 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias in the Loop: How Humans Evaluate AI-Generated Suggestions
Sep 10, 2025Human-AI collaboration increasingly drives decision-making across industries, from medical diagnosis to content moderation. While AI systems promise efficiency gains by providing automated suggestions for human review, these workflows can trigger cognitive biases that degrade performance. We know little about the psychological factors that determine when these collaborations succeed or fail. We conducted a randomized experiment with 2,784 participants to examine how task design and individual characteristics shape human responses to AI-generated suggestions. Using a controlled annotation task, we manipulated three factors: AI suggestion quality in the first three instances, task burden through required corrections, and performance-based financial incentives. We collected demographics, attitudes toward AI, and behavioral data to assess four performance metrics: accuracy, correction activity, overcorrection, and undercorrection. Two patterns emerged that challenge conventional assumptions about human-AI collaboration. First, requiring corrections for flagged AI errors reduced engagement and increased the tendency to accept incorrect suggestions, demonstrating how cognitive shortcuts influence collaborative outcomes. Second, individual attitudes toward AI emerged as the strongest predictor of performance, surpassing demographic factors. Participants skeptical of AI detected errors more reliably and achieved higher accuracy, while those favorable toward automation exhibited dangerous overreliance on algorithmic suggestions. The findings reveal that successful human-AI collaboration depends not only on algorithmic performance but also on who reviews AI outputs and how review processes are structured. Effective human-AI collaborations require consideration of human psychology: selecting diverse evaluator samples, measuring attitudes, and designing workflows that counteract cognitive biases.
SFO: Piloting VLM Feedback for Offline RL
Mar 02, 2025While internet-scale image and textual data have enabled strong generalization in Vision-Language Models (VLMs), the absence of internet-scale control data has impeded the development of similar generalization in standard reinforcement learning (RL) agents. Although VLMs are fundamentally limited in their ability to solve control tasks due to their lack of action-conditioned training data, their capacity for image understanding allows them to provide valuable feedback in RL tasks by recognizing successful outcomes. A key challenge in Reinforcement Learning from AI Feedback (RLAIF) is determining how best to integrate VLM-derived signals into the learning process. We explore this question in the context of offline RL and introduce a class of methods called sub-trajectory filtered optimization. We identify three key insights. First, trajectory length plays a crucial role in offline RL, as full-trajectory preference learning exacerbates the stitching problem, necessitating the use of sub-trajectories. Second, even in Markovian environments, a non-Markovian reward signal from a sequence of images is required to assess trajectory improvement, as VLMs do not interpret control actions and must rely on visual cues over time. Third, a simple yet effective approach--filtered and weighted behavior cloning--consistently outperforms more complex reinforcement learning from human feedback-based methods. We propose sub-trajectory filtered behavior cloning, a method that leverages VLM feedback on sub-trajectories while incorporating a retrospective filtering mechanism that removes sub-trajectories preceding failures to improve robustness and prevent turbulence. This study is preliminary; we provide initial evidence through evaluations on a toy control domain. Please enjoy our airport puns.
A Survey of In-Context Reinforcement Learning
Feb 11, 2025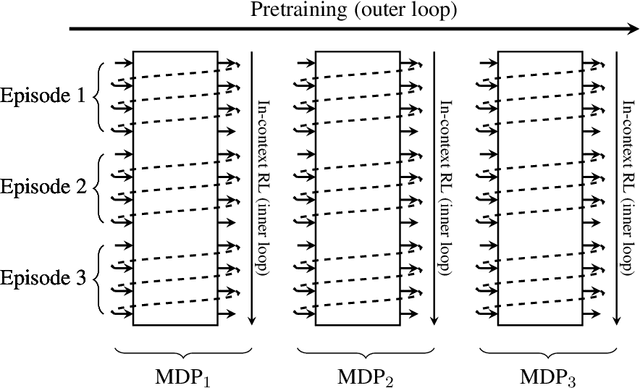
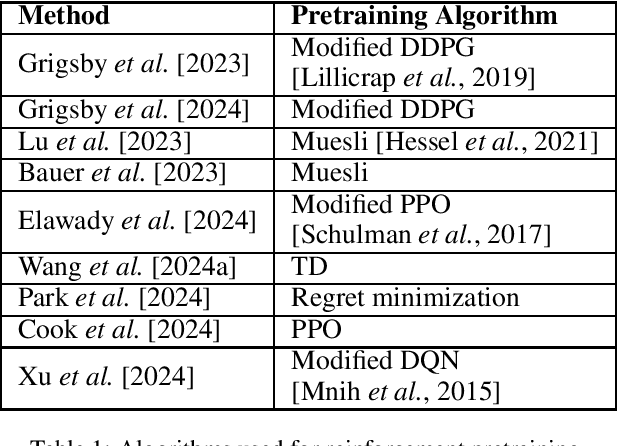
Reinforcement learning (RL) agents typically optimize their policies by performing expensive backward passes to update their network parameters. However, some agents can solve new tasks without updating any parameters by simply conditioning on additional context such as their action-observation histories. This paper surveys work on such behavior, known as in-context reinforcement learning.
