 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLM Transparency Tool: Interactive Tool for Analyzing Transformer Language Models
Apr 10, 2024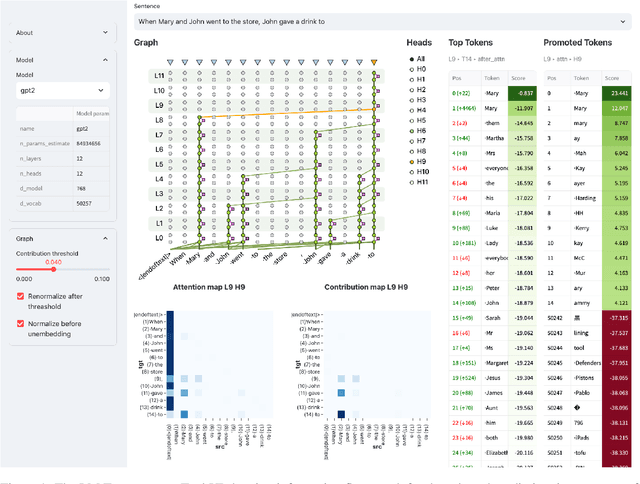
We present the LM Transparency Tool (LM-TT), an open-source interactive toolkit for analyzing the internal workings of Transformer-based language models. Differently from previously existing tools that focus on isolated parts of the decision-making process, our framework is designed to make the entire prediction process transparent, and allows tracing back model behavior from the top-layer representation to very fine-grained parts of the model. Specifically, it (1) shows the important part of the whole input-to-output information flow, (2) allows attributing any changes done by a model block to individual attention heads and feed-forward neurons, (3) allows interpreting the functions of those heads or neurons. A crucial part of this pipeline is showing the importance of specific model components at each step. As a result, we are able to look at the roles of model components only in cases where they are important for a prediction. Since knowing which components should be inspected is key for analyzing large models where the number of these components is extremely high, we believe our tool will greatly support the interpretability community both in research settings and in practical applications.
Know When To Stop: A Study of Semantic Drift in Text Generation
Apr 08, 2024
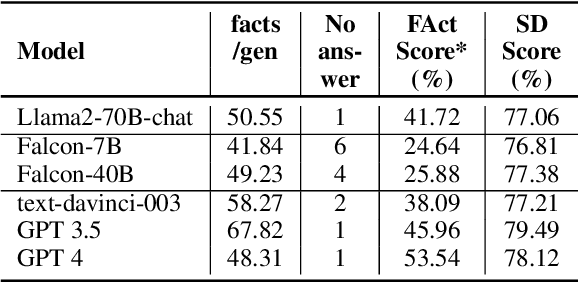

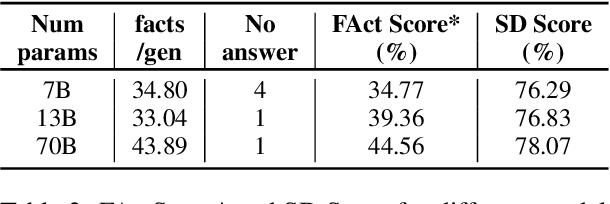
In this work, we explicitly show that modern LLMs tend to generate correct facts first, then "drift away" and generate incorrect facts later: this was occasionally observed but never properly measured. We develop a semantic drift score that measures the degree of separation between correct and incorrect facts in generated texts and confirm our hypothesis when generating Wikipedia-style biographies. This correct-then-incorrect generation pattern suggests that factual accuracy can be improved by knowing when to stop generation. Therefore, we explore the trade-off between information quantity and factual accuracy for several early stopping methods and manage to improve factuality by a large margin. We further show that reranking with semantic similarity can further improve these results, both compared to the baseline and when combined with early stopping. Finally, we try calling external API to bring the model back to the right generation path, but do not get positive results. Overall, our methods generalize and can be applied to any long-form text generation to produce more reliable information, by balancing trade-offs between factual accuracy, information quantity and computational cost.
