 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeRO-Prefill: Zero Redundancy Overheads in MoE Prefill Serving
May 03, 2026Production LLM workloads increasingly serve discriminative tasks, such as classification, recommendation, and verification, whose answers are read from the logits of a single prefill pass with no autoregressive decoding. Serving these prefill-only workloads on mixture-of-experts (MoE) models is bottlenecked not by compute but by the distributed execution required to fit the model: existing parallel strategies (tensor, expert, and pipeline parallelism) trade memory pressure for redundant computation, communication, and synchronization, severely degrading MoE prefill serving efficiency. We observe that these overheads stem from coupling expert placement with synchronous activation routing -- a design inherited from the decoding era. The long, compute-bound forward passes of large-batch prefill open a per-layer window wide enough to stream expert weights in the background, replacing per-layer activation AllToAll with asynchronous weight AllGather fully overlapped with computation. We propose ZeRO-Prefill, a prefill-only serving system whose backend, AsyncEP (Asynchronous Expert Parallelism), gathers experts by weight rather than routing them by activation, and whose frontend co-enforces a physically-derived saturation threshold through prefix-aware routing and true-FLOPs load tracking. On Qwen3-235B-A22B across four hardware/precision configurations, ZeRO-Prefill delivers 1.35-1.37x throughput over the strongest distributed baseline on real-world workloads and up to 1.59x on long-context synthetic workloads, sustaining 29.8-36.2% per-GPU model FLOPs utilization.
Arctic Inference with Shift Parallelism: Fast and Efficient Open Source Inference System for Enterprise AI
Jul 16, 2025Inference is now the dominant AI workload, yet existing systems force trade-offs between latency, throughput, and cost. Arctic Inference, an open-source vLLM plugin from Snowflake AI Research, introduces Shift Parallelism, a dynamic parallelism strategy that adapts to real-world traffic while integrating speculative decoding, SwiftKV compute reduction, and optimized embedding inference. It achieves up to 3.4 times faster request completion, 1.75 times faster generation, and 1.6M tokens/sec per GPU for embeddings, outperforming both latency- and throughput-optimized deployments. Already powering Snowflake Cortex AI, Arctic Inference delivers state-of-the-art, cost-effective inference for enterprise AI and is now available to the community.
Efficiently Serving LLM Reasoning Programs with Certaindex
Dec 30, 2024



The rapid evolution of large language models (LLMs) has unlocked their capabilities in advanced reasoning tasks like mathematical problem-solving, code generation, and legal analysis. Central to this progress are inference-time reasoning algorithms, which refine outputs by exploring multiple solution paths, at the cost of increasing compute demands and response latencies. Existing serving systems fail to adapt to the scaling behaviors of these algorithms or the varying difficulty of queries, leading to inefficient resource use and unmet latency targets. We present Dynasor, a system that optimizes inference-time compute for LLM reasoning queries. Unlike traditional engines, Dynasor tracks and schedules requests within reasoning queries and uses Certaindex, a proxy that measures statistical reasoning progress based on model certainty, to guide compute allocation dynamically. Dynasor co-adapts scheduling with reasoning progress: it allocates more compute to hard queries, reduces compute for simpler ones, and terminates unpromising queries early, balancing accuracy, latency, and cost. On diverse datasets and algorithms, Dynasor reduces compute by up to 50% in batch processing and sustaining 3.3x higher query rates or 4.7x tighter latency SLOs in online serving.
SuffixDecoding: A Model-Free Approach to Speeding Up Large Language Model Inference
Nov 07, 2024
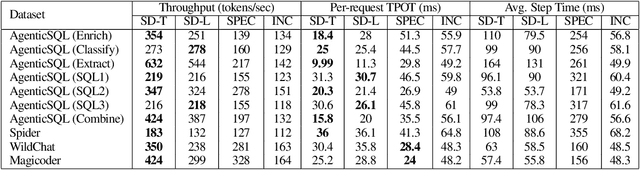