Metalic: Meta-Learning In-Context with Protein Language Models
Oct 10, 2024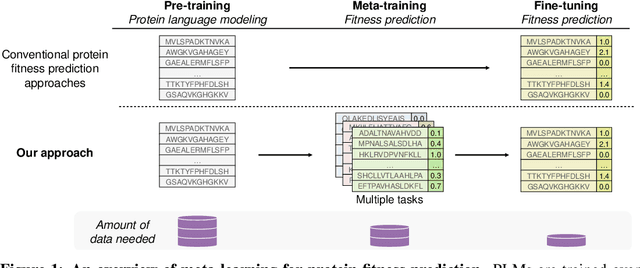
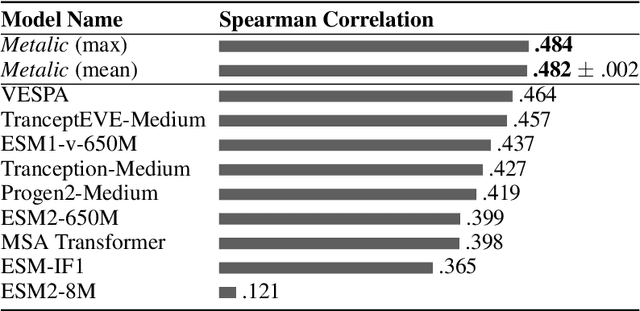
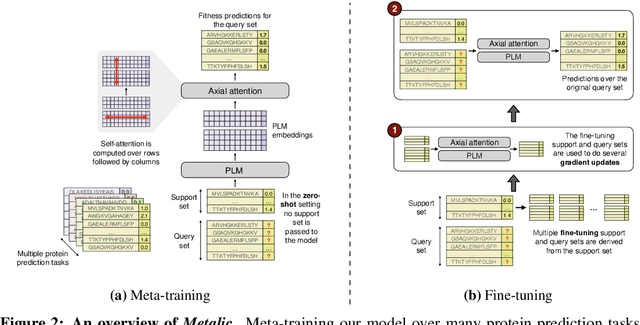

Predicting the biophysical and functional properties of proteins is essential for in silico protein design. Machine learning has emerged as a promising technique for such prediction tasks. However, the relative scarcity of in vitro annotations means that these models often have little, or no, specific data on the desired fitness prediction task. As a result of limited data, protein language models (PLMs) are typically trained on general protein sequence modeling tasks, and then fine-tuned, or applied zero-shot, to protein fitness prediction. When no task data is available, the models make strong assumptions about the correlation between the protein sequence likelihood and fitness scores. In contrast, we propose meta-learning over a distribution of standard fitness prediction tasks, and demonstrate positive transfer to unseen fitness prediction tasks. Our method, called Metalic (Meta-Learning In-Context), uses in-context learning and fine-tuning, when data is available, to adapt to new tasks. Crucially, fine-tuning enables considerable generalization, even though it is not accounted for during meta-training. Our fine-tuned models achieve strong results with 18 times fewer parameters than state-of-the-art models. Moreover, our method sets a new state-of-the-art in low-data settings on ProteinGym, an established fitness-prediction benchmark. Due to data scarcity, we believe meta-learning will play a pivotal role in advancing protein engineering.
