 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVortex: Efficient and Programmable Sparse Attention Serving for AI Agents
Jun 04, 2026Sparse attention is becoming increasingly important for serving large language models (LLMs) as generation lengths continue to grow. However, deploying and evaluating new sparse attention algorithms at scale remains highly engineering-intensive, slowing both human researchers and AI agents in exploring the sparse attention design. To address this challenge, we present Vortex, a system that combines a Python-embedded frontend language atop a page-centric tensor abstraction for expressing a broad range of sparse attention algorithms, with an efficient backend tightly integrated into modern LLM serving stacks. Vortex enables rapid prototyping, deployment, and evaluation of sparse attention algorithms, effectively translating their theoretical efficiency gains into real-world throughput improvements. As a result, Vortex substantially accelerates the design and iteration of sparse attention algorithms. First, AI agents use Vortex to automatically generate and refine diverse algorithms, the best reaching up to $3.46\times$ higher throughput than full attention while preserving accuracy. Second, Vortex extends sparse attention to emerging architectures and very large models that are otherwise hard to experiment with, reaching up to $4.7\times$ higher throughput on the MLA-based GLM-4.7-Flash and $1.37\times$ on the 229B-parameter MiniMax-M2.7 on NVIDIA B200 GPUs.
FastKernels: Benchmarking GPU Kernel Generation in Production
May 22, 2026LLM-based agents for GPU kernel generation are advancing rapidly, yet their progress is fundamentally constrained by the benchmarks they optimize against. Existing benchmarks are poorly aligned with production inference frameworks: they evaluate kernels on a single GPU with synthetic inputs, ignore the surrounding compilation stack, and reward replicating known optimizations rather than discovering new ones. The resulting reward signals are misleading: agents learn to generate kernels that score well in sandboxes but introduce interface incompatibilities, compilation-stack conflicts, and silent correctness degradation when integrated into real systems. We introduce FastKernels, a kernel benchmark built around a minimal set of 46 representative architectures spanning 8 categories, whose kernels collectively subsume those of 96.2% (409/425) of HuggingFace Transformers architectures. FastKernels doubles as a minimalistic, production-grade inference framework that runs at parity with hardened systems such as vLLM and SGLang on mainstream LLM serving and substantially exceeds upstream references on under-served architectures; each task's interface mirrors the corresponding module in the state-of-the-art library for its architecture family, enabling direct deployment of optimized kernels into production codebases. Evaluating state-of-the-art kernel agents on FastKernels, we find that even the strongest agent achieves only 0.94$\times$ aggregate speedup over production baselines, with weaker agents at $0.78\times$ and $0.53\times$ -- confirming that benchmark-production misalignment is a critical bottleneck for the field. We release FastKernels as a stepping stone toward kernel agents whose benchmark gains translate directly into production throughput improvements. Code is available at https://github.com/Snowflake-AI-Research/fastkernels
Coral: Cost-Efficient Multi-LLM Serving over Heterogeneous Cloud GPUs
May 05, 2026The usage of large language models (LLMs) has grown increasingly fragmented, with no single model dominating. Meanwhile, cloud providers offer a wide range of mid-tier and older-generation GPUs that enjoy better availability and deliver comparable performance per dollar to top-tier hardware. To efficiently harness these heterogeneous resources for serving multiple LLMs concurrently, we introduce Coral, an adaptive heterogeneity-aware multi-LLM serving system. The key idea behind Coral is to jointly optimize resource allocation and the serving strategy of each model replica across all models. To keep pace with shifting throughput demand and resource availability, Coral applies a lossless two-stage decomposition that preserves joint optimality while cutting online solve time from hours to tens of seconds. Our evaluation across 6 models and 20 GPU configurations shows that Coral reduces serving cost by up to 2.79$\times$ over the best baseline, and delivers up to 2.39$\times$ higher goodput under scarce resource availability.
