 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIRA_2: Overcoming Bottlenecks in AI Research Agents
Mar 27, 2026Existing research has identified three structural performance bottlenecks in AI research agents: (1) synchronous single-GPU execution constrains sample throughput, limiting the benefit of search; (2) a generalization gap where validation-based selection causes performance to degrade over extended search horizons; and (3) the limited capability of fixed, single-turn LLM operators imposes a ceiling on search performance. We introduce AIRA$_2$, which addresses these bottlenecks through three architectural choices: an asynchronous multi-GPU worker pool that increases experiment throughput linearly; a Hidden Consistent Evaluation protocol that delivers a reliable evaluation signal; and ReAct agents that dynamically scope their actions and debug interactively. On MLE-bench-30, AIRA$_2$ achieves a mean Percentile Rank of 71.8% at 24 hours - surpassing the previous best of 69.9% - and steadily improves to 76.0% at 72 hours. Ablation studies reveal that each component is necessary and that the "overfitting" reported in prior work was driven by evaluation noise rather than true data memorization.
AIRS-Bench: a Suite of Tasks for Frontier AI Research Science Agents
Feb 09, 2026LLM agents hold significant promise for advancing scientific research. To accelerate this progress, we introduce AIRS-Bench (the AI Research Science Benchmark), a suite of 20 tasks sourced from state-of-the-art machine learning papers. These tasks span diverse domains, including language modeling, mathematics, bioinformatics, and time series forecasting. AIRS-Bench tasks assess agentic capabilities over the full research lifecycle -- including idea generation, experiment analysis and iterative refinement -- without providing baseline code. The AIRS-Bench task format is versatile, enabling easy integration of new tasks and rigorous comparison across different agentic frameworks. We establish baselines using frontier models paired with both sequential and parallel scaffolds. Our results show that agents exceed human SOTA in four tasks but fail to match it in sixteen others. Even when agents surpass human benchmarks, they do not reach the theoretical performance ceiling for the underlying tasks. These findings indicate that AIRS-Bench is far from saturated and offers substantial room for improvement. We open-source the AIRS-Bench task definitions and evaluation code to catalyze further development in autonomous scientific research.
What Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity
Nov 19, 2025AI research agents offer the promise to accelerate scientific progress by automating the design, implementation, and training of machine learning models. However, the field is still in its infancy, and the key factors driving the success or failure of agent trajectories are not fully understood. We examine the role that ideation diversity plays in agent performance. First, we analyse agent trajectories on MLE-bench, a well-known benchmark to evaluate AI research agents, across different models and agent scaffolds. Our analysis reveals that different models and agent scaffolds yield varying degrees of ideation diversity, and that higher-performing agents tend to have increased ideation diversity. Further, we run a controlled experiment where we modify the degree of ideation diversity, demonstrating that higher ideation diversity results in stronger performance. Finally, we strengthen our results by examining additional evaluation metrics beyond the standard medal-based scoring of MLE-bench, showing that our findings still hold across other agent performance metrics.
AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Jul 03, 2025AI research agents are demonstrating great potential to accelerate scientific progress by automating the design, implementation, and training of machine learning models. We focus on methods for improving agents' performance on MLE-bench, a challenging benchmark where agents compete in Kaggle competitions to solve real-world machine learning problems. We formalize AI research agents as search policies that navigate a space of candidate solutions, iteratively modifying them using operators. By designing and systematically varying different operator sets and search policies (Greedy, MCTS, Evolutionary), we show that their interplay is critical for achieving high performance. Our best pairing of search strategy and operator set achieves a state-of-the-art result on MLE-bench lite, increasing the success rate of achieving a Kaggle medal from 39.6% to 47.7%. Our investigation underscores the importance of jointly considering the search strategy, operator design, and evaluation methodology in advancing automated machine learning.
With Great Backbones Comes Great Adversarial Transferability
Jan 21, 2025



Advances in self-supervised learning (SSL) for machine vision have improved representation robustness and model performance, giving rise to pre-trained backbones like \emph{ResNet} and \emph{ViT} models tuned with SSL methods such as \emph{SimCLR}. Due to the computational and data demands of pre-training, the utilization of such backbones becomes a strenuous necessity. However, employing these backbones may inherit vulnerabilities to adversarial attacks. While adversarial robustness has been studied under \emph{white-box} and \emph{black-box} settings, the robustness of models tuned on pre-trained backbones remains largely unexplored. Additionally, the role of tuning meta-information in mitigating exploitation risks is unclear. This work systematically evaluates the adversarial robustness of such models across $20,000$ combinations of tuning meta-information, including fine-tuning techniques, backbone families, datasets, and attack types. We propose using proxy models to transfer attacks, simulating varying levels of target knowledge by fine-tuning these proxies with diverse configurations. Our findings reveal that proxy-based attacks approach the effectiveness of \emph{white-box} methods, even with minimal tuning knowledge. We also introduce a naive "backbone attack," leveraging only the backbone to generate adversarial samples, which outperforms \emph{black-box} attacks and rivals \emph{white-box} methods, highlighting critical risks in model-sharing practices. Finally, our ablations reveal how increasing tuning meta-information impacts attack transferability, measuring each meta-information combination.
Robust LLM safeguarding via refusal feature adversarial training
Sep 30, 2024

