 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Words in Non-Vector Space with Unsupervised Graph Learning
Paper and Code

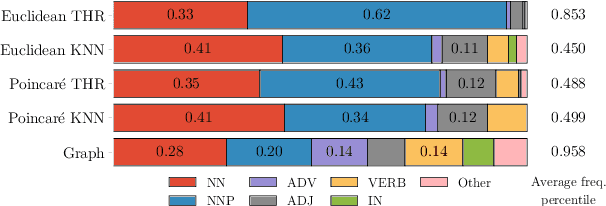
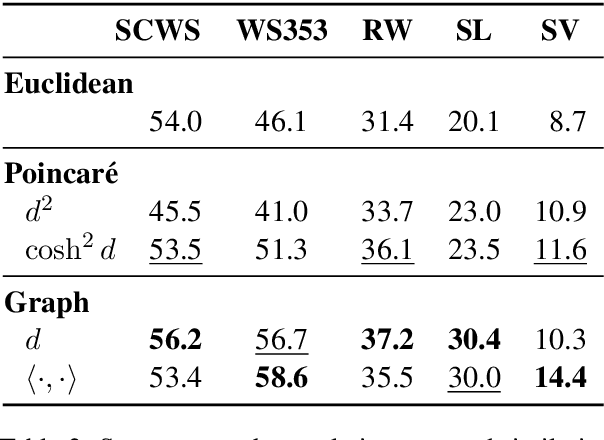
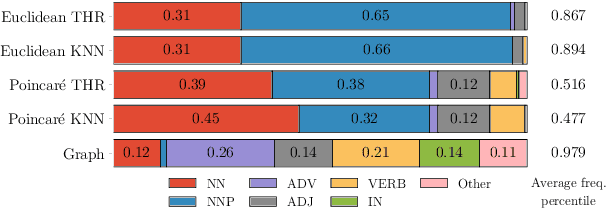
It has become a de-facto standard to represent words as elements of a vector space (word2vec, GloVe). While this approach is convenient, it is unnatural for language: words form a graph with a latent hierarchical structure, and this structure has to be revealed and encoded by word embeddings. We introduce GraphGlove: unsupervised graph word representations which are learned end-to-end. In our setting, each word is a node in a weighted graph and the distance between words is the shortest path distance between the corresponding nodes. We adopt a recent method learning a representation of data in the form of a differentiable weighted graph and use it to modify the GloVe training algorithm. We show that our graph-based representations substantially outperform vector-based methods on word similarity and analogy tasks. Our analysis reveals that the structure of the learned graphs is hierarchical and similar to that of WordNet, the geometry is highly non-trivial and contains subgraphs with different local topology.