DLink: Distilling Layer-wise and Dominant Knowledge from EEG Foundation Models
Apr 16, 2026EEG foundation models (FMs) achieve strong cross-subject and cross-task generalization but impose substantial computational and memory costs that hinder deployment on embedded BCI systems. Knowledge distillation is a natural solution; however, conventional methods fail for EEG FMs because task-relevant semantics are often distributed across intermediate layers, and aggressive dimensionality reduction can distort oscillatory structure via representational collapse and aliasing. To address these challenges, we propose DLink (Distilling Layer-wise and Dominant Knowledge), a unified framework for transferring knowledge from large EEG FMs to compact students with three key innovations: (1) a dynamic Router that adaptively aggregates teacher layers to capture dominant intermediate representations; (2) an EEG MiC student with a Mimic-then-Compress pipeline, which inherits high-dimensional teacher features and then applies structured spatio-temporal compression to avoid a heavy classification head; and (3) spectral distillation that aligns teacher-student representations in the frequency domain to regularize compression and mitigate aliasing and temporal jitter. Experiments on four EEG benchmarks show that DLink enables compact students to outperform lightweight baselines while approaching fully fine-tuned FM performance at substantially lower model size and inference cost.
Prism: Symbolic Superoptimization of Tensor Programs
Apr 16, 2026This paper presents Prism, the first symbolic superoptimizer for tensor programs. The key idea is sGraph, a symbolic, hierarchical representation that compactly encodes large classes of tensor programs by symbolically representing some execution parameters. Prism organizes optimization as a two-level search: it constructs symbolic graphs that represent families of programs, and then instantiates them into concrete implementations. This formulation enables structured pruning of provably suboptimal regions of the search space using symbolic reasoning over operator semantics, algebraic identities, and hardware constraints. We develop techniques for efficient symbolic graph generation, equivalence verification via e-graph rewriting, and parameter instantiation through auto-tuning. Together, these components allow Prism to bridge the rigor of exhaustive search with the scalability required for modern ML workloads. Evaluation on five commonly used LLM workloads shows that Prism achieves up to $2.2\times$ speedup over best superoptimizers and $4.9\times$ over best compiler-based approaches, while reducing end-to-end optimization time by up to $3.4\times$.
Event Tensor: A Unified Abstraction for Compiling Dynamic Megakernel
Apr 14, 2026Modern GPU workloads, especially large language model (LLM) inference, suffer from kernel launch overheads and coarse synchronization that limit inter-kernel parallelism. Recent megakernel techniques fuse multiple operators into a single persistent kernel to eliminate launch gaps and expose inter-kernel parallelism, but struggle to handle dynamic shapes and data-dependent computation in real workloads. We present Event Tensor, a unified compiler abstraction for dynamic megakernels. Event Tensor encodes dependencies between tiled tasks, and enables first-class support for both shape and data-dependent dynamism. Built atop this abstraction, our Event Tensor Compiler (ETC) applies static and dynamic scheduling transformations to generate high-performance persistent kernels. Evaluations show that ETC achieves state-of-the-art LLM serving latency while significantly reducing system warmup overhead.
Mirage Persistent Kernel: A Compiler and Runtime for Mega-Kernelizing Tensor Programs
Dec 22, 2025We introduce Mirage Persistent Kernel (MPK), the first compiler and runtime system that automatically transforms multi-GPU model inference into a single high-performance megakernel. MPK introduces an SM-level graph representation that captures data dependencies at the granularity of individual streaming multiprocessors (SMs), enabling cross-operator software pipelining, fine-grained kernel overlap, and other previously infeasible GPU optimizations. The MPK compiler lowers tensor programs into highly optimized SM-level task graphs and generates optimized CUDA implementations for all tasks, while the MPK in-kernel parallel runtime executes these tasks within a single mega-kernel using decentralized scheduling across SMs. Together, these components provide end-to-end kernel fusion with minimal developer effort, while preserving the flexibility of existing programming models. Our evaluation shows that MPK significantly outperforms existing kernel-per-operator LLM serving systems by reducing end-to-end inference latency by up to 1.7x, pushing LLM inference performance close to hardware limits. MPK is publicly available at https://github.com/mirage-project/mirage.