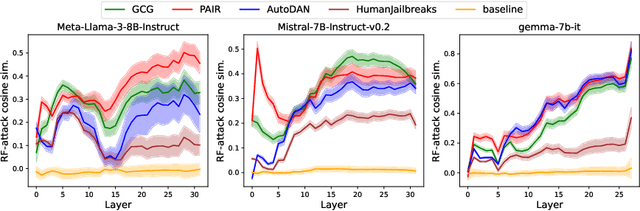

Large language models (LLMs) are vulnerable to adversarial attacks that can elicit harmful responses. Defending against such attacks remains challenging due to the opacity of jailbreaking mechanisms and the high computational cost of training LLMs robustly. We demonstrate that adversarial attacks share a universal mechanism for circumventing LLM safeguards that works by ablating a dimension in the residual stream embedding space called the refusal feature. We further show that the operation of refusal feature ablation (RFA) approximates the worst-case perturbation of offsetting model safety. Based on these findings, we propose Refusal Feature Adversarial Training (ReFAT), a novel algorithm that efficiently performs LLM adversarial training by simulating the effect of input-level attacks via RFA. Experiment results show that ReFAT significantly improves the robustness of three popular LLMs against a wide range of adversarial attacks, with considerably less computational overhead compared to existing adversarial training methods.
LM Transparency Tool: Interactive Tool for Analyzing Transformer Language Models
Apr 10, 2024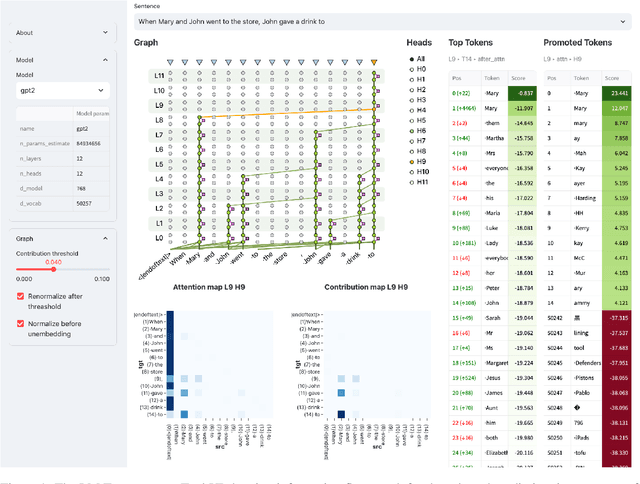
We present the LM Transparency Tool (LM-TT), an open-source interactive toolkit for analyzing the internal workings of Transformer-based language models. Differently from previously existing tools that focus on isolated parts of the decision-making process, our framework is designed to make the entire prediction process transparent, and allows tracing back model behavior from the top-layer representation to very fine-grained parts of the model. Specifically, it (1) shows the important part of the whole input-to-output information flow, (2) allows attributing any changes done by a model block to individual attention heads and feed-forward neurons, (3) allows interpreting the functions of those heads or neurons. A crucial part of this pipeline is showing the importance of specific model components at each step. As a result, we are able to look at the roles of model components only in cases where they are important for a prediction. Since knowing which components should be inspected is key for analyzing large models where the number of these components is extremely high, we believe our tool will greatly support the interpretability community both in research settings and in practical applications.
Scaling Laws for Generative Mixed-Modal Language Models
Jan 10, 2023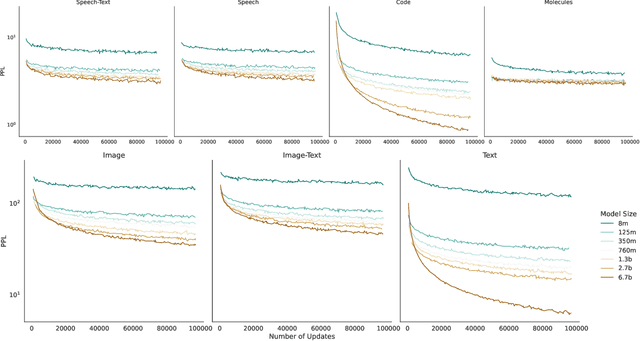
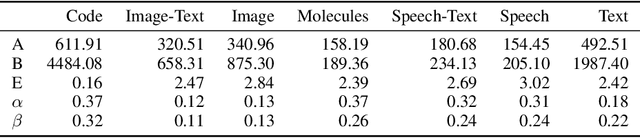
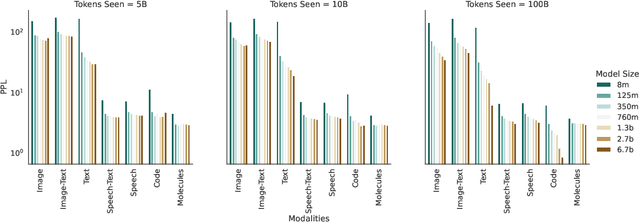
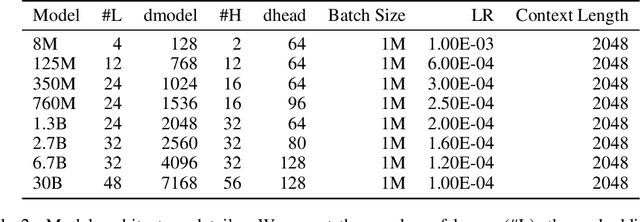
Generative language models define distributions over sequences of tokens that can represent essentially any combination of data modalities (e.g., any permutation of image tokens from VQ-VAEs, speech tokens from HuBERT, BPE tokens for language or code, and so on). To better understand the scaling properties of such mixed-modal models, we conducted over 250 experiments using seven different modalities and model sizes ranging from 8 million to 30 billion, trained on 5-100 billion tokens. We report new mixed-modal scaling laws that unify the contributions of individual modalities and the interactions between them. Specifically, we explicitly model the optimal synergy and competition due to data and model size as an additive term to previous uni-modal scaling laws. We also find four empirical phenomena observed during the training, such as emergent coordinate-ascent style training that naturally alternates between modalities, guidelines for selecting critical hyper-parameters, and connections between mixed-modal competition and training stability. Finally, we test our scaling law by training a 30B speech-text model, which significantly outperforms the corresponding unimodal models. Overall, our research provides valuable insights into the design and training of mixed-modal generative models, an important new class of unified models that have unique distributional properties.
BARTSmiles: Generative Masked Language Models for Molecular Representations
Nov 29, 2022



