 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Clean Slate for Offline Reinforcement Learning
Apr 15, 2025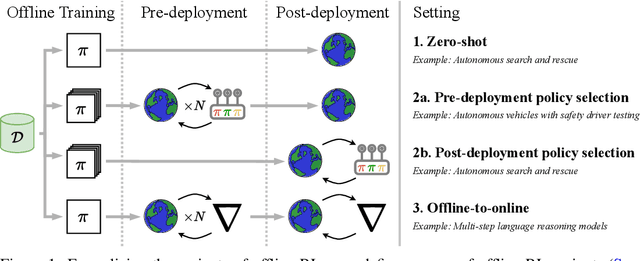

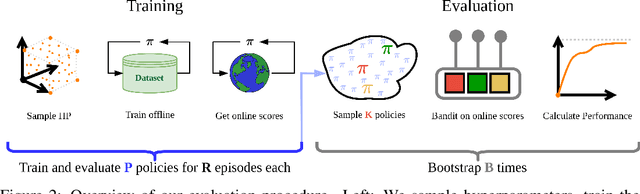

Progress in offline reinforcement learning (RL) has been impeded by ambiguous problem definitions and entangled algorithmic designs, resulting in inconsistent implementations, insufficient ablations, and unfair evaluations. Although offline RL explicitly avoids environment interaction, prior methods frequently employ extensive, undocumented online evaluation for hyperparameter tuning, complicating method comparisons. Moreover, existing reference implementations differ significantly in boilerplate code, obscuring their core algorithmic contributions. We address these challenges by first introducing a rigorous taxonomy and a transparent evaluation protocol that explicitly quantifies online tuning budgets. To resolve opaque algorithmic design, we provide clean, minimalistic, single-file implementations of various model-free and model-based offline RL methods, significantly enhancing clarity and achieving substantial speed-ups. Leveraging these streamlined implementations, we propose Unifloral, a unified algorithm that encapsulates diverse prior approaches within a single, comprehensive hyperparameter space, enabling algorithm development in a shared hyperparameter space. Using Unifloral with our rigorous evaluation protocol, we develop two novel algorithms - TD3-AWR (model-free) and MoBRAC (model-based) - which substantially outperform established baselines. Our implementation is publicly available at https://github.com/EmptyJackson/unifloral.
Judge a Book by its Cover: Investigating Multi-Modal LLMs for Multi-Page Handwritten Document Transcription
Feb 27, 2025Handwritten text recognition (HTR) remains a challenging task, particularly for multi-page documents where pages share common formatting and contextual features. While modern optical character recognition (OCR) engines are proficient with printed text, their performance on handwriting is limited, often requiring costly labeled data for fine-tuning. In this paper, we explore the use of multi-modal large language models (MLLMs) for transcribing multi-page handwritten documents in a zero-shot setting. We investigate various configurations of commercial OCR engines and MLLMs, utilizing the latter both as end-to-end transcribers and as post-processors, with and without image components. We propose a novel method, '+first page', which enhances MLLM transcription by providing the OCR output of the entire document along with just the first page image. This approach leverages shared document features without incurring the high cost of processing all images. Experiments on a multi-page version of the IAM Handwriting Database demonstrate that '+first page' improves transcription accuracy, balances cost with performance, and even enhances results on out-of-sample text by extrapolating formatting and OCR error patterns from a single page.
Can Learned Optimization Make Reinforcement Learning Less Difficult?
Jul 09, 2024While reinforcement learning (RL) holds great potential for decision making in the real world, it suffers from a number of unique difficulties which often need specific consideration. In particular: it is highly non-stationary; suffers from high degrees of plasticity loss; and requires exploration to prevent premature convergence to local optima and maximize return. In this paper, we consider whether learned optimization can help overcome these problems. Our method, Learned Optimization for Plasticity, Exploration and Non-stationarity (OPEN), meta-learns an update rule whose input features and output structure are informed by previously proposed solutions to these difficulties. We show that our parameterization is flexible enough to enable meta-learning in diverse learning contexts, including the ability to use stochasticity for exploration. Our experiments demonstrate that when meta-trained on single and small sets of environments, OPEN outperforms or equals traditionally used optimizers. Furthermore, OPEN shows strong generalization across a distribution of environments and a range of agent architectures.
Policy-Guided Diffusion
Apr 09, 2024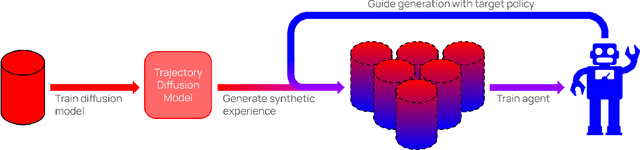