SplAgger: Split Aggregation for Meta-Reinforcement Learning
Mar 08, 2024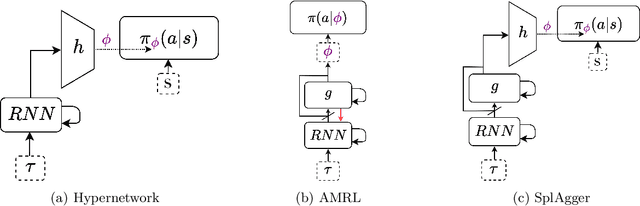
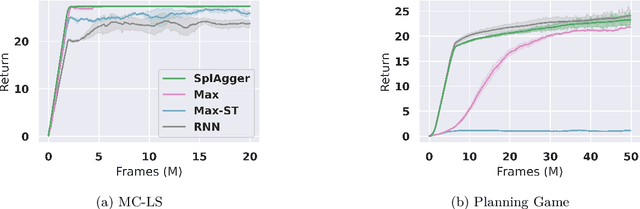
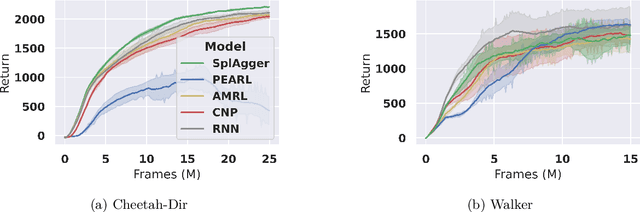
A core ambition of reinforcement learning (RL) is the creation of agents capable of rapid learning in novel tasks. Meta-RL aims to achieve this by directly learning such agents. Black box methods do so by training off-the-shelf sequence models end-to-end. By contrast, task inference methods explicitly infer a posterior distribution over the unknown task, typically using distinct objectives and sequence models designed to enable task inference. Recent work has shown that task inference methods are not necessary for strong performance. However, it remains unclear whether task inference sequence models are beneficial even when task inference objectives are not. In this paper, we present strong evidence that task inference sequence models are still beneficial. In particular, we investigate sequence models with permutation invariant aggregation, which exploit the fact that, due to the Markov property, the task posterior does not depend on the order of data. We empirically confirm the advantage of permutation invariant sequence models without the use of task inference objectives. However, we also find, surprisingly, that there are multiple conditions under which permutation variance remains useful. Therefore, we propose SplAgger, which uses both permutation variant and invariant components to achieve the best of both worlds, outperforming all baselines on continuous control and memory environments.
Distilling Morphology-Conditioned Hypernetworks for Efficient Universal Morphology Control
Feb 09, 2024

Learning a universal policy across different robot morphologies can significantly improve learning efficiency and enable zero-shot generalization to unseen morphologies. However, learning a highly performant universal policy requires sophisticated architectures like transformers (TF) that have larger memory and computational cost than simpler multi-layer perceptrons (MLP). To achieve both good performance like TF and high efficiency like MLP at inference time, we propose HyperDistill, which consists of: (1) A morphology-conditioned hypernetwork (HN) that generates robot-wise MLP policies, and (2) A policy distillation approach that is essential for successful training. We show that on UNIMAL, a benchmark with hundreds of diverse morphologies, HyperDistill performs as well as a universal TF teacher policy on both training and unseen test robots, but reduces model size by 6-14 times, and computational cost by 67-160 times in different environments. Our analysis attributes the efficiency advantage of HyperDistill at inference time to knowledge decoupling, i.e., the ability to decouple inter-task and intra-task knowledge, a general principle that could also be applied to improve inference efficiency in other domains.