We present SuffixDecoding, a novel model-free approach to accelerating large language model (LLM) inference through speculative decoding. Unlike existing methods that rely on draft models or specialized decoding heads, SuffixDecoding leverages suffix trees built from previously generated outputs to efficiently predict candidate token sequences. Our approach enables flexible tree-structured speculation without the overhead of maintaining and orchestrating additional models. SuffixDecoding builds and dynamically updates suffix trees to capture patterns in the generated text, using them to construct speculation trees through a principled scoring mechanism based on empirical token frequencies. SuffixDecoding requires only CPU memory which is plentiful and underutilized on typical LLM serving nodes. We demonstrate that SuffixDecoding achieves competitive speedups compared to model-based approaches across diverse workloads including open-domain chat, code generation, and text-to-SQL tasks. For open-ended chat and code generation tasks, SuffixDecoding achieves up to $1.4\times$ higher output throughput than SpecInfer and up to $1.1\times$ lower time-per-token (TPOT) latency. For a proprietary multi-LLM text-to-SQL application, SuffixDecoding achieves up to $2.9\times$ higher output throughput and $3\times$ lower latency than speculative decoding. Our evaluation shows that SuffixDecoding maintains high acceptance rates even with small reference corpora of 256 examples, while continuing to improve performance as more historical outputs are incorporated.
SwiftKV: Fast Prefill-Optimized Inference with Knowledge-Preserving Model Transformation
Oct 04, 2024LLM inference for popular enterprise use cases, such as summarization, RAG, and code-generation, typically observes orders of magnitude longer prompt lengths than generation lengths. This characteristic leads to high cost of prefill and increased response latency. In this paper, we present SwiftKV, a novel model transformation and distillation procedure specifically designed to reduce the time and cost of processing prompt tokens while preserving high quality of generated tokens. SwiftKV combines three key mechanisms: i) SingleInputKV, which prefills later layers' KV cache using a much earlier layer's output, allowing prompt tokens to skip much of the model computation, ii) AcrossKV, which merges the KV caches of neighboring layers to reduce the memory footprint and support larger batch size for higher throughput, and iii) a knowledge-preserving distillation procedure that can adapt existing LLMs for SwiftKV with minimal accuracy impact and low compute and data requirement. For Llama-3.1-8B and 70B, SwiftKV reduces the compute requirement of prefill by 50% and the memory requirement of the KV cache by 62.5% while incurring minimum quality degradation across a wide range of tasks. In the end-to-end inference serving using an optimized vLLM implementation, SwiftKV realizes up to 2x higher aggregate throughput and 60% lower time per output token. It can achieve a staggering 560 TFlops/GPU of normalized inference throughput, which translates to 16K tokens/s for Llama-3.1-70B in 16-bit precision on 4x H100 GPUs.
STUN: Structured-Then-Unstructured Pruning for Scalable MoE Pruning
Sep 10, 2024



Mixture-of-experts (MoEs) have been adopted for reducing inference costs by sparsely activating experts in Large language models (LLMs). Despite this reduction, the massive number of experts in MoEs still makes them expensive to serve. In this paper, we study how to address this, by pruning MoEs. Among pruning methodologies, unstructured pruning has been known to achieve the highest performance for a given pruning ratio, compared to structured pruning, since the latter imposes constraints on the sparsification structure. This is intuitive, as the solution space of unstructured pruning subsumes that of structured pruning. However, our counterintuitive finding reveals that expert pruning, a form of structured pruning, can actually precede unstructured pruning to outperform unstructured-only pruning. As existing expert pruning, requiring $O(\frac{k^n}{\sqrt{n}})$ forward passes for $n$ experts, cannot scale for recent MoEs, we propose a scalable alternative with $O(1)$ complexity, yet outperforming the more expensive methods. The key idea is leveraging a latent structure between experts, based on behavior similarity, such that the greedy decision of whether to prune closely captures the joint pruning effect. Ours is highly effective -- for Snowflake Arctic, a 480B-sized MoE with 128 experts, our method needs only one H100 and two hours to achieve nearly no loss in performance with 40% sparsity, even in generative tasks such as GSM8K, where state-of-the-art unstructured pruning fails to. The code will be made publicly available.
Efficient LLM Scheduling by Learning to Rank
Aug 28, 2024

