 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Byte Latent Transformer: Patches Scale Better Than Tokens
Dec 13, 2024We introduce the Byte Latent Transformer (BLT), a new byte-level LLM architecture that, for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference efficiency and robustness. BLT encodes bytes into dynamically sized patches, which serve as the primary units of computation. Patches are segmented based on the entropy of the next byte, allocating more compute and model capacity where increased data complexity demands it. We present the first FLOP controlled scaling study of byte-level models up to 8B parameters and 4T training bytes. Our results demonstrate the feasibility of scaling models trained on raw bytes without a fixed vocabulary. Both training and inference efficiency improve due to dynamically selecting long patches when data is predictable, along with qualitative improvements on reasoning and long tail generalization. Overall, for fixed inference costs, BLT shows significantly better scaling than tokenization-based models, by simultaneously growing both patch and model size.
Layer Swapping for Zero-Shot Cross-Lingual Transfer in Large Language Models
Oct 02, 2024



Model merging, such as model souping, is the practice of combining different models with the same architecture together without further training. In this work, we present a model merging methodology that addresses the difficulty of fine-tuning Large Language Models (LLMs) for target tasks in non-English languages, where task-specific data is often unavailable. We focus on mathematical reasoning and without in-language math data, facilitate cross-lingual transfer by composing language and math capabilities. Starting from the same pretrained model, we fine-tune separate "experts" on math instruction data in English and on generic instruction data in the target language. We then replace the top and bottom transformer layers of the math expert directly with layers from the language expert, which consequently enhances math performance in the target language. The resulting merged models outperform the individual experts and other merging methods on the math benchmark, MGSM, by 10% across four major languages where math instruction data is scarce. In addition, this layer swapping is simple, inexpensive, and intuitive, as it is based on an interpretative analysis of the most important parameter changes during the fine-tuning of each expert. The ability to successfully re-compose LLMs for cross-lingual transfer in this manner opens up future possibilities to combine model expertise, create modular solutions, and transfer reasoning capabilities across languages all post hoc.
SpiRit-LM: Interleaved Spoken and Written Language Model
Feb 08, 2024We introduce SPIRIT-LM, a foundation multimodal language model that freely mixes text and speech. Our model is based on a pretrained text language model that we extend to the speech modality by continuously training it on text and speech units. Speech and text sequences are concatenated as a single set of tokens, and trained with a word-level interleaving method using a small automatically-curated speech-text parallel corpus. SPIRIT-LM comes in two versions: a BASE version that uses speech semantic units and an EXPRESSIVE version that models expressivity using pitch and style units in addition to the semantic units. For both versions, the text is encoded with subword BPE tokens. The resulting model displays both the semantic abilities of text models and the expressive abilities of speech models. Additionally, we demonstrate that SPIRIT-LM is able to learn new tasks in a few-shot fashion across modalities (i.e. ASR, TTS, Speech Classification).
Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning
Sep 05, 2023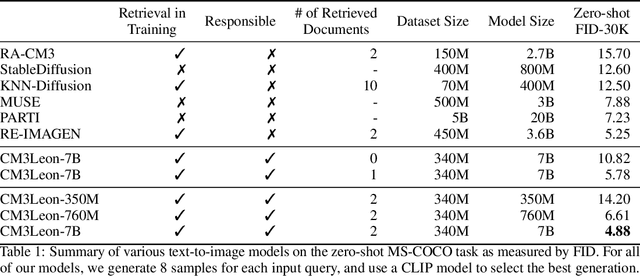

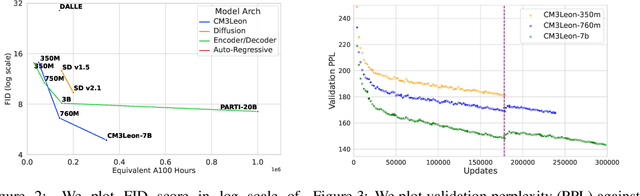

We present CM3Leon (pronounced "Chameleon"), a retrieval-augmented, token-based, decoder-only multi-modal language model capable of generating and infilling both text and images. CM3Leon uses the CM3 multi-modal architecture but additionally shows the extreme benefits of scaling up and tuning on more diverse instruction-style data. It is the first multi-modal model trained with a recipe adapted from text-only language models, including a large-scale retrieval-augmented pre-training stage and a second multi-task supervised fine-tuning (SFT) stage. It is also a general-purpose model that can do both text-to-image and image-to-text generation, allowing us to introduce self-contained contrastive decoding methods that produce high-quality outputs. Extensive experiments demonstrate that this recipe is highly effective for multi-modal models. CM3Leon achieves state-of-the-art performance in text-to-image generation with 5x less training compute than comparable methods (zero-shot MS-COCO FID of 4.88). After SFT, CM3Leon can also demonstrate unprecedented levels of controllability in tasks ranging from language-guided image editing to image-controlled generation and segmentation.
The Belebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants
Aug 31, 2023