Information Flow Routes: Automatically Interpreting Language Models at Scale
Feb 27, 2024Information flows by routes inside the network via mechanisms implemented in the model. These routes can be represented as graphs where nodes correspond to token representations and edges to operations inside the network. We automatically build these graphs in a top-down manner, for each prediction leaving only the most important nodes and edges. In contrast to the existing workflows relying on activation patching, we do this through attribution: this allows us to efficiently uncover existing circuits with just a single forward pass. Additionally, the applicability of our method is far beyond patching: we do not need a human to carefully design prediction templates, and we can extract information flow routes for any prediction (not just the ones among the allowed templates). As a result, we can talk about model behavior in general, for specific types of predictions, or different domains. We experiment with Llama 2 and show that the role of some attention heads is overall important, e.g. previous token heads and subword merging heads. Next, we find similarities in Llama 2 behavior when handling tokens of the same part of speech. Finally, we show that some model components can be specialized on domains such as coding or multilingual texts.
Neurons in Large Language Models: Dead, N-gram, Positional
Sep 09, 2023We analyze a family of large language models in such a lightweight manner that can be done on a single GPU. Specifically, we focus on the OPT family of models ranging from 125m to 66b parameters and rely only on whether an FFN neuron is activated or not. First, we find that the early part of the network is sparse and represents many discrete features. Here, many neurons (more than 70% in some layers of the 66b model) are "dead", i.e. they never activate on a large collection of diverse data. At the same time, many of the alive neurons are reserved for discrete features and act as token and n-gram detectors. Interestingly, their corresponding FFN updates not only promote next token candidates as could be expected, but also explicitly focus on removing the information about triggering them tokens, i.e., current input. To the best of our knowledge, this is the first example of mechanisms specialized at removing (rather than adding) information from the residual stream. With scale, models become more sparse in a sense that they have more dead neurons and token detectors. Finally, some neurons are positional: them being activated or not depends largely (or solely) on position and less so (or not at all) on textual data. We find that smaller models have sets of neurons acting as position range indicators while larger models operate in a less explicit manner.
HalOmi: A Manually Annotated Benchmark for Multilingual Hallucination and Omission Detection in Machine Translation
May 19, 2023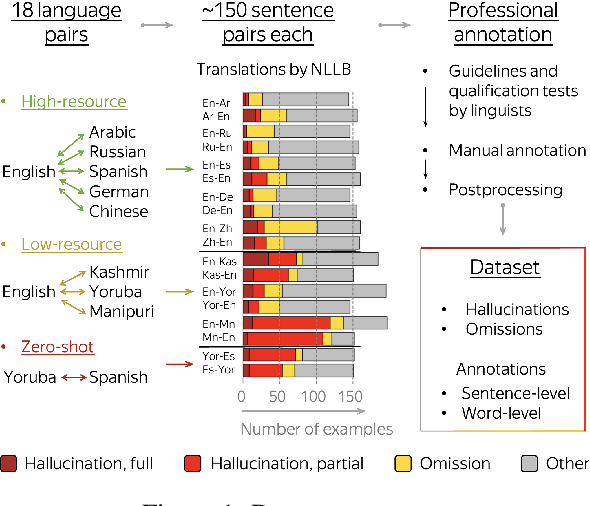
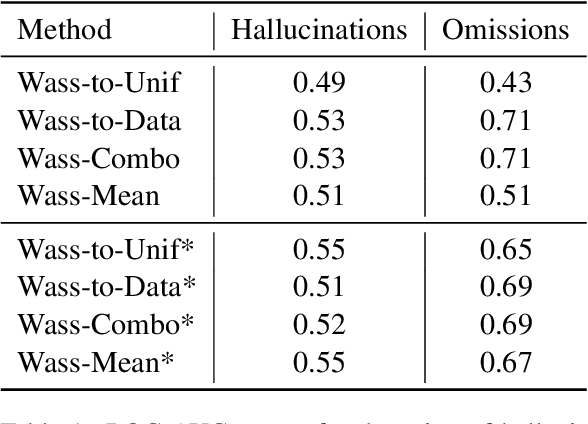


Hallucinations in machine translation are translations that contain information completely unrelated to the input. Omissions are translations that do not include some of the input information. While both cases tend to be catastrophic errors undermining user trust, annotated data with these types of pathologies is extremely scarce and is limited to a few high-resource languages. In this work, we release an annotated dataset for the hallucination and omission phenomena covering 18 translation directions with varying resource levels and scripts. Our annotation covers different levels of partial and full hallucinations as well as omissions both at the sentence and at the word level. Additionally, we revisit previous methods for hallucination and omission detection, show that conclusions made based on a single language pair largely do not hold for a large-scale evaluation, and establish new solid baselines.
