 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillRater: Untangling Capabilities in Multimodal Data
Feb 12, 2026Data curation methods typically assign samples a single quality score. We argue this scalar framing is fundamentally limited: when training requires multiple distinct capabilities, a monolithic scorer cannot maximize useful signals for all of them simultaneously. Quality is better understood as multidimensional, with each dimension corresponding to a capability the model must acquire. We introduce SkillRater, a framework that decomposes data filtering into specialized raters - one per capability, each trained via meta-learning on a disjoint validation objective - and composes their scores through a progressive selection rule: at each training stage, a sample is retained if any rater ranks it above a threshold that tightens over time, preserving diversity early while concentrating on high-value samples late. We validate this approach on vision language models, decomposing quality into three capability dimensions: visual understanding, OCR, and STEM reasoning. At 2B parameters, SkillRater improves over unfiltered baselines by 5.63% on visual understanding, 2.00% on OCR, and 3.53% on STEM on held out benchmarks. The learned rater signals are near orthogonal, confirming that the decomposition captures genuinely independent quality dimensions and explaining why it outperforms both unfiltered training and monolithic learned filtering.
Improving MoE Compute Efficiency by Composing Weight and Data Sparsity
Jan 21, 2026Mixture-of-Experts layers achieve compute efficiency through weight sparsity: each token activates only a subset of experts. Data sparsity, where each expert processes only a subset of tokens, offers a complementary axis. Expert-choice routing implements data sparsity directly but violates causality in autoregressive models, creating train-inference mismatch. We recover data sparsity within causal token-choice MoE by leveraging zero-compute (null) experts within the routing pool. When a token routes to null experts, those slots consume no compute. The standard load balancing objective trains the model to uniformly use all experts (real and null) therefore creating data sparsity in expectation without the causality violations. We evaluate on vision-language model training, where data heterogeneity is pronounced: vision encoders produce many low-information tokens while text tokens are denser. At matched expected FLOPs, composing weight and data sparsity yields a more compute-efficient frontier than weight sparsity alone, with gains in training loss and downstream performance. The model learns implicit modality-aware allocation, routing vision tokens to null experts more aggressively than text, without explicit modality routing.
When Worse is Better: Navigating the compression-generation tradeoff in visual tokenization
Dec 20, 2024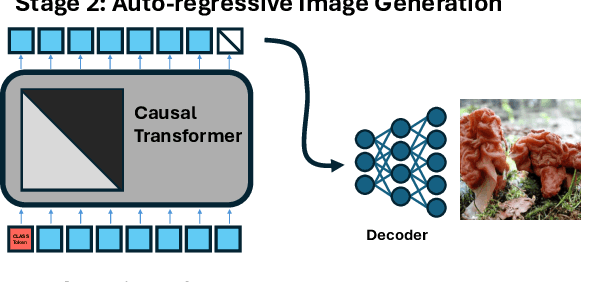
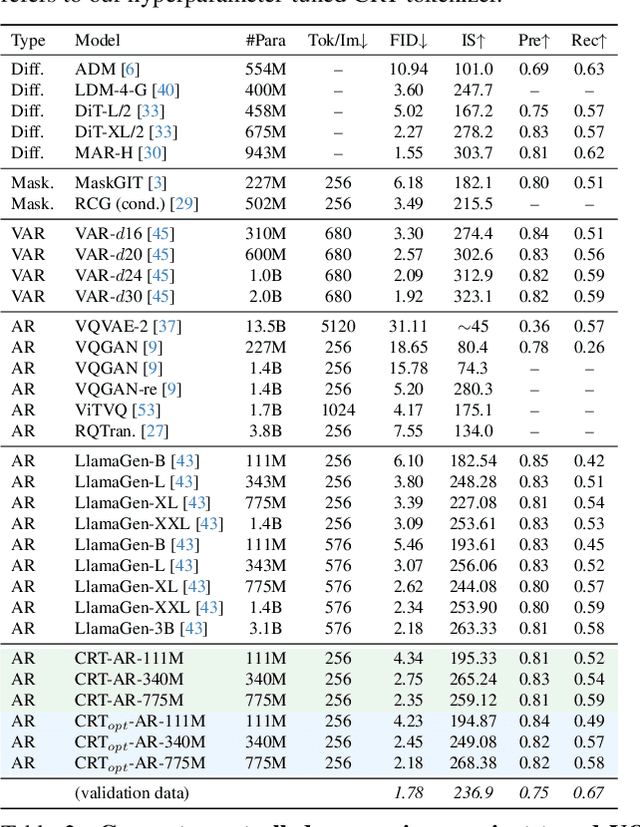

