 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDéjàQ: Open-Ended Evolution of Diverse, Learnable and Verifiable Problems
Jan 05, 2026Recent advances in reasoning models have yielded impressive results in mathematics and coding. However, most approaches rely on static datasets, which have been suggested to encourage memorisation and limit generalisation. We introduce DéjàQ, a framework that departs from this paradigm by jointly evolving a diverse set of synthetic mathematical problems alongside model training. This evolutionary process adapts to the model's ability throughout training, optimising problems for learnability. We propose two LLM-driven mutation strategies in which the model itself mutates the training data, either by altering contextual details or by directly modifying problem structure. We find that the model can generate novel and meaningful problems, and that these LLM-driven mutations improve RL training. We analyse key aspects of DéjàQ, including the validity of generated problems and computational overhead. Our results underscore the potential of dynamically evolving training data to enhance mathematical reasoning and indicate broader applicability, which we will support by open-sourcing our code.
Bootstrapping Task Spaces for Self-Improvement
Sep 04, 2025Progress in many task domains emerges from repeated revisions to previous solution attempts. Training agents that can reliably self-improve over such sequences at inference-time is a natural target for reinforcement learning (RL), yet the naive approach assumes a fixed maximum iteration depth, which can be both costly and arbitrary. We present Exploratory Iteration (ExIt), a family of autocurriculum RL methods that directly exploits the recurrent structure of self-improvement tasks to train LLMs to perform multi-step self-improvement at inference-time while only training on the most informative single-step iterations. ExIt grows a task space by selectively sampling the most informative intermediate, partial histories encountered during an episode for continued iteration, treating these starting points as new self-iteration task instances to train a self-improvement policy. ExIt can further pair with explicit exploration mechanisms to sustain greater task diversity. Across several domains, encompassing competition math, multi-turn tool-use, and machine learning engineering, we demonstrate that ExIt strategies, starting from either a single or many task instances, can produce policies exhibiting strong inference-time self-improvement on held-out task instances, and the ability to iterate towards higher performance over a step budget extending beyond the average iteration depth encountered during training.
AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Jul 03, 2025AI research agents are demonstrating great potential to accelerate scientific progress by automating the design, implementation, and training of machine learning models. We focus on methods for improving agents' performance on MLE-bench, a challenging benchmark where agents compete in Kaggle competitions to solve real-world machine learning problems. We formalize AI research agents as search policies that navigate a space of candidate solutions, iteratively modifying them using operators. By designing and systematically varying different operator sets and search policies (Greedy, MCTS, Evolutionary), we show that their interplay is critical for achieving high performance. Our best pairing of search strategy and operator set achieves a state-of-the-art result on MLE-bench lite, increasing the success rate of achieving a Kaggle medal from 39.6% to 47.7%. Our investigation underscores the importance of jointly considering the search strategy, operator design, and evaluation methodology in advancing automated machine learning.