Less Is More: Training-Free Sparse Attention with Global Locality for Efficient Reasoning
Aug 09, 2025Large reasoning models achieve strong performance through test-time scaling but incur substantial computational overhead, particularly from excessive token generation when processing short input prompts. While sparse attention mechanisms can reduce latency and memory usage, existing approaches suffer from significant accuracy degradation due to accumulated errors during long-generation reasoning. These methods generally require either high token retention rates or expensive retraining. We introduce LessIsMore, a training-free sparse attention mechanism for reasoning tasks, which leverages global attention patterns rather than relying on traditional head-specific local optimizations. LessIsMore aggregates token selections from local attention heads with recent contextual information, enabling unified cross-head token ranking for future decoding layers. This unified selection improves generalization and efficiency by avoiding the need to maintain separate token subsets per head. Evaluation across diverse reasoning tasks and benchmarks shows that LessIsMore preserves -- and in some cases improves -- accuracy while achieving a $1.1\times$ average decoding speed-up compared to full attention. Moreover, LessIsMore attends to $2\times$ fewer tokens without accuracy loss, achieving a $1.13\times$ end-to-end speed-up compared to existing sparse attention methods.
Nexus: Taming Throughput-Latency Tradeoff in LLM Serving via Efficient GPU Sharing
Jul 09, 2025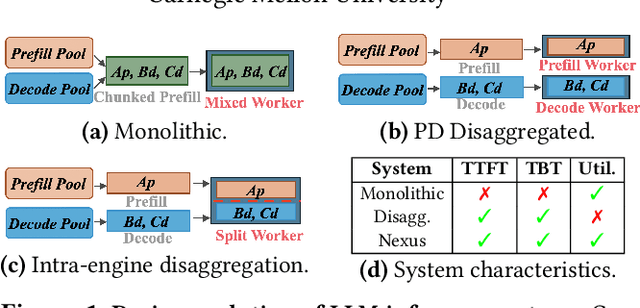
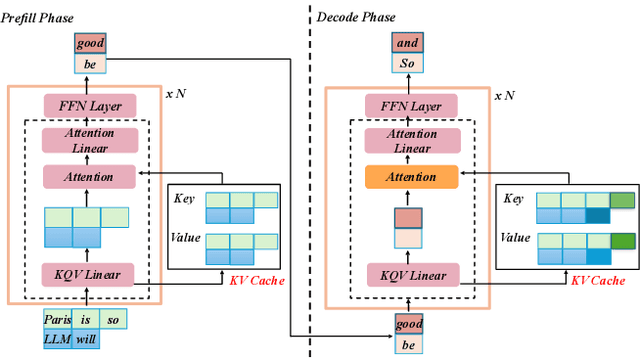
Current prefill-decode (PD) disaggregation is typically deployed at the level of entire serving engines, assigning separate GPUs to handle prefill and decode phases. While effective at reducing latency, this approach demands more hardware. To improve GPU utilization, Chunked Prefill mixes prefill and decode requests within the same batch, but introduces phase interference between prefill and decode. While existing PD disaggregation solutions separate the phases across GPUs, we ask: can the same decoupling be achieved within a single serving engine? The key challenge lies in managing the conflicting resource requirements of prefill and decode when they share the same hardware. In this paper, we first show that chunked prefill requests cause interference with decode requests due to their distinct requirements for GPU resources. Second, we find that GPU resources exhibit diminishing returns. Beyond a saturation point, increasing GPU allocation yields negligible latency improvements. This insight enables us to split a single GPU's resources and dynamically allocate them to prefill and decode on the fly, effectively disaggregating the two phases within the same GPU. Across a range of models and workloads, our system Nexus achieves up to 2.2x higher throughput, 20x lower TTFT, and 2.5x lower TBT than vLLM. It also outperforms SGLang with up to 2x higher throughput, 2x lower TTFT, and 1.7x lower TBT, and achieves 1.4x higher throughput than vLLM-disaggregation using only half the number of GPUs.
