 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuTox: Universal MUltilingual Audio-based TOXicity Dataset and Zero-shot Detector
Jan 10, 2024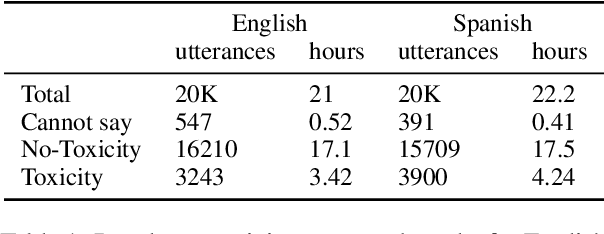
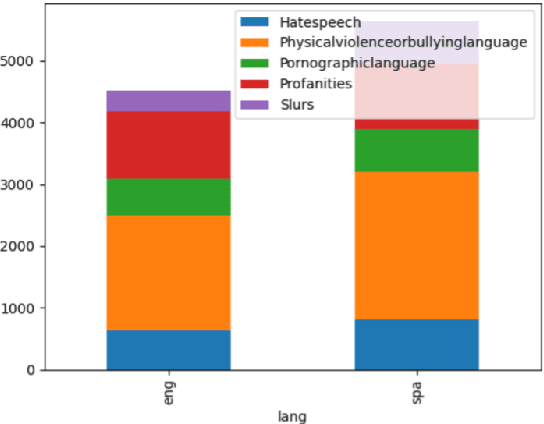
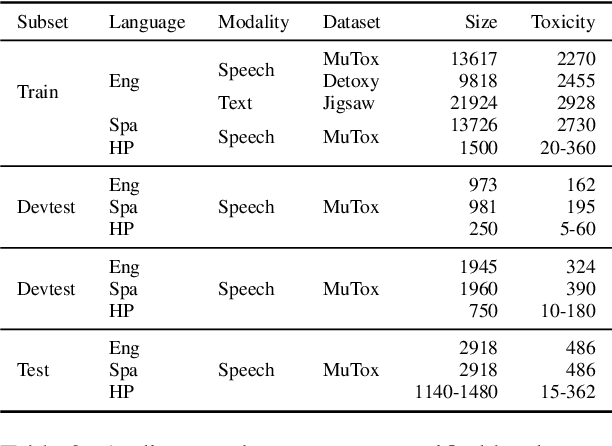
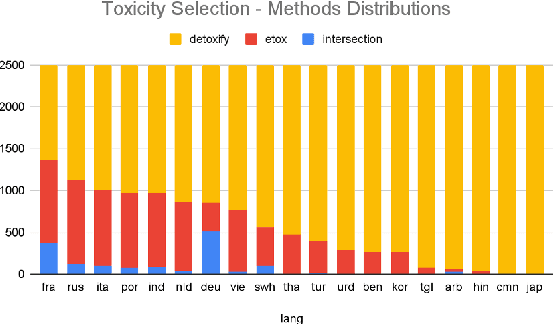
Research in toxicity detection in natural language processing for the speech modality (audio-based) is quite limited, particularly for languages other than English. To address these limitations and lay the groundwork for truly multilingual audio-based toxicity detection, we introduce MuTox, the first highly multilingual audio-based dataset with toxicity labels. The dataset comprises 20,000 audio utterances for English and Spanish, and 4,000 for the other 19 languages. To demonstrate the quality of this dataset, we trained the MuTox audio-based toxicity classifier, which enables zero-shot toxicity detection across a wide range of languages. This classifier outperforms existing text-based trainable classifiers by more than 1% AUC, while expanding the language coverage more than tenfold. When compared to a wordlist-based classifier that covers a similar number of languages, MuTox improves precision and recall by approximately 2.5 times. This significant improvement underscores the potential of MuTox in advancing the field of audio-based toxicity detection.