Detecting and Mitigating Hallucinations in Machine Translation: Model Internal Workings Alone Do Well, Sentence Similarity Even Better
Dec 20, 2022While the problem of hallucinations in neural machine translation has long been recognized, so far the progress on its alleviation is very little. Indeed, recently it turned out that without artificially encouraging models to hallucinate, previously existing methods fall short and even the standard sequence log-probability is more informative. It means that characteristics internal to the model can give much more information than we expect, and before using external models and measures, we first need to ask: how far can we go if we use nothing but the translation model itself ? We propose to use a method that evaluates the percentage of the source contribution to a generated translation. Intuitively, hallucinations are translations "detached" from the source, hence they can be identified by low source contribution. This method improves detection accuracy for the most severe hallucinations by a factor of 2 and is able to alleviate hallucinations at test time on par with the previous best approach that relies on external models. Next, if we move away from internal model characteristics and allow external tools, we show that using sentence similarity from cross-lingual embeddings further improves these results.
Looking for a Needle in a Haystack: A Comprehensive Study of Hallucinations in Neural Machine Translation
Aug 10, 2022

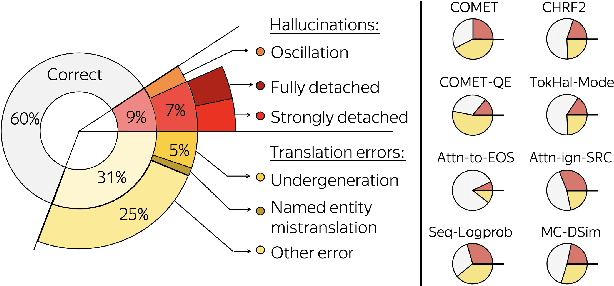

Although the problem of hallucinations in neural machine translation (NMT) has received some attention, research on this highly pathological phenomenon lacks solid ground. Previous work has been limited in several ways: it often resorts to artificial settings where the problem is amplified, it disregards some (common) types of hallucinations, and it does not validate adequacy of detection heuristics. In this paper, we set foundations for the study of NMT hallucinations. First, we work in a natural setting, i.e., in-domain data without artificial noise neither in training nor in inference. Next, we annotate a dataset of over 3.4k sentences indicating different kinds of critical errors and hallucinations. Then, we turn to detection methods and both revisit methods used previously and propose using glass-box uncertainty-based detectors. Overall, we show that for preventive settings, (i) previously used methods are largely inadequate, (ii) sequence log-probability works best and performs on par with reference-based methods. Finally, we propose DeHallucinator, a simple method for alleviating hallucinations at test time that significantly reduces the hallucinatory rate. To ease future research, we release our annotated dataset for WMT18 German-English data, along with the model, training data, and code.