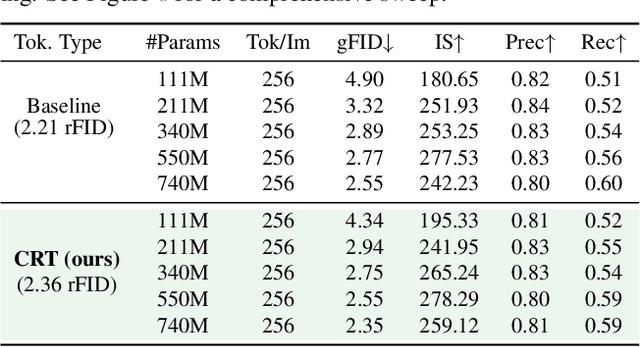
Current image generation methods, such as latent diffusion and discrete token-based generation, depend on a two-stage training approach. In stage 1, an auto-encoder is trained to compress an image into a latent space; in stage 2, a generative model is trained to learn a distribution over that latent space. Most work focuses on maximizing stage 1 performance independent of stage 2, assuming better reconstruction always leads to better generation. However, we show this is not strictly true. Smaller stage 2 models can benefit from more compressed stage 1 latents even if reconstruction performance worsens, showing a fundamental trade-off between compression and generation modeling capacity. To better optimize this trade-off, we introduce Causally Regularized Tokenization (CRT), which uses knowledge of the stage 2 generation modeling procedure to embed useful inductive biases in stage 1 latents. This regularization makes stage 1 reconstruction performance worse, but makes stage 2 generation performance better by making the tokens easier to model: we are able to improve compute efficiency 2-3$\times$ over baseline and match state-of-the-art discrete autoregressive ImageNet generation (2.18 FID) with less than half the tokens per image (256 vs. 576) and a fourth the total model parameters (775M vs. 3.1B) as the previous SOTA (LlamaGen).
MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts
Jul 31, 2024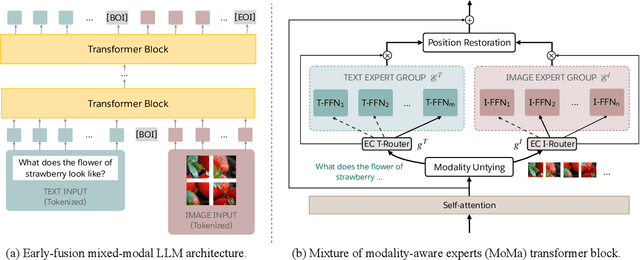

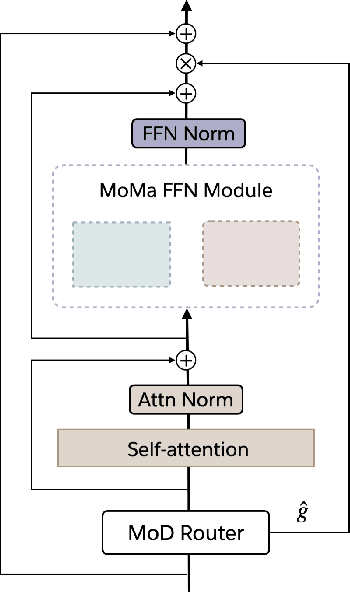
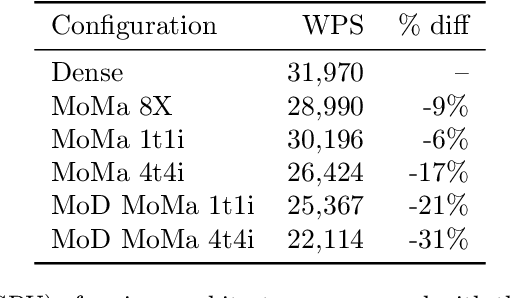
We introduce MoMa, a novel modality-aware mixture-of-experts (MoE) architecture designed for pre-training mixed-modal, early-fusion language models. MoMa processes images and text in arbitrary sequences by dividing expert modules into modality-specific groups. These groups exclusively process designated tokens while employing learned routing within each group to maintain semantically informed adaptivity. Our empirical results reveal substantial pre-training efficiency gains through this modality-specific parameter allocation. Under a 1-trillion-token training budget, the MoMa 1.4B model, featuring 4 text experts and 4 image experts, achieves impressive FLOPs savings: 3.7x overall, with 2.6x for text and 5.2x for image processing compared to a compute-equivalent dense baseline, measured by pre-training loss. This outperforms the standard expert-choice MoE with 8 mixed-modal experts, which achieves 3x overall FLOPs savings (3x for text, 2.8x for image). Combining MoMa with mixture-of-depths (MoD) further improves pre-training FLOPs savings to 4.2x overall (text: 3.4x, image: 5.3x), although this combination hurts performance in causal inference due to increased sensitivity to router accuracy. These results demonstrate MoMa's potential to significantly advance the efficiency of mixed-modal, early-fusion language model pre-training, paving the way for more resource-efficient and capable multimodal AI systems.
