 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMashup Learning: Faster Finetuning by Remixing Past Checkpoints
Mar 10, 2026Finetuning on domain-specific data is a well-established method for enhancing LLM performance on downstream tasks. Training on each dataset produces a new set of model weights, resulting in a multitude of checkpoints saved in-house or on open-source platforms. However, these training artifacts are rarely reused for subsequent experiments despite containing improved model abilities for potentially similar tasks. In this paper, we propose Mashup Learning, a simple method to leverage the outputs of prior training runs to enhance model adaptation to new tasks. Our procedure identifies the most relevant historical checkpoints for a target dataset, aggregates them with model merging, and uses the result as an improved initialization for training. Across 8 standard LLM benchmarks, four models, and two collections of source checkpoints, Mashup Learning consistently improves average downstream accuracy by 0.5-5 percentage points over training from scratch. It also accelerates convergence, requiring 41-46% fewer training steps and up to 37% less total wall-clock time to match from-scratch accuracy, including all selection and merging overhead.
Untied Ulysses: Memory-Efficient Context Parallelism via Headwise Chunking
Feb 24, 2026Efficiently processing long sequences with Transformer models usually requires splitting the computations across accelerators via context parallelism. The dominant approaches in this family of methods, such as Ring Attention or DeepSpeed Ulysses, enable scaling over the context dimension but do not focus on memory efficiency, which limits the sequence lengths they can support. More advanced techniques, such as Fully Pipelined Distributed Transformer or activation offloading, can further extend the possible context length at the cost of training throughput. In this paper, we present UPipe, a simple yet effective context parallelism technique that performs fine-grained chunking at the attention head level. This technique significantly reduces the activation memory usage of self-attention, breaking the activation memory barrier and unlocking much longer context lengths. Our approach reduces intermediate tensor memory usage in the attention layer by as much as 87.5$\%$ for 32B Transformers, while matching previous context parallelism techniques in terms of training speed. UPipe can support the context length of 5M tokens when training Llama3-8B on a single 8$\times$H100 node, improving upon prior methods by over 25$\%$.
AutoJudge: Judge Decoding Without Manual Annotation
Apr 28, 2025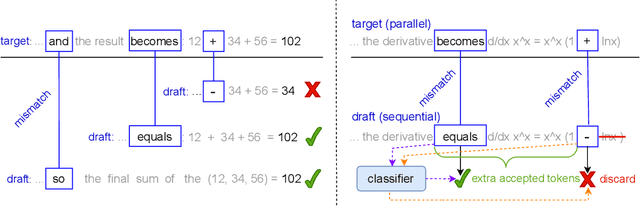

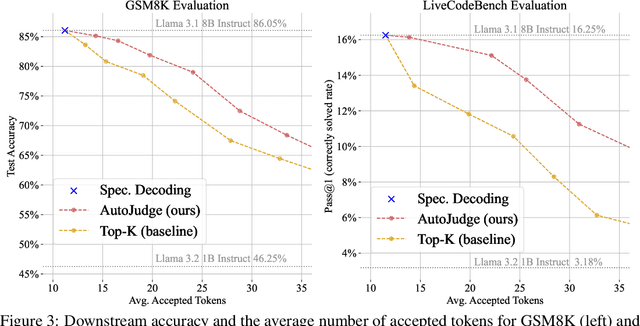
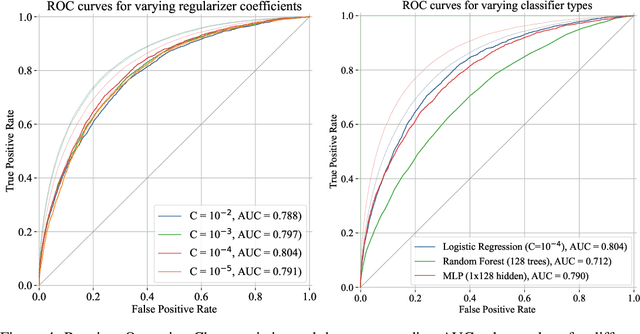
We introduce AutoJudge, a framework that accelerates large language model (LLM) inference with task-specific lossy speculative decoding. Instead of matching the original model output distribution token-by-token, we identify which of the generated tokens affect the downstream quality of the generated response, relaxing the guarantee so that the "unimportant" tokens can be generated faster. Our approach relies on a semi-greedy search algorithm to test which of the mismatches between target and draft model should be corrected to preserve quality, and which ones may be skipped. We then train a lightweight classifier based on existing LLM embeddings to predict, at inference time, which mismatching tokens can be safely accepted without compromising the final answer quality. We test our approach with Llama 3.2 1B (draft) and Llama 3.1 8B (target) models on zero-shot GSM8K reasoning, where it achieves up to 1.5x more accepted tokens per verification cycle with under 1% degradation in answer accuracy compared to standard speculative decoding and over 2x with small loss in accuracy. When applied to the LiveCodeBench benchmark, our approach automatically detects other, programming-specific important tokens and shows similar speedups, demonstrating its ability to generalize across tasks.