Language Modeling, Lexical Translation, Reordering: The Training Process of NMT through the Lens of Classical SMT
Sep 03, 2021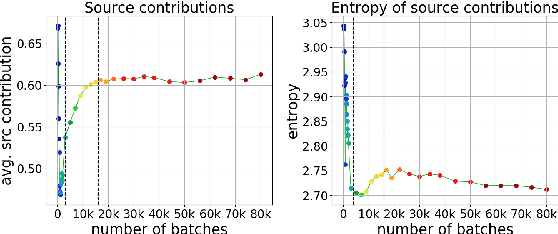
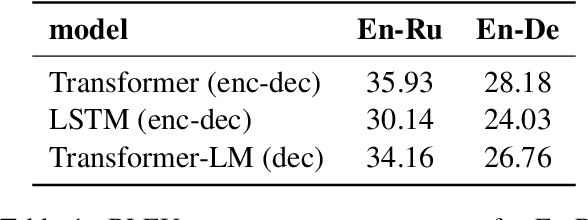
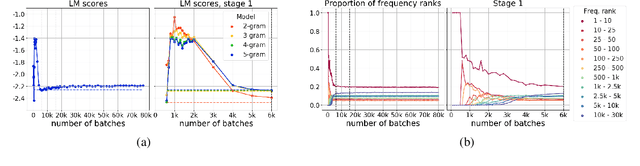

Differently from the traditional statistical MT that decomposes the translation task into distinct separately learned components, neural machine translation uses a single neural network to model the entire translation process. Despite neural machine translation being de-facto standard, it is still not clear how NMT models acquire different competences over the course of training, and how this mirrors the different models in traditional SMT. In this work, we look at the competences related to three core SMT components and find that during training, NMT first focuses on learning target-side language modeling, then improves translation quality approaching word-by-word translation, and finally learns more complicated reordering patterns. We show that this behavior holds for several models and language pairs. Additionally, we explain how such an understanding of the training process can be useful in practice and, as an example, show how it can be used to improve vanilla non-autoregressive neural machine translation by guiding teacher model selection.
Analyzing the Source and Target Contributions to Predictions in Neural Machine Translation
Oct 21, 2020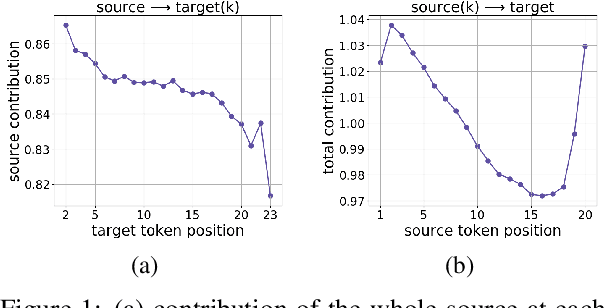
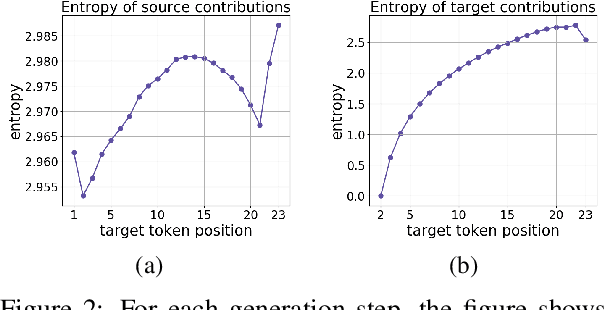
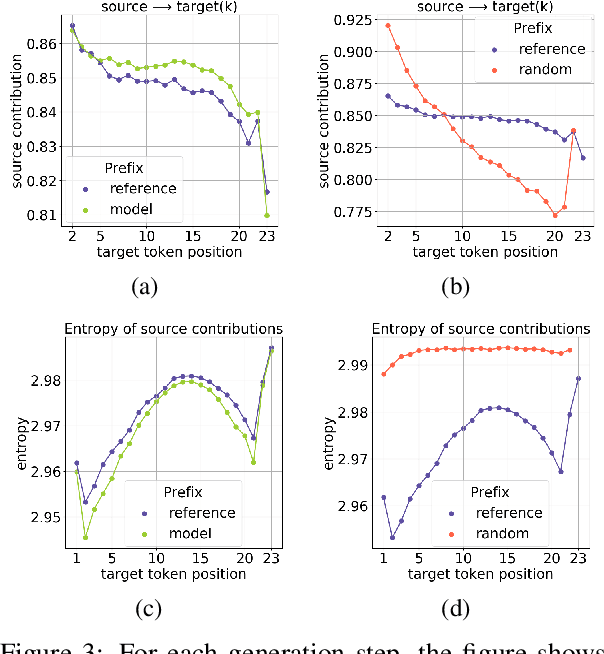
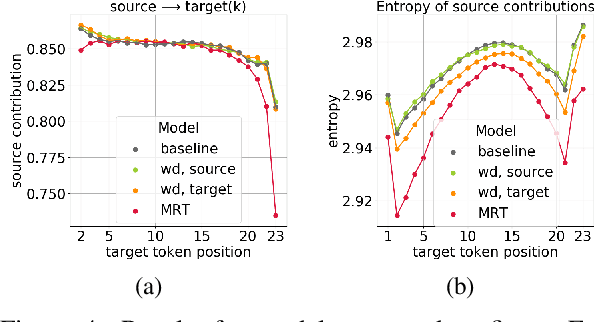
In Neural Machine Translation (and, more generally, conditional language modeling), the generation of a target token is influenced by two types of context: the source and the prefix of the target sequence. While many attempts to understand the internal workings of NMT models have been made, none of them explicitly evaluates relative source and target contributions to a generation decision. We argue that this relative contribution can be evaluated by adopting a variant of