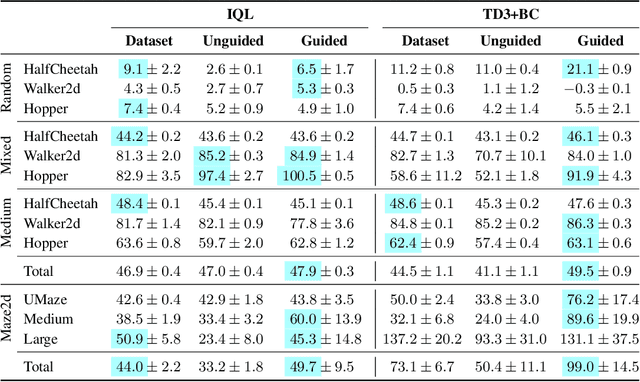
In many real-world settings, agents must learn from an offline dataset gathered by some prior behavior policy. Such a setting naturally leads to distribution shift between the behavior policy and the target policy being trained - requiring policy conservatism to avoid instability and overestimation bias. Autoregressive world models offer a different solution to this by generating synthetic, on-policy experience. However, in practice, model rollouts must be severely truncated to avoid compounding error. As an alternative, we propose policy-guided diffusion. Our method uses diffusion models to generate entire trajectories under the behavior distribution, applying guidance from the target policy to move synthetic experience further on-policy. We show that policy-guided diffusion models a regularized form of the target distribution that balances action likelihood under both the target and behavior policies, leading to plausible trajectories with high target policy probability, while retaining a lower dynamics error than an offline world model baseline. Using synthetic experience from policy-guided diffusion as a drop-in substitute for real data, we demonstrate significant improvements in performance across a range of standard offline reinforcement learning algorithms and environments. Our approach provides an effective alternative to autoregressive offline world models, opening the door to the controllable generation of synthetic training data.
Discovering Temporally-Aware Reinforcement Learning Algorithms
Feb 08, 2024Recent advancements in meta-learning have enabled the automatic discovery of novel reinforcement learning algorithms parameterized by surrogate objective functions. To improve upon manually designed algorithms, the parameterization of this learned objective function must be expressive enough to represent novel principles of learning (instead of merely recovering already established ones) while still generalizing to a wide range of settings outside of its meta-training distribution. However, existing methods focus on discovering objective functions that, like many widely used objective functions in reinforcement learning, do not take into account the total number of steps allowed for training, or "training horizon". In contrast, humans use a plethora of different learning objectives across the course of acquiring a new ability. For instance, students may alter their studying techniques based on the proximity to exam deadlines and their self-assessed capabilities. This paper contends that ignoring the optimization time horizon significantly restricts the expressive potential of discovered learning algorithms. We propose a simple augmentation to two existing objective discovery approaches that allows the discovered algorithm to dynamically update its objective function throughout the agent's training procedure, resulting in expressive schedules and increased generalization across different training horizons. In the process, we find that commonly used meta-gradient approaches fail to discover such adaptive objective functions while evolution strategies discover highly dynamic learning rules. We demonstrate the effectiveness of our approach on a wide range of tasks and analyze the resulting learned algorithms, which we find effectively balance exploration and exploitation by modifying the structure of their learning rules throughout the agent's lifetime.
Discovering General Reinforcement Learning Algorithms with Adversarial Environment Design
Oct 04, 2023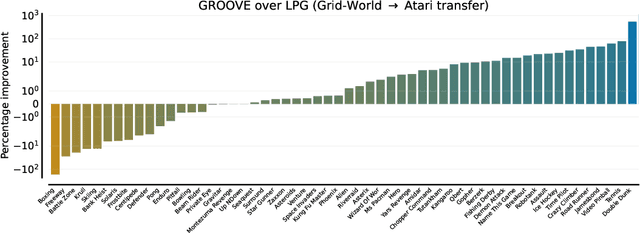
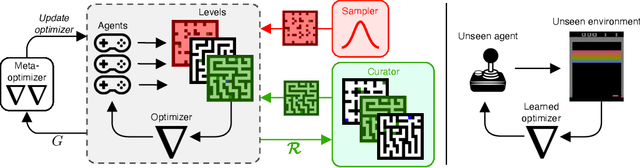

The past decade has seen vast progress in deep reinforcement learning (RL) on the back of algorithms manually designed by human researchers. Recently, it has been shown that it is possible to meta-learn update rules, with the hope of discovering algorithms that can perform well on a wide range of RL tasks. Despite impressive initial results from algorithms such as Learned Policy Gradient (LPG), there remains a generalization gap when these algorithms are applied to unseen environments. In this work, we examine how characteristics of the meta-training distribution impact the generalization performance of these algorithms. Motivated by this analysis and building on ideas from Unsupervised Environment Design (UED), we propose a novel approach for automatically generating curricula to maximize the regret of a meta-learned optimizer, in addition to a novel approximation of regret, which we name algorithmic regret (AR). The result is our method, General RL Optimizers Obtained Via Environment Design (GROOVE). In a series of experiments, we show that GROOVE achieves superior generalization to LPG, and evaluate AR against baseline metrics from UED, identifying it as a critical component of environment design in this setting. We believe this approach is a step towards the discovery of truly general RL algorithms, capable of solving a wide range of real-world environments.
Hypernetworks in Meta-Reinforcement Learning
Oct 20, 2022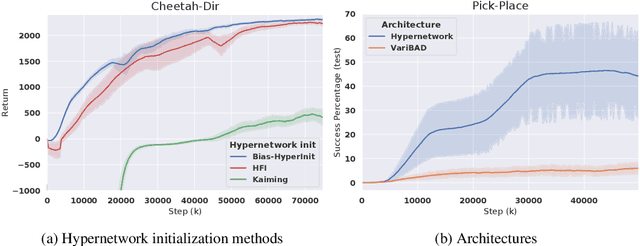



Training a reinforcement learning (RL) agent on a real-world robotics task remains generally impractical due to sample inefficiency. Multi-task RL and meta-RL aim to improve sample efficiency by generalizing over a distribution of related tasks. However, doing so is difficult in practice: In multi-task RL, state of the art methods often fail to outperform a degenerate solution that simply learns each task separately. Hypernetworks are a promising path forward since they replicate the separate policies of the degenerate solution while also allowing for generalization across tasks, and are applicable to meta-RL. However, evidence from supervised learning suggests hypernetwork performance is highly sensitive to the initialization. In this paper, we 1) show that hypernetwork initialization is also a critical factor in meta-RL, and that naive initializations yield poor performance; 2) propose a novel hypernetwork initialization scheme that matches or exceeds the performance of a state-of-the-art approach proposed for supervised settings, as well as being simpler and more general; and 3) use this method to show that hypernetworks can improve performance in meta-RL by evaluating on multiple simulated robotics benchmarks.