadlock avoidance behavior by dynamically adjusting agents' speeds based on a novel symmetric interaction metric. We validate our approach in simulation experiments across highly constrained multi-robot scenarios like doorways and intersections. Results demonstrate that LIVEPOINT achieves zero collisions or deadlocks and a 100% success rate in challenging settings compared to optimization-based baselines such as MPC and ORCA and neural methods such as MPNet, which fail in such environments. Despite prioritizing safety and liveness, LIVEPOINT is 35% smoother than baselines in the doorway environment, and maintains agility in constrained environments while still being safe and deadlock-free.
GameChat: Multi-LLM Dialogue for Safe, Agile, and Socially Optimal Multi-Agent Navigation in Constrained Environments
Mar 16, 2025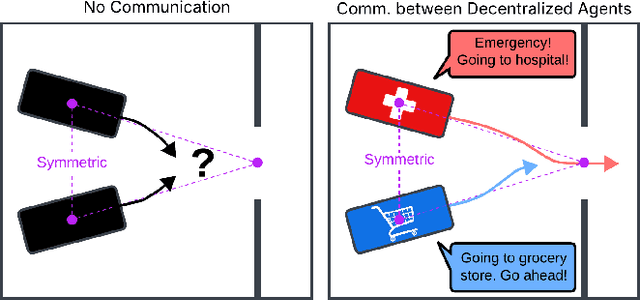
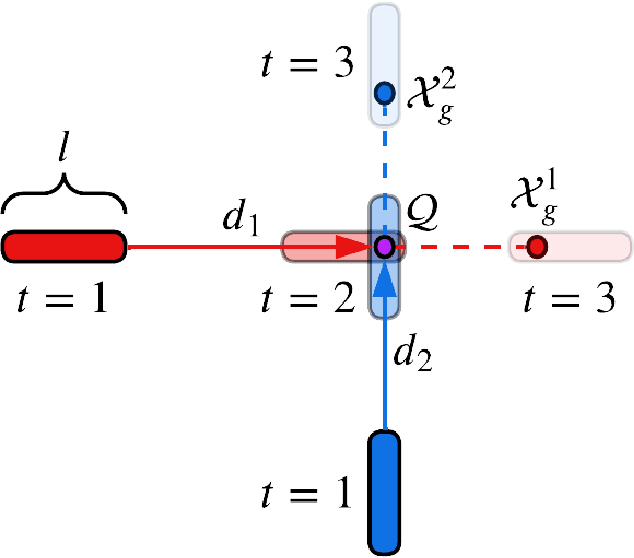
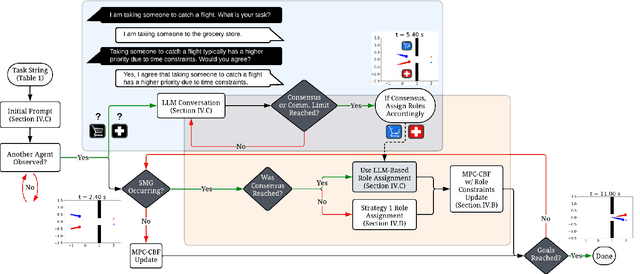
Safe, agile, and socially compliant multi-robot navigation in cluttered and constrained environments remains a critical challenge. This is especially difficult with self-interested agents in decentralized settings, where there is no central authority to resolve conflicts induced by spatial symmetry. We address this challenge by proposing a novel approach, GameChat, which facilitates safe, agile, and deadlock-free navigation for both cooperative and self-interested agents. Key to our approach is the use of natural language communication to resolve conflicts, enabling agents to prioritize more urgent tasks and break spatial symmetry in a socially optimal manner. Our algorithm ensures subgame perfect equilibrium, preventing agents from deviating from agreed-upon behaviors and supporting cooperation. Furthermore, we guarantee safety through control barrier functions and preserve agility by minimizing disruptions to agents' planned trajectories. We evaluate GameChat in simulated environments with doorways and intersections. The results show that even in the worst case, GameChat reduces the time for all agents to reach their goals by over 35% from a naive baseline and by over 20% from SMG-CBF in the intersection scenario, while doubling the rate of ensuring the agent with a higher priority task reaches the goal first, from 50% (equivalent to random chance) to a 100% perfect performance at maximizing social welfare.