 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Apr 10, 2025


AI is increasingly playing a pivotal role in transforming how scientific discoveries are made. We introduce The AI Scientist-v2, an end-to-end agentic system capable of producing the first entirely AI generated peer-review-accepted workshop paper. This system iteratively formulates scientific hypotheses, designs and executes experiments, analyzes and visualizes data, and autonomously authors scientific manuscripts. Compared to its predecessor (v1, Lu et al., 2024 arXiv:2408.06292), The AI Scientist-v2 eliminates the reliance on human-authored code templates, generalizes effectively across diverse machine learning domains, and leverages a novel progressive agentic tree-search methodology managed by a dedicated experiment manager agent. Additionally, we enhance the AI reviewer component by integrating a Vision-Language Model (VLM) feedback loop for iterative refinement of content and aesthetics of the figures. We evaluated The AI Scientist-v2 by submitting three fully autonomous manuscripts to a peer-reviewed ICLR workshop. Notably, one manuscript achieved high enough scores to exceed the average human acceptance threshold, marking the first instance of a fully AI-generated paper successfully navigating a peer review. This accomplishment highlights the growing capability of AI in conducting all aspects of scientific research. We anticipate that further advancements in autonomous scientific discovery technologies will profoundly impact human knowledge generation, enabling unprecedented scalability in research productivity and significantly accelerating scientific breakthroughs, greatly benefiting society at large. We have open-sourced the code at https://github.com/SakanaAI/AI-Scientist-v2 to foster the future development of this transformative technology. We also discuss the role of AI in science, including AI safety.
Automating the Search for Artificial Life with Foundation Models
Dec 23, 2024



With the recent Nobel Prize awarded for radical advances in protein discovery, foundation models (FMs) for exploring large combinatorial spaces promise to revolutionize many scientific fields. Artificial Life (ALife) has not yet integrated FMs, thus presenting a major opportunity for the field to alleviate the historical burden of relying chiefly on manual design and trial-and-error to discover the configurations of lifelike simulations. This paper presents, for the first time, a successful realization of this opportunity using vision-language FMs. The proposed approach, called Automated Search for Artificial Life (ASAL), (1) finds simulations that produce target phenomena, (2) discovers simulations that generate temporally open-ended novelty, and (3) illuminates an entire space of interestingly diverse simulations. Because of the generality of FMs, ASAL works effectively across a diverse range of ALife substrates including Boids, Particle Life, Game of Life, Lenia, and Neural Cellular Automata. A major result highlighting the potential of this technique is the discovery of previously unseen Lenia and Boids lifeforms, as well as cellular automata that are open-ended like Conway's Game of Life. Additionally, the use of FMs allows for the quantification of previously qualitative phenomena in a human-aligned way. This new paradigm promises to accelerate ALife research beyond what is possible through human ingenuity alone.
Kinetix: Investigating the Training of General Agents through Open-Ended Physics-Based Control Tasks
Oct 30, 2024While large models trained with self-supervised learning on offline datasets have shown remarkable capabilities in text and image domains, achieving the same generalisation for agents that act in sequential decision problems remains an open challenge. In this work, we take a step towards this goal by procedurally generating tens of millions of 2D physics-based tasks and using these to train a general reinforcement learning (RL) agent for physical control. To this end, we introduce Kinetix: an open-ended space of physics-based RL environments that can represent tasks ranging from robotic locomotion and grasping to video games and classic RL environments, all within a unified framework. Kinetix makes use of our novel hardware-accelerated physics engine Jax2D that allows us to cheaply simulate billions of environment steps during training. Our trained agent exhibits strong physical reasoning capabilities, being able to zero-shot solve unseen human-designed environments. Furthermore, fine-tuning this general agent on tasks of interest shows significantly stronger performance than training an RL agent *tabula rasa*. This includes solving some environments that standard RL training completely fails at. We believe this demonstrates the feasibility of large scale, mixed-quality pre-training for online RL and we hope that Kinetix will serve as a useful framework to investigate this further.
JaxLife: An Open-Ended Agentic Simulator
Sep 01, 2024Human intelligence emerged through the process of natural selection and evolution on Earth. We investigate what it would take to re-create this process in silico. While past work has often focused on low-level processes (such as simulating physics or chemistry), we instead take a more targeted approach, aiming to evolve agents that can accumulate open-ended culture and technologies across generations. Towards this, we present JaxLife: an artificial life simulator in which embodied agents, parameterized by deep neural networks, must learn to survive in an expressive world containing programmable systems. First, we describe the environment and show that it can facilitate meaningful Turing-complete computation. We then analyze the evolved emergent agents' behavior, such as rudimentary communication protocols, agriculture, and tool use. Finally, we investigate how complexity scales with the amount of compute used. We believe JaxLife takes a step towards studying evolved behavior in more open-ended simulations. Our code is available at https://github.com/luchris429/JaxLife
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Aug 15, 2024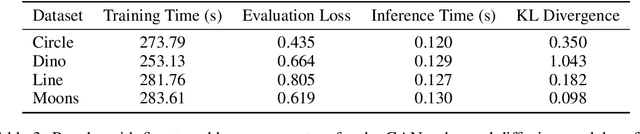