Multilingual Language Model Pretraining using Machine-translated Data
Feb 18, 2025High-resource languages such as English, enables the pretraining of high-quality large language models (LLMs). The same can not be said for most other languages as LLMs still underperform for non-English languages, likely due to a gap in the quality and diversity of the available multilingual pretraining corpora. In this work, we find that machine-translated texts from a single high-quality source language can contribute significantly to the pretraining quality of multilingual LLMs. We translate FineWeb-Edu, a high-quality English web dataset, into nine languages, resulting in a 1.7-trillion-token dataset, which we call TransWebEdu and pretrain a 1.3B-parameter model, TransWebLLM, from scratch on this dataset. Across nine non-English reasoning tasks, we show that TransWebLLM matches or outperforms state-of-the-art multilingual models trained using closed data, such as Llama3.2, Qwen2.5, and Gemma, despite using an order of magnitude less data. We demonstrate that adding less than 5% of TransWebEdu as domain-specific pretraining data sets a new state-of-the-art in Arabic, Italian, Indonesian, Swahili, and Welsh understanding and commonsense reasoning tasks. To promote reproducibility, we release our corpus, models, and training pipeline under Open Source Initiative-approved licenses.
Towards Best Practices for Open Datasets for LLM Training
Jan 14, 2025Many AI companies are training their large language models (LLMs) on data without the permission of the copyright owners. The permissibility of doing so varies by jurisdiction: in countries like the EU and Japan, this is allowed under certain restrictions, while in the United States, the legal landscape is more ambiguous. Regardless of the legal status, concerns from creative producers have led to several high-profile copyright lawsuits, and the threat of litigation is commonly cited as a reason for the recent trend towards minimizing the information shared about training datasets by both corporate and public interest actors. This trend in limiting data information causes harm by hindering transparency, accountability, and innovation in the broader ecosystem by denying researchers, auditors, and impacted individuals access to the information needed to understand AI models. While this could be mitigated by training language models on open access and public domain data, at the time of writing, there are no such models (trained at a meaningful scale) due to the substantial technical and sociological challenges in assembling the necessary corpus. These challenges include incomplete and unreliable metadata, the cost and complexity of digitizing physical records, and the diverse set of legal and technical skills required to ensure relevance and responsibility in a quickly changing landscape. Building towards a future where AI systems can be trained on openly licensed data that is responsibly curated and governed requires collaboration across legal, technical, and policy domains, along with investments in metadata standards, digitization, and fostering a culture of openness.
Label Privacy in Split Learning for Large Models with Parameter-Efficient Training
Dec 21, 2024As deep learning models become larger and more expensive, many practitioners turn to fine-tuning APIs. These web services allow fine-tuning a model between two parties: the client that provides the data, and the server that hosts the model. While convenient, these APIs raise a new concern: the data of the client is at risk of privacy breach during the training procedure. This challenge presents an important practical case of vertical federated learning, where the two parties perform parameter-efficient fine-tuning (PEFT) of a large model. In this study, we systematically search for a way to fine-tune models over an API while keeping the labels private. We analyze the privacy of LoRA, a popular approach for parameter-efficient fine-tuning when training over an API. Using this analysis, we propose P$^3$EFT, a multi-party split learning algorithm that takes advantage of existing PEFT properties to maintain privacy at a lower performance overhead. To validate our algorithm, we fine-tune DeBERTa-v2-XXLarge, Flan-T5 Large and LLaMA-2 7B using LoRA adapters on a range of NLP tasks. We find that P$^3$EFT is competitive with existing privacy-preserving methods in multi-party and two-party setups while having higher accuracy.
RedPajama: an Open Dataset for Training Large Language Models
Nov 19, 2024Large language models are increasingly becoming a cornerstone technology in artificial intelligence, the sciences, and society as a whole, yet the optimal strategies for dataset composition and filtering remain largely elusive. Many of the top-performing models lack transparency in their dataset curation and model development processes, posing an obstacle to the development of fully open language models. In this paper, we identify three core data-related challenges that must be addressed to advance open-source language models. These include (1) transparency in model development, including the data curation process, (2) access to large quantities of high-quality data, and (3) availability of artifacts and metadata for dataset curation and analysis. To address these challenges, we release RedPajama-V1, an open reproduction of the LLaMA training dataset. In addition, we release RedPajama-V2, a massive web-only dataset consisting of raw, unfiltered text data together with quality signals and metadata. Together, the RedPajama datasets comprise over 100 trillion tokens spanning multiple domains and with their quality signals facilitate the filtering of data, aiming to inspire the development of numerous new datasets. To date, these datasets have already been used in the training of strong language models used in production, such as Snowflake Arctic, Salesforce's XGen and AI2's OLMo. To provide insight into the quality of RedPajama, we present a series of analyses and ablation studies with decoder-only language models with up to 1.6B parameters. Our findings demonstrate how quality signals for web data can be effectively leveraged to curate high-quality subsets of the dataset, underscoring the potential of RedPajama to advance the development of transparent and high-performing language models at scale.
