 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimental Validation of Coherent Joint Transmission in a Distributed-MIMO System with Analog Fronthaul for 6G
May 04, 2023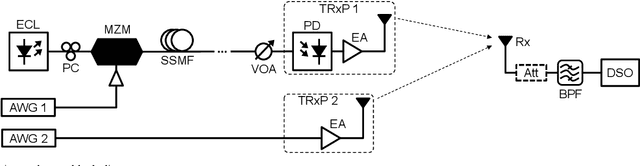

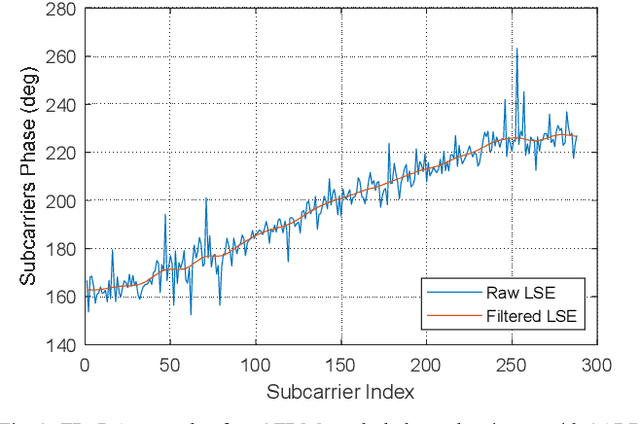
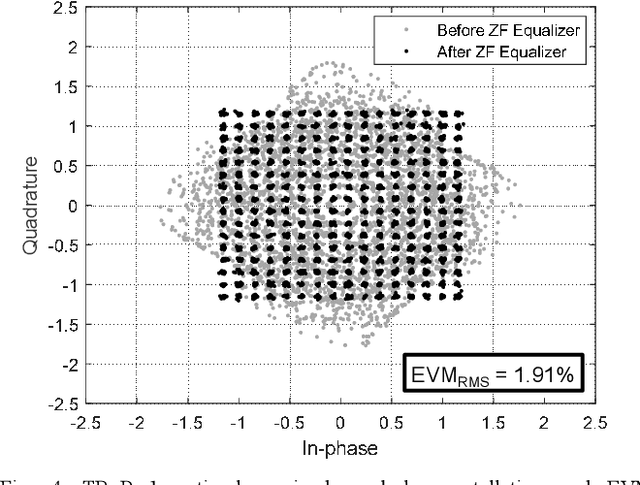
The sixth-generation (6G) mobile networks must increase coverage and improve spectral efficiency, especially for cell-edge users. Distributed multiple-input multiple-output (D-MIMO) networks can fulfill these requirements provided that transmission/reception points (TRxPs) of the network can be synchronized with sub nanosecond precision, however, synchronization with current backhaul and fronthaul digital interfaces is challenging. For 6G new services and scenarios, analog radio-over-fiber (ARoF) is a prospective alternative for future mobile fronthaul where current solutions fall short to fulfill future demands on bandwidth, synchronization, and/or power consumption. This paper presents an experimental validation of coherent joint transmissions (CJTs) in a two TRxPs D-MIMO network where ARoF fronthaul links allow to meet the required level of synchronization. Results show that by means of CJT a combined diversity and power gain of +5 dB is realized in comparison with a single TRxP transmission.
NR Conformance Testing of Analog Radio-over-LWIR FSO Fronthaul link for 6G Distributed MIMO Networks
Feb 09, 2023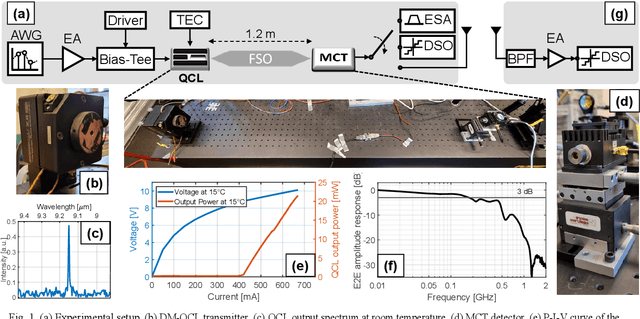
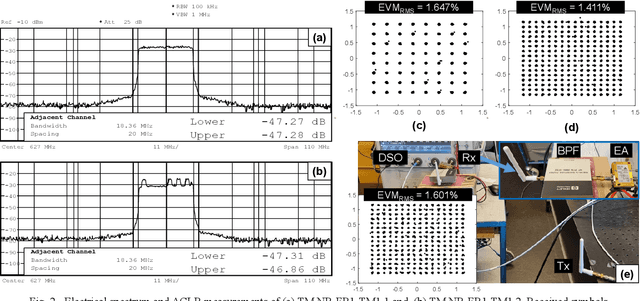
We experimentally test the compliance with 5G/NR 3GPP technical specifications of an analog radio-over-FSO link at 9 {\mu}m. The ACLR and EVM transmitter requirements are fulfilled validating the suitability of LWIR FSO for 6G fronthaul.
Symbolic expression generation via Variational Auto-Encoder
Jan 15, 2023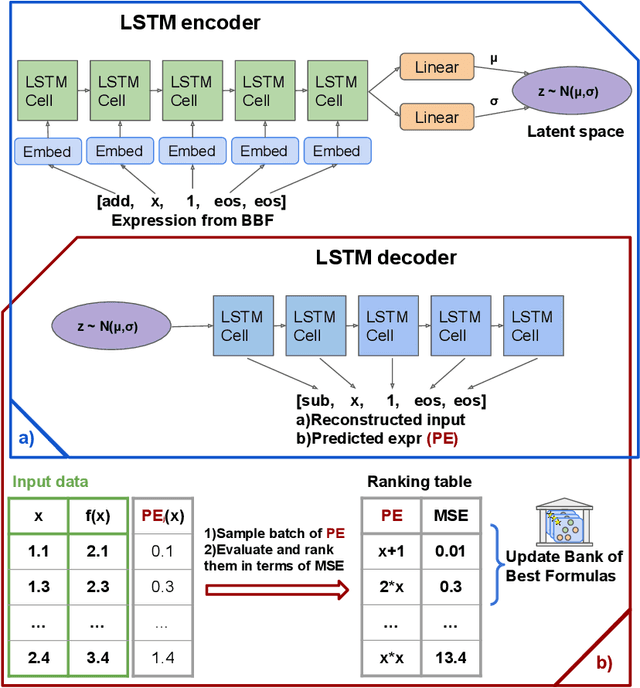