Seamless: Multilingual Expressive and Streaming Speech Translation
Dec 08, 2023



Large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model-SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. SeamlessM4T v2 provides the foundation on which our next two models are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one's voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. The contributions to this work are publicly released and accessible at https://github.com/facebookresearch/seamless_communication
The Gender-GAP Pipeline: A Gender-Aware Polyglot Pipeline for Gender Characterisation in 55 Languages
Aug 31, 2023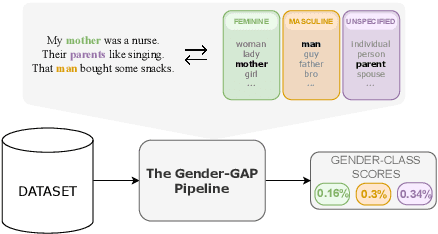
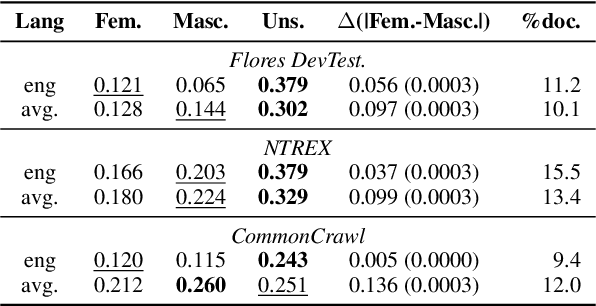
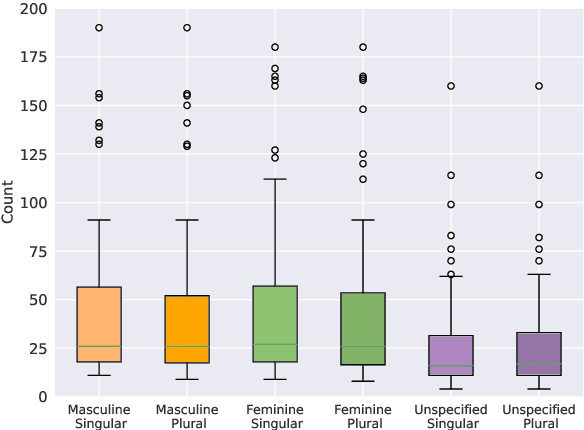
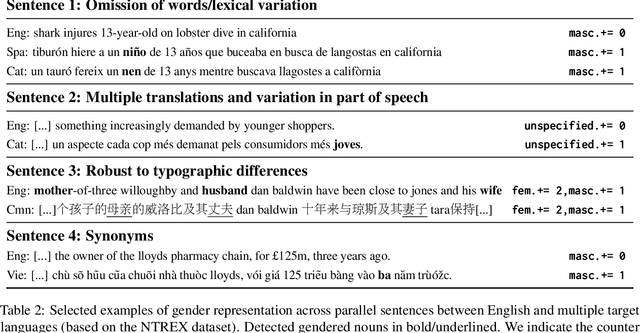
Gender biases in language generation systems are challenging to mitigate. One possible source for these biases is gender representation disparities in the training and evaluation data. Despite recent progress in documenting this problem and many attempts at mitigating it, we still lack shared methodology and tooling to report gender representation in large datasets. Such quantitative reporting will enable further mitigation, e.g., via data augmentation. This paper describes the Gender-GAP Pipeline (for Gender-Aware Polyglot Pipeline), an automatic pipeline to characterize gender representation in large-scale datasets for 55 languages. The pipeline uses a multilingual lexicon of gendered person-nouns to quantify the gender representation in text. We showcase it to report gender representation in WMT training data and development data for the News task, confirming that current data is skewed towards masculine representation. Having unbalanced datasets may indirectly optimize our systems towards outperforming one gender over the others. We suggest introducing our gender quantification pipeline in current datasets and, ideally, modifying them toward a balanced representation.