Small Molecule Optimization with Large Language Models
Jul 26, 2024Recent advancements in large language models have opened new possibilities for generative molecular drug design. We present Chemlactica and Chemma, two language models fine-tuned on a novel corpus of 110M molecules with computed properties, totaling 40B tokens. These models demonstrate strong performance in generating molecules with specified properties and predicting new molecular characteristics from limited samples. We introduce a novel optimization algorithm that leverages our language models to optimize molecules for arbitrary properties given limited access to a black box oracle. Our approach combines ideas from genetic algorithms, rejection sampling, and prompt optimization. It achieves state-of-the-art performance on multiple molecular optimization benchmarks, including an 8% improvement on Practical Molecular Optimization compared to previous methods. We publicly release the training corpus, the language models and the optimization algorithm.
Text Quality-Based Pruning for Efficient Training of Language Models
Apr 26, 2024



In recent times training Language Models (LMs) have relied on computationally heavy training over massive datasets which makes this training process extremely laborious. In this paper we propose a novel method for numerically evaluating text quality in large unlabelled NLP datasets in a model agnostic manner to assign the text instances a "quality score". By proposing the text quality metric, the paper establishes a framework to identify and eliminate low-quality text instances, leading to improved training efficiency for LM models. Experimental results over multiple models and datasets demonstrate the efficacy of this approach, showcasing substantial gains in training effectiveness and highlighting the potential for resource-efficient LM training. For example, we observe an absolute accuracy improvement of 0.9% averaged over 14 downstream evaluation tasks for multiple LM models while using 40% lesser data and training 42% faster when training on the OpenWebText dataset and 0.8% average absolute accuracy improvement while using 20% lesser data and training 21% faster on the Wikipedia dataset.
DOMINO: A Dual-System for Multi-step Visual Language Reasoning
Oct 04, 2023Visual language reasoning requires a system to extract text or numbers from information-dense images like charts or plots and perform logical or arithmetic reasoning to arrive at an answer. To tackle this task, existing work relies on either (1) an end-to-end vision-language model trained on a large amount of data, or (2) a two-stage pipeline where a captioning model converts the image into text that is further read by another large language model to deduce the answer. However, the former approach forces the model to answer a complex question with one single step, and the latter approach is prone to inaccurate or distracting information in the converted text that can confuse the language model. In this work, we propose a dual-system for multi-step multimodal reasoning, which consists of a "System-1" step for visual information extraction and a "System-2" step for deliberate reasoning. Given an input, System-2 breaks down the question into atomic sub-steps, each guiding System-1 to extract the information required for reasoning from the image. Experiments on chart and plot datasets show that our method with a pre-trained System-2 module performs competitively compared to prior work on in- and out-of-distribution data. By fine-tuning the System-2 module (LLaMA-2 70B) on only a small amount of data on multi-step reasoning, the accuracy of our method is further improved and surpasses the best fully-supervised end-to-end approach by 5.7% and a pipeline approach with FlanPaLM (540B) by 7.5% on a challenging dataset with human-authored questions.