Ad-Hoc Human-AI Coordination Challenge
Jun 26, 2025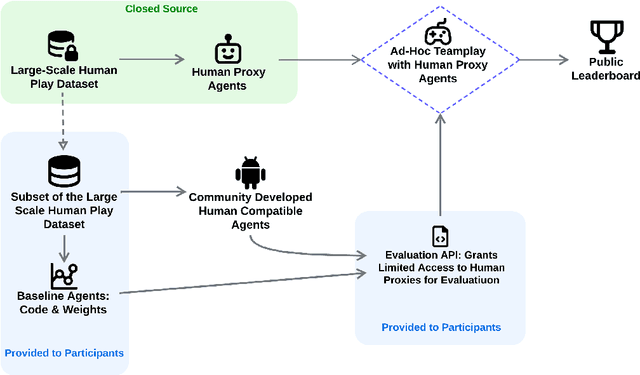

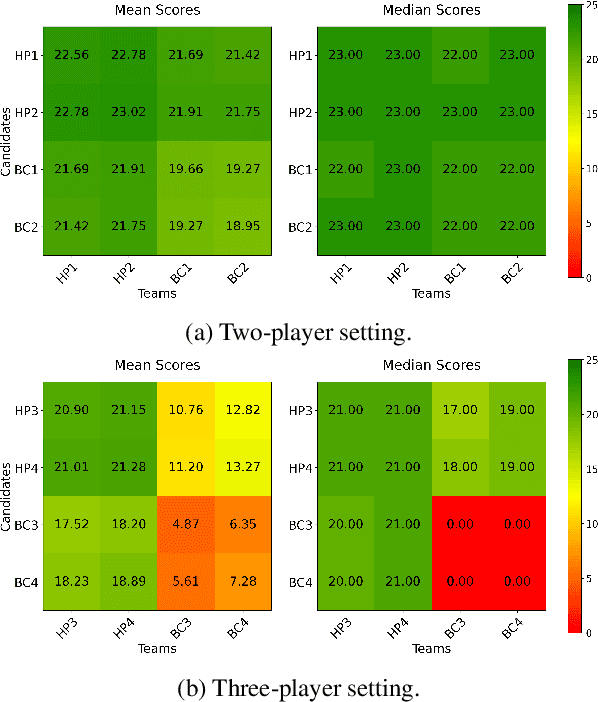

Achieving seamless coordination between AI agents and humans is crucial for real-world applications, yet it remains a significant open challenge. Hanabi is a cooperative card game featuring imperfect information, constrained communication, theory of mind requirements, and coordinated action -- making it an ideal testbed for human-AI coordination. However, its use for human-AI interaction has been limited by the challenges of human evaluation. In this work, we introduce the Ad-Hoc Human-AI Coordination Challenge (AH2AC2) to overcome the constraints of costly and difficult-to-reproduce human evaluations. We develop \textit{human proxy agents} on a large-scale human dataset that serve as robust, cheap, and reproducible human-like evaluation partners in AH2AC2. To encourage the development of data-efficient methods, we open-source a dataset of 3,079 games, deliberately limiting the amount of available human gameplay data. We present baseline results for both two- and three- player Hanabi scenarios. To ensure fair evaluation, we host the proxy agents through a controlled evaluation system rather than releasing them publicly. The code is available at \href{https://github.com/FLAIROx/ah2ac2}{https://github.com/FLAIROx/ah2ac2}.
The Decrypto Benchmark for Multi-Agent Reasoning and Theory of Mind
Jun 25, 2025As Large Language Models (LLMs) gain agentic abilities, they will have to navigate complex multi-agent scenarios, interacting with human users and other agents in cooperative and competitive settings. This will require new reasoning skills, chief amongst them being theory of mind (ToM), or the ability to reason about the "mental" states of other agents. However, ToM and other multi-agent abilities in LLMs are poorly understood, since existing benchmarks suffer from narrow scope, data leakage, saturation, and lack of interactivity. We thus propose Decrypto, a game-based benchmark for multi-agent reasoning and ToM drawing inspiration from cognitive science, computational pragmatics and multi-agent reinforcement learning. It is designed to be as easy as possible in all other dimensions, eliminating confounding factors commonly found in other benchmarks. To our knowledge, it is also the first platform for designing interactive ToM experiments. We validate the benchmark design through comprehensive empirical evaluations of frontier LLMs, robustness studies, and human-AI cross-play experiments. We find that LLM game-playing abilities lag behind humans and simple word-embedding baselines. We then create variants of two classic cognitive science experiments within Decrypto to evaluate three key ToM abilities. Surprisingly, we find that state-of-the-art reasoning models are significantly worse at those tasks than their older counterparts. This demonstrates that Decrypto addresses a crucial gap in current reasoning and ToM evaluations, and paves the path towards better artificial agents.