We present Belebele, a multiple-choice machine reading comprehension (MRC) dataset spanning 122 language variants. Significantly expanding the language coverage of natural language understanding (NLU) benchmarks, this dataset enables the evaluation of text models in high-, medium-, and low-resource languages. Each question is based on a short passage from the Flores-200 dataset and has four multiple-choice answers. The questions were carefully curated to discriminate between models with different levels of general language comprehension. The English dataset on its own proves difficult enough to challenge state-of-the-art language models. Being fully parallel, this dataset enables direct comparison of model performance across all languages. We use this dataset to evaluate the capabilities of multilingual masked language models (MLMs) and large language models (LLMs). We present extensive results and find that despite significant cross-lingual transfer in English-centric LLMs, much smaller MLMs pretrained on balanced multilingual data still understand far more languages. We also observe that larger vocabulary size and conscious vocabulary construction correlate with better performance on low-resource languages. Overall, Belebele opens up new avenues for evaluating and analyzing the multilingual capabilities of NLP systems.
The Gender-GAP Pipeline: A Gender-Aware Polyglot Pipeline for Gender Characterisation in 55 Languages
Aug 31, 2023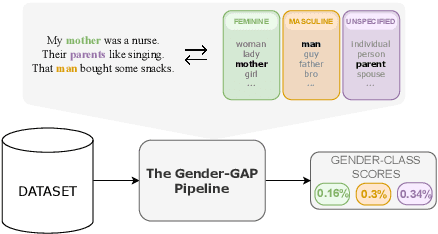
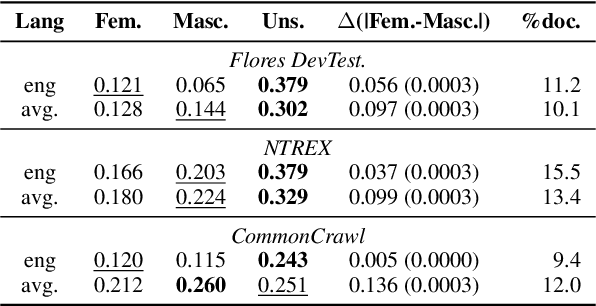
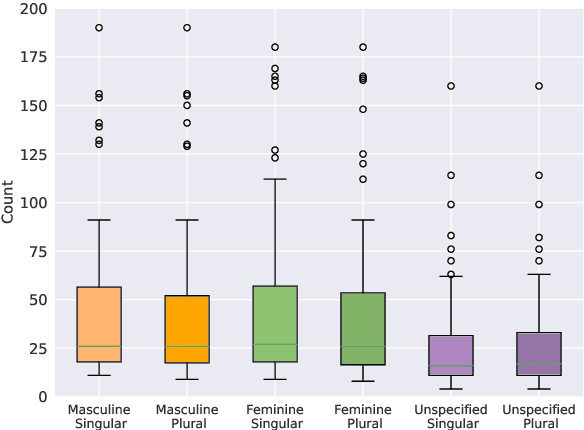
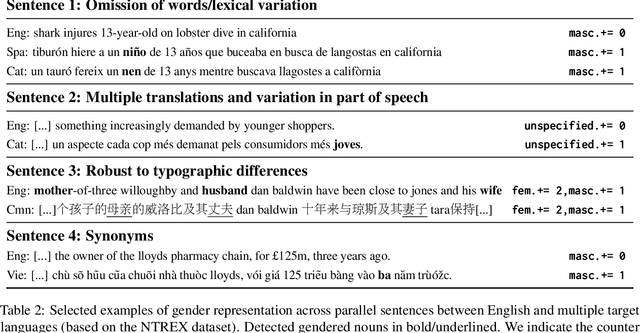
Gender biases in language generation systems are challenging to mitigate. One possible source for these biases is gender representation disparities in the training and evaluation data. Despite recent progress in documenting this problem and many attempts at mitigating it, we still lack shared methodology and tooling to report gender representation in large datasets. Such quantitative reporting will enable further mitigation, e.g., via data augmentation. This paper describes the Gender-GAP Pipeline (for Gender-Aware Polyglot Pipeline), an automatic pipeline to characterize gender representation in large-scale datasets for 55 languages. The pipeline uses a multilingual lexicon of gendered person-nouns to quantify the gender representation in text. We showcase it to report gender representation in WMT training data and development data for the News task, confirming that current data is skewed towards masculine representation. Having unbalanced datasets may indirectly optimize our systems towards outperforming one gender over the others. We suggest introducing our gender quantification pipeline in current datasets and, ideally, modifying them toward a balanced representation.
Evaluating and Modeling Attribution for Cross-Lingual Question Answering
May 23, 2023