Multilingual Pretraining Using a Large Corpus Machine-Translated from a Single Source Language
Oct 31, 2024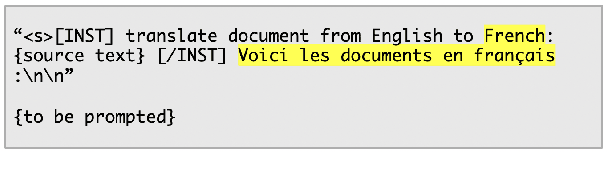
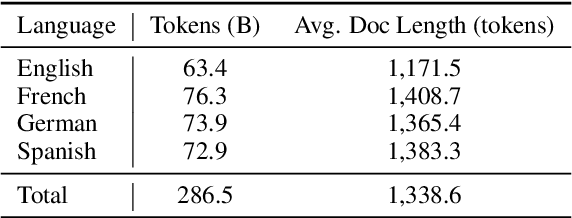
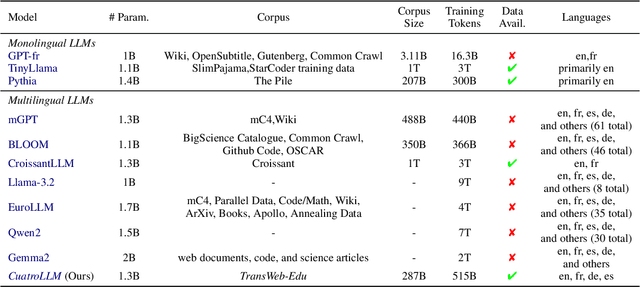
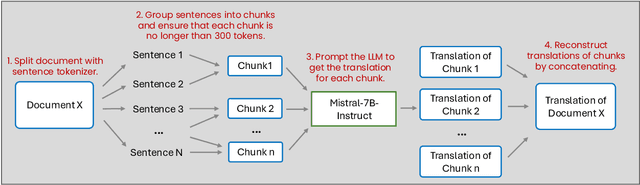
English, as a very high-resource language, enables the pretraining of high-quality large language models (LLMs). The same cannot be said for most other languages, as leading LLMs still underperform for non-English languages, likely due to a gap in the quality and diversity of the available multilingual pretraining corpora. In this work, we find that machine-translated text from a single high-quality source language can contribute significantly to the pretraining of multilingual LLMs. We translate FineWeb-Edu, a high-quality English web dataset, into French, German, and Spanish, resulting in a final 300B-token dataset, which we call TransWeb-Edu, and pretrain a 1.3B-parameter model, CuatroLLM, from scratch on this dataset. Across five non-English reasoning tasks, we show that CuatroLLM matches or outperforms state-of-the-art multilingual models trained using closed data, such as Llama3.2 and Gemma2, despite using an order of magnitude less data, such as about 6% of the tokens used for Llama3.2's training. We further demonstrate that with additional domain-specific pretraining, amounting to less than 1% of TransWeb-Edu, CuatroLLM surpasses the state of the art in multilingual reasoning. To promote reproducibility, we release our corpus, models, and training pipeline under open licenses at hf.co/britllm/CuatroLLM.
SpecExec: Massively Parallel Speculative Decoding for Interactive LLM Inference on Consumer Devices
Jun 04, 2024



As large language models gain widespread adoption, running them efficiently becomes crucial. Recent works on LLM inference use speculative decoding to achieve extreme speedups. However, most of these works implicitly design their algorithms for high-end datacenter hardware. In this work, we ask the opposite question: how fast can we run LLMs on consumer machines? Consumer GPUs can no longer fit the largest available models (50B+ parameters) and must offload them to RAM or SSD. When running with offloaded parameters, the inference engine can process batches of hundreds or thousands of tokens at the same time as just one token, making it a natural fit for speculative decoding. We propose SpecExec (Speculative Execution), a simple parallel decoding method that can generate up to 20 tokens per target model iteration for popular LLM families. It utilizes the high spikiness of the token probabilities distribution in modern LLMs and a high degree of alignment between model output probabilities. SpecExec takes the most probable tokens continuation from the draft model to build a "cache" tree for the target model, which then gets validated in a single pass. Using SpecExec, we demonstrate inference of 50B+ parameter LLMs on consumer GPUs with RAM offloading at 4-6 tokens per second with 4-bit quantization or 2-3 tokens per second with 16-bit weights.
The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models
Apr 08, 2024Large Language Models (LLMs) have transformed the Natural Language Processing (NLP) landscape with their remarkable ability to understand and generate human-like text. However, these models are prone to ``hallucinations'' -- outputs that do not align with factual reality or the input context. This paper introduces the Hallucinations Leaderboard, an open initiative to quantitatively measure and compare the tendency of each model to produce hallucinations. The leaderboard uses a comprehensive set of benchmarks focusing on different aspects of hallucinations, such as factuality and faithfulness, across various tasks, including question-answering, summarisation, and reading comprehension. Our analysis provides insights into the performance of different models, guiding researchers and practitioners in choosing the most reliable models for their applications.