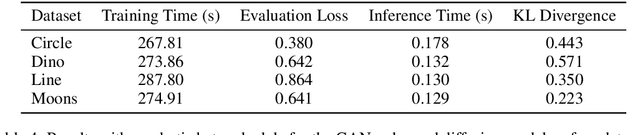
One of the grand challenges of artificial general intelligence is developing agents capable of conducting scientific research and discovering new knowledge. While frontier models have already been used as aides to human scientists, e.g. for brainstorming ideas, writing code, or prediction tasks, they still conduct only a small part of the scientific process. This paper presents the first comprehensive framework for fully automatic scientific discovery, enabling frontier large language models to perform research independently and communicate their findings. We introduce The AI Scientist, which generates novel research ideas, writes code, executes experiments, visualizes results, describes its findings by writing a full scientific paper, and then runs a simulated review process for evaluation. In principle, this process can be repeated to iteratively develop ideas in an open-ended fashion, acting like the human scientific community. We demonstrate its versatility by applying it to three distinct subfields of machine learning: diffusion modeling, transformer-based language modeling, and learning dynamics. Each idea is implemented and developed into a full paper at a cost of less than $15 per paper. To evaluate the generated papers, we design and validate an automated reviewer, which we show achieves near-human performance in evaluating paper scores. The AI Scientist can produce papers that exceed the acceptance threshold at a top machine learning conference as judged by our automated reviewer. This approach signifies the beginning of a new era in scientific discovery in machine learning: bringing the transformative benefits of AI agents to the entire research process of AI itself, and taking us closer to a world where endless affordable creativity and innovation can be unleashed on the world's most challenging problems. Our code is open-sourced at https://github.com/SakanaAI/AI-Scientist
NAVIX: Scaling MiniGrid Environments with JAX
Jul 28, 2024



As Deep Reinforcement Learning (Deep RL) research moves towards solving large-scale worlds, efficient environment simulations become crucial for rapid experimentation. However, most existing environments struggle to scale to high throughput, setting back meaningful progress. Interactions are typically computed on the CPU, limiting training speed and throughput, due to slower computation and communication overhead when distributing the task across multiple machines. Ultimately, Deep RL training is CPU-bound, and developing batched, fast, and scalable environments has become a frontier for progress. Among the most used Reinforcement Learning (RL) environments, MiniGrid is at the foundation of several studies on exploration, curriculum learning, representation learning, diversity, meta-learning, credit assignment, and language-conditioned RL, and still suffers from the limitations described above. In this work, we introduce NAVIX, a re-implementation of MiniGrid in JAX. NAVIX achieves over 200 000x speed improvements in batch mode, supporting up to 2048 agents in parallel on a single Nvidia A100 80 GB. This reduces experiment times from one week to 15 minutes, promoting faster design iterations and more scalable RL model development.
Can Learned Optimization Make Reinforcement Learning Less Difficult?
Jul 09, 2024While reinforcement learning (RL) holds great potential for decision making in the real world, it suffers from a number of unique difficulties which often need specific consideration. In particular: it is highly non-stationary; suffers from high degrees of plasticity loss; and requires exploration to prevent premature convergence to local optima and maximize return. In this paper, we consider whether learned optimization can help overcome these problems. Our method, Learned Optimization for Plasticity, Exploration and Non-stationarity (OPEN), meta-learns an update rule whose input features and output structure are informed by previously proposed solutions to these difficulties. We show that our parameterization is flexible enough to enable meta-learning in diverse learning contexts, including the ability to use stochasticity for exploration. Our experiments demonstrate that when meta-trained on single and small sets of environments, OPEN outperforms or equals traditionally used optimizers. Furthermore, OPEN shows strong generalization across a distribution of environments and a range of agent architectures.
Behaviour Distillation
Jun 21, 2024



Dataset distillation aims to condense large datasets into a small number of synthetic examples that can be used as drop-in replacements when training new models. It has applications to interpretability, neural architecture search, privacy, and continual learning. Despite strong successes in supervised domains, such methods have not yet been extended to reinforcement learning, where the lack of a fixed dataset renders most distillation methods unusable. Filling the gap, we formalize behaviour distillation, a setting that aims to discover and then condense the information required for training an expert policy into a synthetic dataset of state-action pairs, without access to expert data. We then introduce Hallucinating Datasets with Evolution Strategies (HaDES), a method for behaviour distillation that can discover datasets of just four state-action pairs which, under supervised learning, train agents to competitive performance levels in continuous control tasks. We show that these datasets generalize out of distribution to training policies with a wide range of architectures and hyperparameters. We also demonstrate application to a downstream task, namely training multi-task agents in a zero-shot fashion. Beyond behaviour distillation, HaDES provides significant improvements in neuroevolution for RL over previous approaches and achieves SoTA results on one standard supervised dataset distillation task. Finally, we show that visualizing the synthetic datasets can provide human-interpretable task insights.
Discovering Minimal Reinforcement Learning Environments
Jun 18, 2024Reinforcement learning (RL) agents are commonly trained and evaluated in the same environment. In contrast, humans often train in a specialized environment before being evaluated, such as studying a book before taking an exam. The potential of such specialized training environments is still vastly underexplored, despite their capacity to dramatically speed up training. The framework of synthetic environments takes a first step in this direction by meta-learning neural network-based Markov decision processes (MDPs). The initial approach was limited to toy problems and produced environments that did not transfer to unseen RL algorithms. We extend this approach in three ways: Firstly, we modify the meta-learning algorithm to discover environments invariant towards hyperparameter configurations and learning algorithms. Secondly, by leveraging hardware parallelism and introducing a curriculum on an agent's evaluation episode horizon, we can achieve competitive results on several challenging continuous control problems. Thirdly, we surprisingly find that contextual bandits enable training RL agents that transfer well to their evaluation environment, even if it is a complex MDP. Hence, we set up our experiments to train synthetic contextual bandits, which perform on par with synthetic MDPs, yield additional insights into the evaluation environment, and can speed up downstream applications.