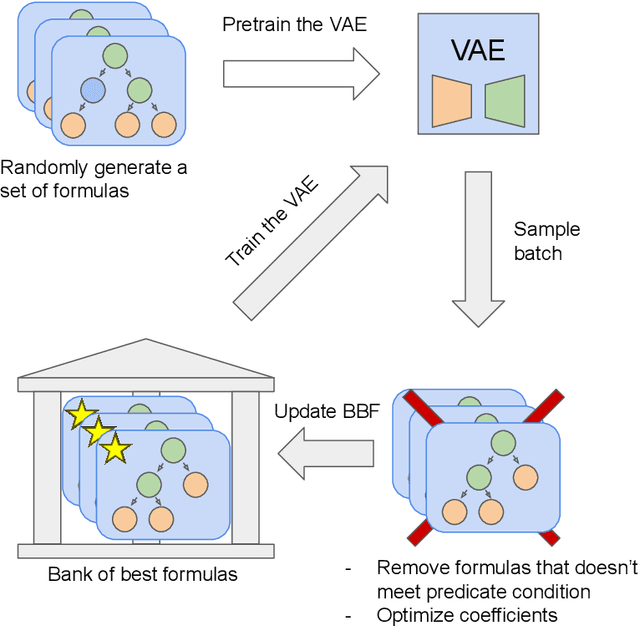

There are many problems in physics, biology, and other natural sciences in which symbolic regression can provide valuable insights and discover new laws of nature. A widespread Deep Neural Networks do not provide interpretable solutions. Meanwhile, symbolic expressions give us a clear relation between observations and the target variable. However, at the moment, there is no dominant solution for the symbolic regression task, and we aim to reduce this gap with our algorithm. In this work, we propose a novel deep learning framework for symbolic expression generation via variational autoencoder (VAE). In a nutshell, we suggest using a VAE to generate mathematical expressions, and our training strategy forces generated formulas to fit a given dataset. Our framework allows encoding apriori knowledge of the formulas into fast-check predicates that speed up the optimization process. We compare our method to modern symbolic regression benchmarks and show that our method outperforms the competitors under noisy conditions. The recovery rate of SEGVAE is 65% on the Ngyuen dataset with a noise level of 10%, which is better than the previously reported SOTA by 20%. We demonstrate that this value depends on the dataset and can be even higher.
Embedding Words in Non-Vector Space with Unsupervised Graph Learning
Oct 06, 2020
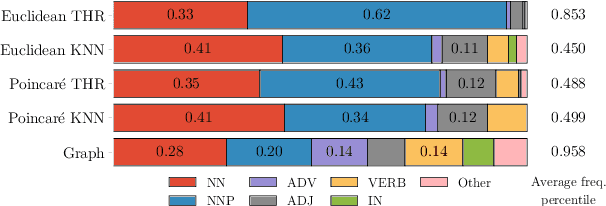
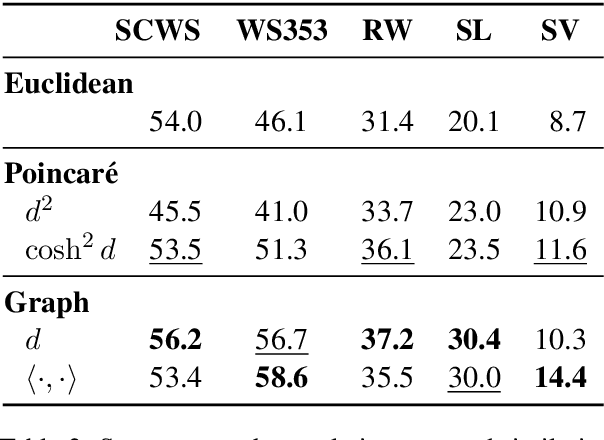
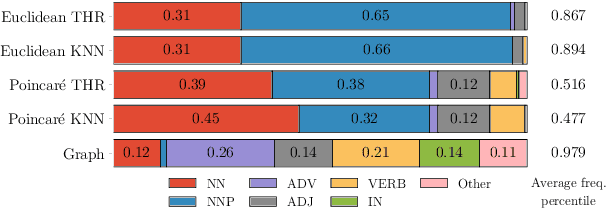
It has become a de-facto standard to represent words as elements of a vector space (word2vec, GloVe). While this approach is convenient, it is unnatural for language: words form a graph with a latent hierarchical structure, and this structure has to be revealed and encoded by word embeddings. We introduce GraphGlove: unsupervised graph word representations which are learned end-to-end. In our setting, each word is a node in a weighted graph and the distance between words is the shortest path distance between the corresponding nodes. We adopt a recent method learning a representation of data in the form of a differentiable weighted graph and use it to modify the GloVe training algorithm. We show that our graph-based representations substantially outperform vector-based methods on word similarity and analogy tasks. Our analysis reveals that the structure of the learned graphs is hierarchical and similar to that of WordNet, the geometry is highly non-trivial and contains subgraphs with different local topology.