Annotation Sensitivity: Training Data Collection Methods Affect Model Performance
Nov 23, 2023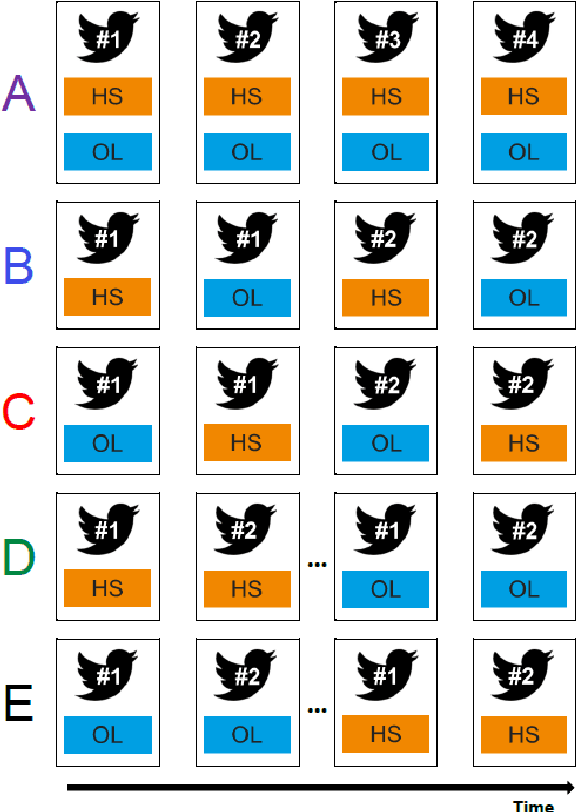
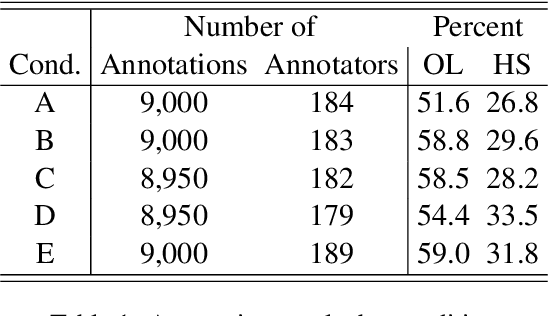
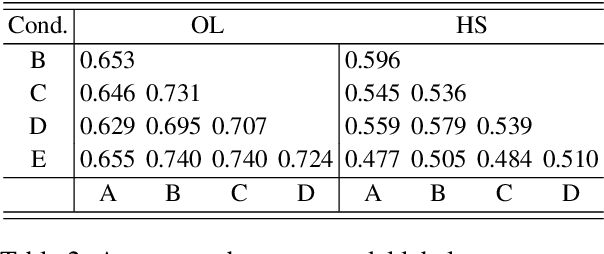
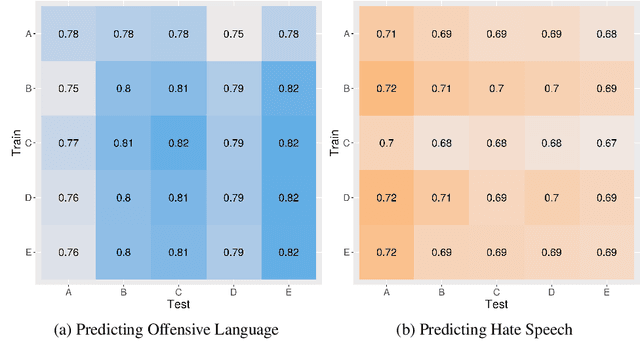
When training data are collected from human annotators, the design of the annotation instrument, the instructions given to annotators, the characteristics of the annotators, and their interactions can impact training data. This study demonstrates that design choices made when creating an annotation instrument also impact the models trained on the resulting annotations. We introduce the term annotation sensitivity to refer to the impact of annotation data collection methods on the annotations themselves and on downstream model performance and predictions. We collect annotations of hate speech and offensive language in five experimental conditions of an annotation instrument, randomly assigning annotators to conditions. We then fine-tune BERT models on each of the five resulting datasets and evaluate model performance on a holdout portion of each condition. We find considerable differences between the conditions for 1) the share of hate speech/offensive language annotations, 2) model performance, 3) model predictions, and 4) model learning curves. Our results emphasize the crucial role played by the annotation instrument which has received little attention in the machine learning literature. We call for additional research into how and why the instrument impacts the annotations to inform the development of best practices in instrument design.
Recurrent Hypernetworks are Surprisingly Strong in Meta-RL
Sep 26, 2023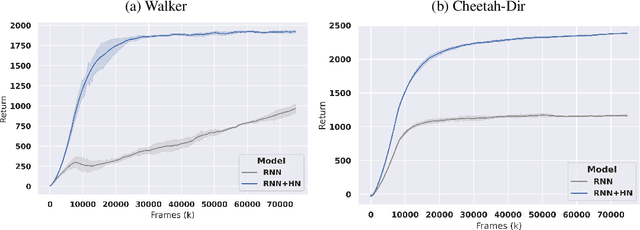
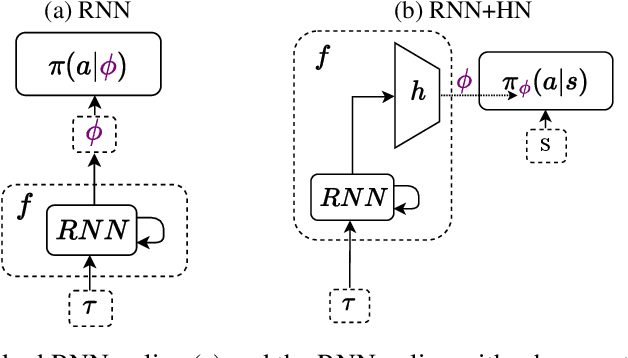
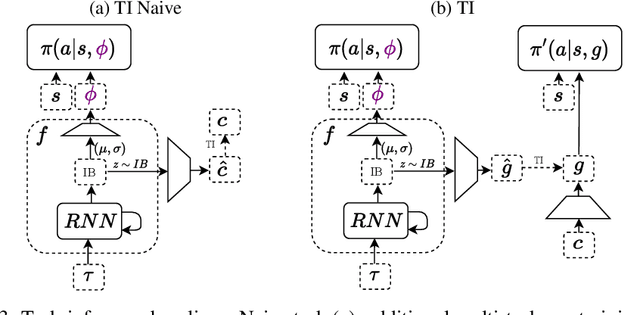
Deep reinforcement learning (RL) is notoriously impractical to deploy due to sample inefficiency. Meta-RL directly addresses this sample inefficiency by learning to perform few-shot learning when a distribution of related tasks is available for meta-training. While many specialized meta-RL methods have been proposed, recent work suggests that end-to-end learning in conjunction with an off-the-shelf sequential model, such as a recurrent network, is a surprisingly strong baseline. However, such claims have been controversial due to limited supporting evidence, particularly in the face of prior work establishing precisely the opposite. In this paper, we conduct an empirical investigation. While we likewise find that a recurrent network can achieve strong performance, we demonstrate that the use of hypernetworks is crucial to maximizing their potential. Surprisingly, when combined with hypernetworks, the recurrent baselines that are far simpler than existing specialized methods actually achieve the strongest performance of all methods evaluated.