Layerwise Relevance Propagation (LRP). Its underlying 'conservation principle' makes relevance propagation unique: differently from other methods, it evaluates not an abstract quantity reflecting token importance, but the proportion of each token's influence. We extend LRP to the Transformer and conduct an analysis of NMT models which explicitly evaluates the source and target relative contributions to the generation process. We analyze changes in these contributions when conditioning on different types of prefixes, when varying the training objective or the amount of training data, and during the training process. We find that models trained with more data tend to rely on source information more and to have more sharp token contributions; the training process is non-monotonic with several stages of different nature.
Embedding Words in Non-Vector Space with Unsupervised Graph Learning
Oct 06, 2020
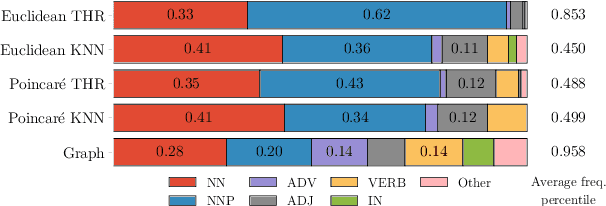
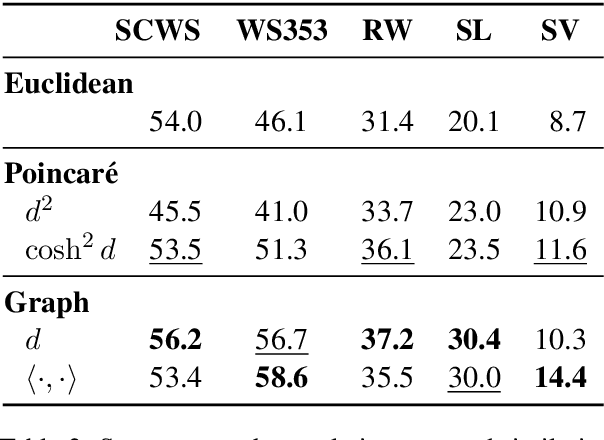
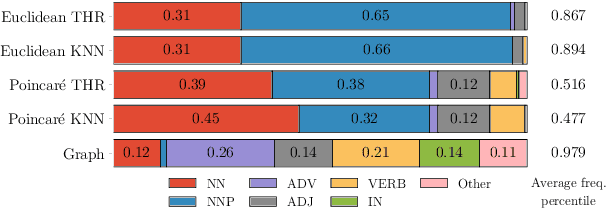
It has become a de-facto standard to represent words as elements of a vector space (word2vec, GloVe). While this approach is convenient, it is unnatural for language: words form a graph with a latent hierarchical structure, and this structure has to be revealed and encoded by word embeddings. We introduce GraphGlove: unsupervised graph word representations which are learned end-to-end. In our setting, each word is a node in a weighted graph and the distance between words is the shortest path distance between the corresponding nodes. We adopt a recent method learning a representation of data in the form of a differentiable weighted graph and use it to modify the GloVe training algorithm. We show that our graph-based representations substantially outperform vector-based methods on word similarity and analogy tasks. Our analysis reveals that the structure of the learned graphs is hierarchical and similar to that of WordNet, the geometry is highly non-trivial and contains subgraphs with different local topology.