Trustworthy answer content is abundant in many high-resource languages and is instantly accessible through question answering systems, yet this content can be hard to access for those that do not speak these languages. The leap forward in cross-lingual modeling quality offered by generative language models offers much promise, yet their raw generations often fall short in factuality. To improve trustworthiness in these systems, a promising direction is to attribute the answer to a retrieved source, possibly in a content-rich language different from the query. Our work is the first to study attribution for cross-lingual question answering. First, we collect data in 5 languages to assess the attribution level of a state-of-the-art cross-lingual QA system. To our surprise, we find that a substantial portion of the answers is not attributable to any retrieved passages (up to 50% of answers exactly matching a gold reference) despite the system being able to attend directly to the retrieved text. Second, to address this poor attribution level, we experiment with a wide range of attribution detection techniques. We find that Natural Language Inference models and PaLM 2 fine-tuned on a very small amount of attribution data can accurately detect attribution. Based on these models, we improve the attribution level of a cross-lingual question-answering system. Overall, we show that current academic generative cross-lingual QA systems have substantial shortcomings in attribution and we build tooling to mitigate these issues.
In What Languages are Generative Language Models the Most Formal? Analyzing Formality Distribution across Languages
Feb 23, 2023



Multilingual generative language models (LMs) are increasingly fluent in a large variety of languages. Trained on the concatenation of corpora in multiple languages, they enable powerful transfer from high-resource languages to low-resource ones. However, it is still unknown what cultural biases are induced in the predictions of these models. In this work, we focus on one language property highly influenced by culture: formality. We analyze the formality distributions of XGLM and BLOOM's predictions, two popular generative multilingual language models, in 5 languages. We classify 1,200 generations per language as formal, informal, or incohesive and measure the impact of the prompt formality on the predictions. Overall, we observe a diversity of behaviors across the models and languages. For instance, XGLM generates informal text in Arabic and Bengali when conditioned with informal prompts, much more than BLOOM. In addition, even though both models are highly biased toward the formal style when prompted neutrally, we find that the models generate a significant amount of informal predictions even when prompted with formal text. We release with this work 6,000 annotated samples, paving the way for future work on the formality of generative multilingual LMs.
Languages You Know Influence Those You Learn: Impact of Language Characteristics on Multi-Lingual Text-to-Text Transfer
Dec 04, 2022



Multi-lingual language models (LM), such as mBERT, XLM-R, mT5, mBART, have been remarkably successful in enabling natural language tasks in low-resource languages through cross-lingual transfer from high-resource ones. In this work, we try to better understand how such models, specifically mT5, transfer *any* linguistic and semantic knowledge across languages, even though no explicit cross-lingual signals are provided during pre-training. Rather, only unannotated texts from each language are presented to the model separately and independently of one another, and the model appears to implicitly learn cross-lingual connections. This raises several questions that motivate our study, such as: Are the cross-lingual connections between every language pair equally strong? What properties of source and target language impact the strength of cross-lingual transfer? Can we quantify the impact of those properties on the cross-lingual transfer? In our investigation, we analyze a pre-trained mT5 to discover the attributes of cross-lingual connections learned by the model. Through a statistical interpretation framework over 90 language pairs across three tasks, we show that transfer performance can be modeled by a few linguistic and data-derived features. These observations enable us to interpret cross-lingual understanding of the mT5 model. Through these observations, one can favorably choose the best source language for a task, and can anticipate its training data demands. A key finding of this work is that similarity of syntax, morphology and phonology are good predictors of cross-lingual transfer, significantly more than just the lexical similarity of languages. For a given language, we are able to predict zero-shot performance, that increases on a logarithmic scale with the number of few-shot target language data points.