Jointly Training Large Autoregressive Multimodal Models
Sep 28, 2023
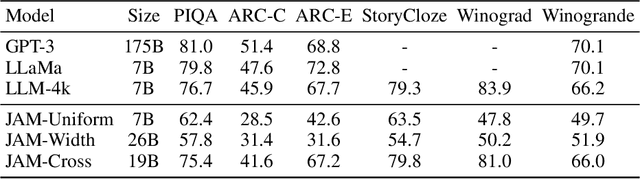
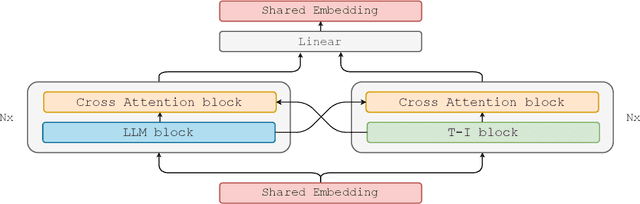
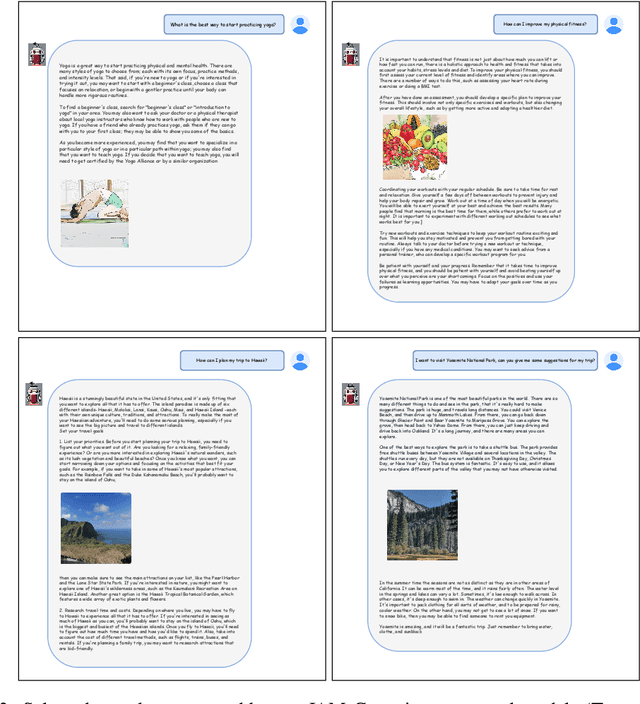
In recent years, advances in the large-scale pretraining of language and text-to-image models have revolutionized the field of machine learning. Yet, integrating these two modalities into a single, robust model capable of generating seamless multimodal outputs remains a significant challenge. To address this gap, we present the Joint Autoregressive Mixture (JAM) framework, a modular approach that systematically fuses existing text and image generation models. We also introduce a specialized, data-efficient instruction-tuning strategy, tailored for mixed-modal generation tasks. Our final instruct-tuned model demonstrates unparalleled performance in generating high-quality multimodal outputs and represents the first model explicitly designed for this purpose.
Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning
Sep 05, 2023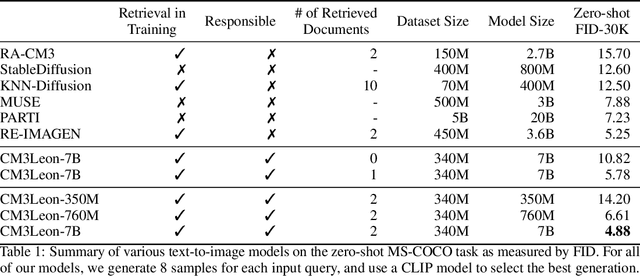

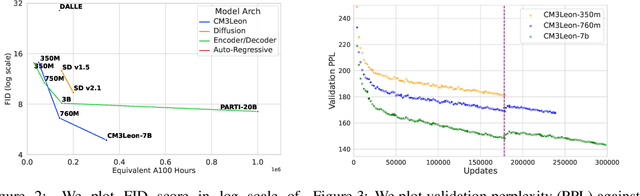

We present CM3Leon (pronounced "Chameleon"), a retrieval-augmented, token-based, decoder-only multi-modal language model capable of generating and infilling both text and images. CM3Leon uses the CM3 multi-modal architecture but additionally shows the extreme benefits of scaling up and tuning on more diverse instruction-style data. It is the first multi-modal model trained with a recipe adapted from text-only language models, including a large-scale retrieval-augmented pre-training stage and a second multi-task supervised fine-tuning (SFT) stage. It is also a general-purpose model that can do both text-to-image and image-to-text generation, allowing us to introduce self-contained contrastive decoding methods that produce high-quality outputs. Extensive experiments demonstrate that this recipe is highly effective for multi-modal models. CM3Leon achieves state-of-the-art performance in text-to-image generation with 5x less training compute than comparable methods (zero-shot MS-COCO FID of 4.88). After SFT, CM3Leon can also demonstrate unprecedented levels of controllability in tasks ranging from language-guided image editing to image-controlled generation and segmentation.