SeamlessM4T-Massively Multilingual & Multimodal Machine Translation
Aug 23, 2023



What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication
Multilingual Holistic Bias: Extending Descriptors and Patterns to Unveil Demographic Biases in Languages at Scale
May 22, 2023



We introduce a multilingual extension of the HOLISTICBIAS dataset, the largest English template-based taxonomy of textual people references: MULTILINGUALHOLISTICBIAS. This extension consists of 20,459 sentences in 50 languages distributed across all 13 demographic axes. Source sentences are built from combinations of 118 demographic descriptors and three patterns, excluding nonsensical combinations. Multilingual translations include alternatives for gendered languages that cover gendered translations when there is ambiguity in English. Our benchmark is intended to uncover demographic imbalances and be the tool to quantify mitigations towards them. Our initial findings show that translation quality for EN-to-XX translations is an average of 8 spBLEU better when evaluating with the masculine human reference compared to feminine. In the opposite direction, XX-to-EN, we compare the robustness of the model when the source input only differs in gender (masculine or feminine) and masculine translations are an average of almost 4 spBLEU better than feminine. When embedding sentences to a joint multilingual sentence representations space, we find that for most languages masculine translations are significantly closer to the English neutral sentences when embedded.
HalOmi: A Manually Annotated Benchmark for Multilingual Hallucination and Omission Detection in Machine Translation
May 19, 2023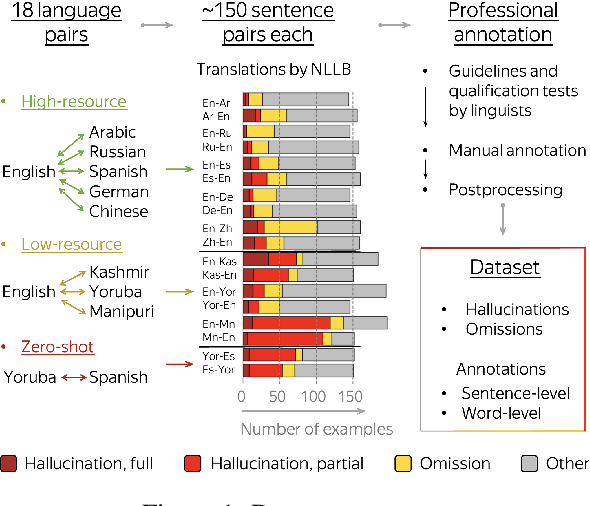


Hallucinations in machine translation are translations that contain information completely unrelated to the input. Omissions are translations that do not include some of the input information. While both cases tend to be catastrophic errors undermining user trust, annotated data with these types of pathologies is extremely scarce and is limited to a few high-resource languages. In this work, we release an annotated dataset for the hallucination and omission phenomena covering 18 translation directions with varying resource levels and scripts. Our annotation covers different levels of partial and full hallucinations as well as omissions both at the sentence and at the word level. Additionally, we revisit previous methods for hallucination and omission detection, show that conclusions made based on a single language pair largely do not hold for a large-scale evaluation, and establish new solid baselines.
No Language Left Behind: Scaling Human-Centered Machine Translation
Jul 11, 2022
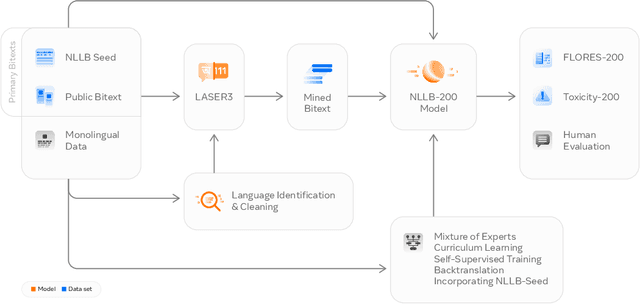
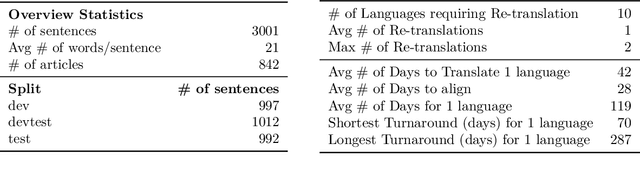
Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today. However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the 200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety. Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system. Finally, we open source all contributions described in this work, accessible at https://github.com/facebookresearch/fairseq/tree/nllb.