Editable Neural Networks
Apr 01, 2020



These days deep neural networks are ubiquitously used in a wide range of tasks, from image classification and machine translation to face identification and self-driving cars. In many applications, a single model error can lead to devastating financial, reputational and even life-threatening consequences. Therefore, it is crucially important to correct model mistakes quickly as they appear. In this work, we investigate the problem of neural network editing $-$ how one can efficiently patch a mistake of the model on a particular sample, without influencing the model behavior on other samples. Namely, we propose Editable Training, a model-agnostic training technique that encourages fast editing of the trained model. We empirically demonstrate the effectiveness of this method on large-scale image classification and machine translation tasks.
Neural Oblivious Decision Ensembles for Deep Learning on Tabular Data
Sep 19, 2019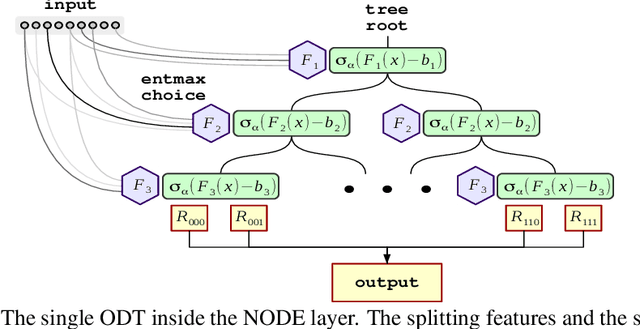

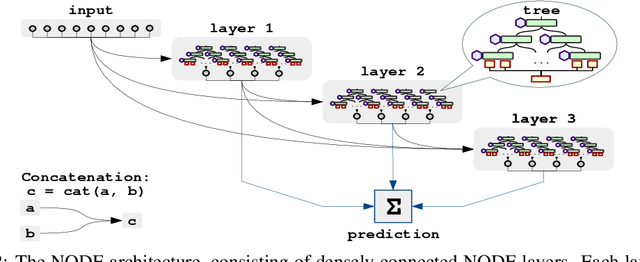

Nowadays, deep neural networks (DNNs) have become the main instrument for machine learning tasks within a wide range of domains, including vision, NLP, and speech. Meanwhile, in an important case of heterogenous tabular data, the advantage of DNNs over shallow counterparts remains questionable. In particular, there is no sufficient evidence that deep learning machinery allows constructing methods that outperform gradient boosting decision trees (GBDT), which are often the top choice for tabular problems. In this paper, we introduce Neural Oblivious Decision Ensembles (NODE), a new deep learning architecture, designed to work with any tabular data. In a nutshell, the proposed NODE architecture generalizes ensembles of oblivious decision trees, but benefits from both end-to-end gradient-based optimization and the power of multi-layer hierarchical representation learning. With an extensive experimental comparison to the leading GBDT packages on a large number of tabular datasets, we demonstrate the advantage of the proposed NODE architecture, which outperforms the competitors on most of the tasks. We open-source the PyTorch implementation of NODE and believe that it will become a universal framework for machine learning on tabular data.