Adam on Local Time: Addressing Nonstationarity in RL with Relative Adam Timesteps
Dec 22, 2024In reinforcement learning (RL), it is common to apply techniques used broadly in machine learning such as neural network function approximators and momentum-based optimizers. However, such tools were largely developed for supervised learning rather than nonstationary RL, leading practitioners to adopt target networks, clipped policy updates, and other RL-specific implementation tricks to combat this mismatch, rather than directly adapting this toolchain for use in RL. In this paper, we take a different approach and instead address the effect of nonstationarity by adapting the widely used Adam optimiser. We first analyse the impact of nonstationary gradient magnitude -- such as that caused by a change in target network -- on Adam's update size, demonstrating that such a change can lead to large updates and hence sub-optimal performance. To address this, we introduce Adam-Rel. Rather than using the global timestep in the Adam update, Adam-Rel uses the local timestep within an epoch, essentially resetting Adam's timestep to 0 after target changes. We demonstrate that this avoids large updates and reduces to learning rate annealing in the absence of such increases in gradient magnitude. Evaluating Adam-Rel in both on-policy and off-policy RL, we demonstrate improved performance in both Atari and Craftax. We then show that increases in gradient norm occur in RL in practice, and examine the differences between our theoretical model and the observed data.
CURATe: Benchmarking Personalised Alignment of Conversational AI Assistants
Oct 28, 2024



We introduce a multi-turn benchmark for evaluating personalised alignment in LLM-based AI assistants, focusing on their ability to handle user-provided safety-critical contexts. Our assessment of ten leading models across five scenarios (each with 337 use cases) reveals systematic inconsistencies in maintaining user-specific consideration, with even top-rated "harmless" models making recommendations that should be recognised as obviously harmful to the user given the context provided. Key failure modes include inappropriate weighing of conflicting preferences, sycophancy (prioritising user preferences above safety), a lack of attentiveness to critical user information within the context window, and inconsistent application of user-specific knowledge. The same systematic biases were observed in OpenAI's o1, suggesting that strong reasoning capacities do not necessarily transfer to this kind of personalised thinking. We find that prompting LLMs to consider safety-critical context significantly improves performance, unlike a generic 'harmless and helpful' instruction. Based on these findings, we propose research directions for embedding self-reflection capabilities, online user modelling, and dynamic risk assessment in AI assistants. Our work emphasises the need for nuanced, context-aware approaches to alignment in systems designed for persistent human interaction, aiding the development of safe and considerate AI assistants.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Behaviour Distillation
Jun 21, 2024



Dataset distillation aims to condense large datasets into a small number of synthetic examples that can be used as drop-in replacements when training new models. It has applications to interpretability, neural architecture search, privacy, and continual learning. Despite strong successes in supervised domains, such methods have not yet been extended to reinforcement learning, where the lack of a fixed dataset renders most distillation methods unusable. Filling the gap, we formalize behaviour distillation, a setting that aims to discover and then condense the information required for training an expert policy into a synthetic dataset of state-action pairs, without access to expert data. We then introduce Hallucinating Datasets with Evolution Strategies (HaDES), a method for behaviour distillation that can discover datasets of just four state-action pairs which, under supervised learning, train agents to competitive performance levels in continuous control tasks. We show that these datasets generalize out of distribution to training policies with a wide range of architectures and hyperparameters. We also demonstrate application to a downstream task, namely training multi-task agents in a zero-shot fashion. Beyond behaviour distillation, HaDES provides significant improvements in neuroevolution for RL over previous approaches and achieves SoTA results on one standard supervised dataset distillation task. Finally, we show that visualizing the synthetic datasets can provide human-interpretable task insights.
Discovering Minimal Reinforcement Learning Environments
Jun 18, 2024Reinforcement learning (RL) agents are commonly trained and evaluated in the same environment. In contrast, humans often train in a specialized environment before being evaluated, such as studying a book before taking an exam. The potential of such specialized training environments is still vastly underexplored, despite their capacity to dramatically speed up training. The framework of synthetic environments takes a first step in this direction by meta-learning neural network-based Markov decision processes (MDPs). The initial approach was limited to toy problems and produced environments that did not transfer to unseen RL algorithms. We extend this approach in three ways: Firstly, we modify the meta-learning algorithm to discover environments invariant towards hyperparameter configurations and learning algorithms. Secondly, by leveraging hardware parallelism and introducing a curriculum on an agent's evaluation episode horizon, we can achieve competitive results on several challenging continuous control problems. Thirdly, we surprisingly find that contextual bandits enable training RL agents that transfer well to their evaluation environment, even if it is a complex MDP. Hence, we set up our experiments to train synthetic contextual bandits, which perform on par with synthetic MDPs, yield additional insights into the evaluation environment, and can speed up downstream applications.