D4: Improving LLM Pretraining via Document De-Duplication and Diversification
Aug 23, 2023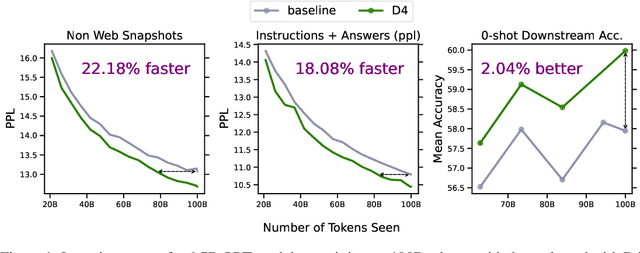
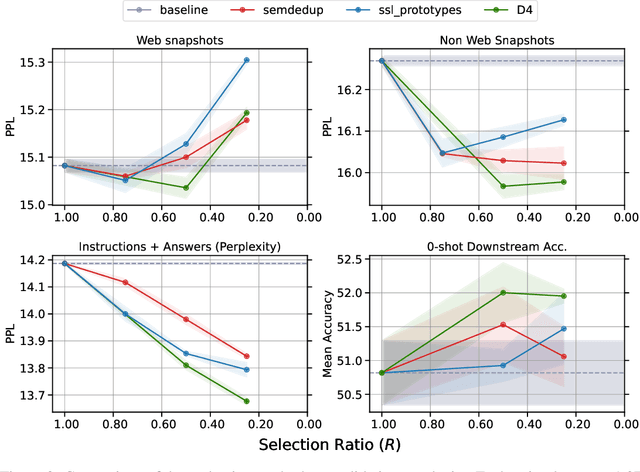
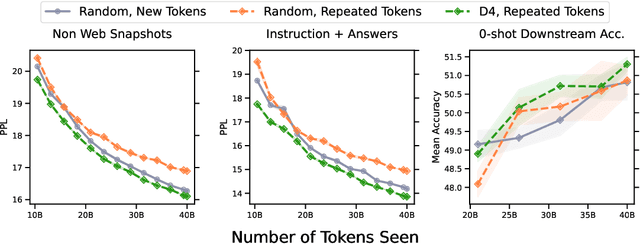
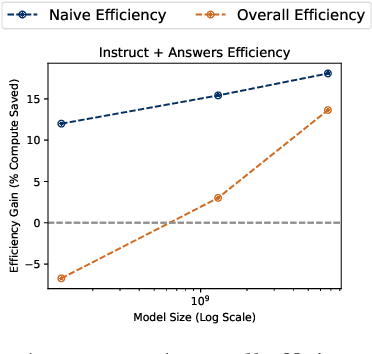
Over recent years, an increasing amount of compute and data has been poured into training large language models (LLMs), usually by doing one-pass learning on as many tokens as possible randomly selected from large-scale web corpora. While training on ever-larger portions of the internet leads to consistent performance improvements, the size of these improvements diminishes with scale, and there has been little work exploring the effect of data selection on pre-training and downstream performance beyond simple de-duplication methods such as MinHash. Here, we show that careful data selection (on top of de-duplicated data) via pre-trained model embeddings can speed up training (20% efficiency gains) and improves average downstream accuracy on 16 NLP tasks (up to 2%) at the 6.7B model scale. Furthermore, we show that repeating data intelligently consistently outperforms baseline training (while repeating random data performs worse than baseline training). Our results indicate that clever data selection can significantly improve LLM pre-training, calls into question the common practice of training for a single epoch on as much data as possible, and demonstrates a path to keep improving our models past the limits of randomly sampling web data.