Universal Morphology Control via Contextual Modulation
Feb 22, 2023



Learning a universal policy across different robot morphologies can significantly improve learning efficiency and generalization in continuous control. However, it poses a challenging multi-task reinforcement learning problem, as the optimal policy may be quite different across robots and critically depend on the morphology. Existing methods utilize graph neural networks or transformers to handle heterogeneous state and action spaces across different morphologies, but pay little attention to the dependency of a robot's control policy on its morphology context. In this paper, we propose a hierarchical architecture to better model this dependency via contextual modulation, which includes two key submodules: (1) Instead of enforcing hard parameter sharing across robots, we use hypernetworks to generate morphology-dependent control parameters; (2) We propose a morphology-dependent attention mechanism to modulate the interactions between different limbs in a robot. Experimental results show that our method not only improves learning performance on a diverse set of training robots, but also generalizes better to unseen morphologies in a zero-shot fashion.
A Survey of Meta-Reinforcement Learning
Jan 19, 2023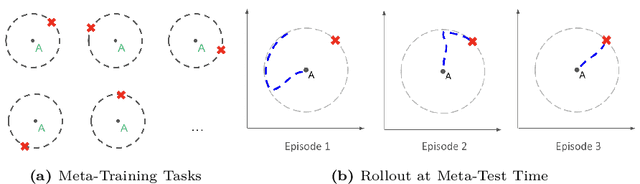
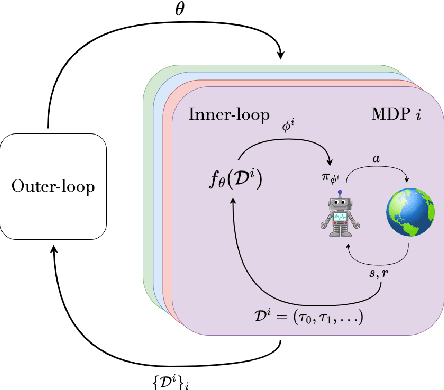

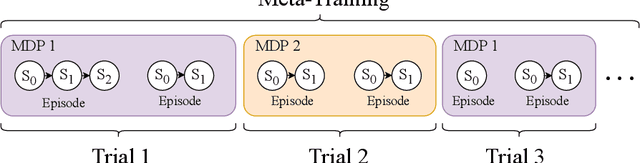
While deep reinforcement learning (RL) has fueled multiple high-profile successes in machine learning, it is held back from more widespread adoption by its often poor data efficiency and the limited generality of the policies it produces. A promising approach for alleviating these limitations is to cast the development of better RL algorithms as a machine learning problem itself in a process called meta-RL. Meta-RL is most commonly studied in a problem setting where, given a distribution of tasks, the goal is to learn a policy that is capable of adapting to any new task from the task distribution with as little data as possible. In this survey, we describe the meta-RL problem setting in detail as well as its major variations. We discuss how, at a high level, meta-RL research can be clustered based on the presence of a task distribution and the learning budget available for each individual task. Using these clusters, we then survey meta-RL algorithms and applications. We conclude by presenting the open problems on the path to making meta-RL part of the standard toolbox for a deep RL practitioner.