DDO: Dual-Decision Optimization via Multi-Agent Collaboration for LLM-Based Medical Consultation
May 24, 2025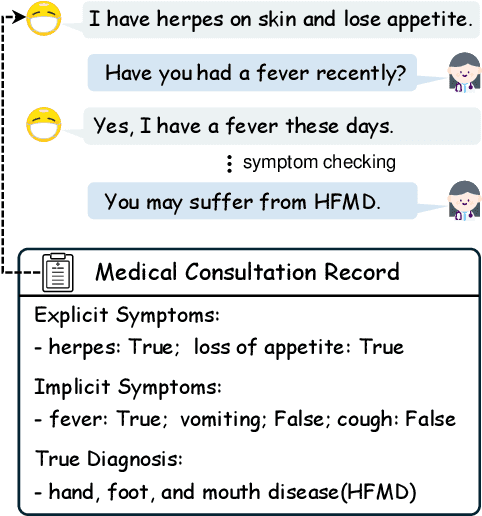
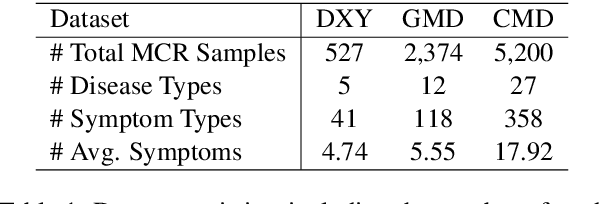
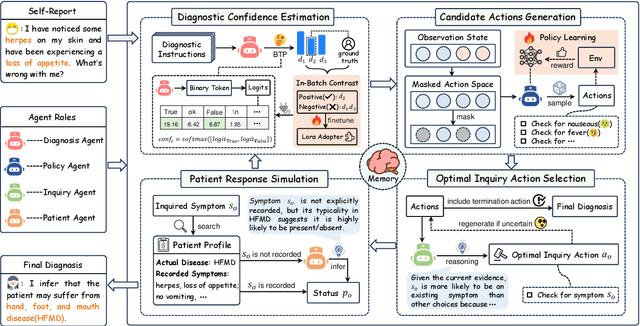
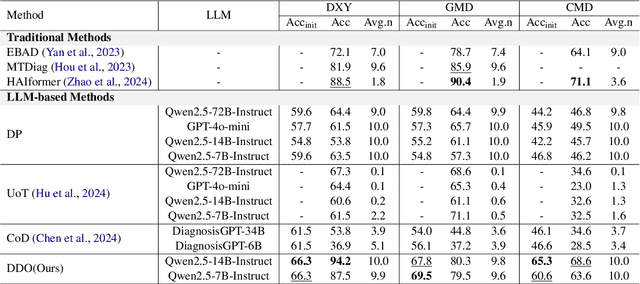
Large Language Models (LLMs) demonstrate strong generalization and reasoning abilities, making them well-suited for complex decision-making tasks such as medical consultation (MC). However, existing LLM-based methods often fail to capture the dual nature of MC, which entails two distinct sub-tasks: symptom inquiry, a sequential decision-making process, and disease diagnosis, a classification problem. This mismatch often results in ineffective symptom inquiry and unreliable disease diagnosis. To address this, we propose \textbf{DDO}, a novel LLM-based framework that performs \textbf{D}ual-\textbf{D}ecision \textbf{O}ptimization by decoupling and independently optimizing the the two sub-tasks through a collaborative multi-agent workflow. Experiments on three real-world MC datasets show that DDO consistently outperforms existing LLM-based approaches and achieves competitive performance with state-of-the-art generation-based methods, demonstrating its effectiveness in the MC task.