We discover a robust self-supervised strategy tailored towards molecular representations for generative masked language models through a series of tailored, in-depth ablations. Using this pre-training strategy, we train BARTSmiles, a BART-like model with an order of magnitude more compute than previous self-supervised molecular representations. In-depth evaluations show that BARTSmiles consistently outperforms other self-supervised representations across classification, regression, and generation tasks setting a new state-of-the-art on 11 tasks. We then quantitatively show that when applied to the molecular domain, the BART objective learns representations that implicitly encode our downstream tasks of interest. For example, by selecting seven neurons from a frozen BARTSmiles, we can obtain a model having performance within two percentage points of the full fine-tuned model on task Clintox. Lastly, we show that standard attribution interpretability methods, when applied to BARTSmiles, highlight certain substructures that chemists use to explain specific properties of molecules. The code and the pretrained model are publicly available.
WARP: Word-level Adversarial ReProgramming
Jan 01, 2021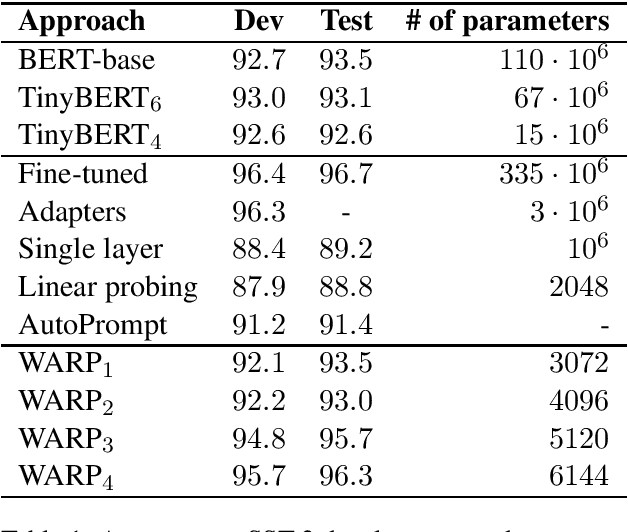
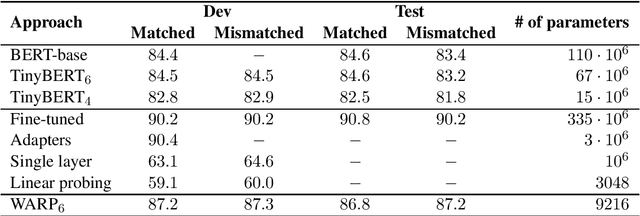

Transfer learning from pretrained language models recently became the dominant approach for solving many NLP tasks. While fine-tuning large language models usually gives the best performance, in many applications it is preferable to tune much smaller sets of parameters, so that the majority of parameters can be shared across multiple tasks. The main approach is to train one or more task-specific layers on top of the language model. In this paper we present an alternative approach based on adversarial reprogramming, which extends earlier work on automatic prompt generation. It attempts to learn task-specific word embeddings that, when concatenated to the input text, instruct the language model to solve the specified task. We show that this approach outperforms other methods with a similar number of trainable parameters on SST-2 and MNLI datasets. On SST-2, the performance of our model is comparable to the fully fine-tuned baseline, while on MNLI it is the best among the methods that do not modify the parameters of the body of the language model.