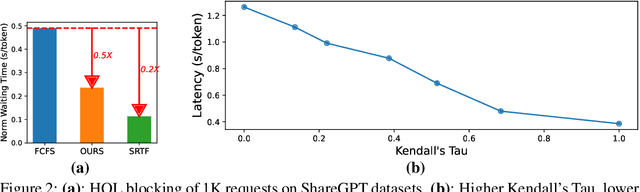

In Large Language Model (LLM) inference, the output length of an LLM request is typically regarded as not known a priori. Consequently, most LLM serving systems employ a simple First-come-first-serve (FCFS) scheduling strategy, leading to Head-Of-Line (HOL) blocking and reduced throughput and service quality. In this paper, we reexamine this assumption -- we show that, although predicting the exact generation length of each request is infeasible, it is possible to predict the relative ranks of output lengths in a batch of requests, using learning to rank. The ranking information offers valuable guidance for scheduling requests. Building on this insight, we develop a novel scheduler for LLM inference and serving that can approximate the shortest-job-first (SJF) schedule better than existing approaches. We integrate this scheduler with the state-of-the-art LLM serving system and show significant performance improvement in several important applications: 2.8x lower latency in chatbot serving and 6.5x higher throughput in synthetic data generation. Our code is available at https://github.com/hao-ai-lab/vllm-ltr.git
LLM360: Towards Fully Transparent Open-Source LLMs
Dec 11, 2023



The recent surge in open-source Large Language Models (LLMs), such as LLaMA, Falcon, and Mistral, provides diverse options for AI practitioners and researchers. However, most LLMs have only released partial artifacts, such as the final model weights or inference code, and technical reports increasingly limit their scope to high-level design choices and surface statistics. These choices hinder progress in the field by degrading transparency into the training of LLMs and forcing teams to rediscover many details in the training process. We present LLM360, an initiative to fully open-source LLMs, which advocates for all training code and data, model checkpoints, and intermediate results to be made available to the community. The goal of LLM360 is to support open and collaborative AI research by making the end-to-end LLM training process transparent and reproducible by everyone. As a first step of LLM360, we release two 7B parameter LLMs pre-trained from scratch, Amber and CrystalCoder, including their training code, data, intermediate checkpoints, and analyses (at https://www.llm360.ai). We are committed to continually pushing the boundaries of LLMs through this open-source effort. More large-scale and stronger models are underway and will be released in the future.
Pollux: Co-adaptive Cluster Scheduling for Goodput-Optimized Deep Learning
Aug 27, 2020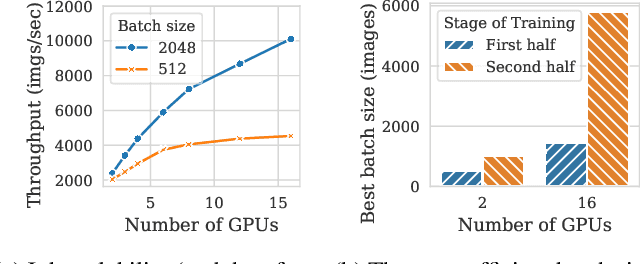

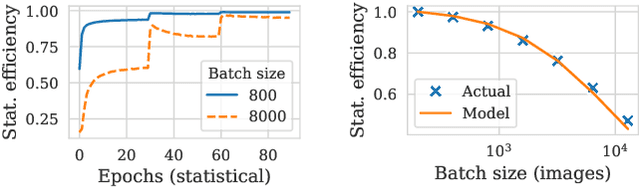
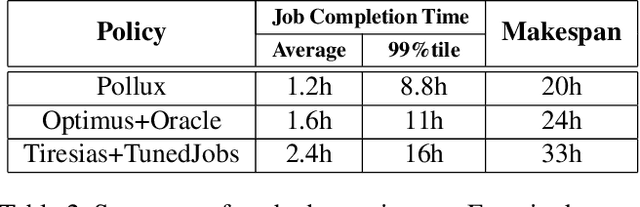
Pollux improves scheduling performance in deep learning (DL) clusters by adaptively co-optimizing inter-dependent factors both at the per-job level and at the cluster-wide level. Most existing schedulers will assign each job a number of resources requested by the user, which can allow jobs to use those resources inefficiently. Some recent schedulers choose job resources for users, but do so without awareness of how DL training can be re-optimized to better utilize those resources. Pollux simultaneously considers both aspects. By observing each job during training, Pollux models how their goodput (system throughput combined with statistical efficiency) would change by adding or removing resources. Leveraging these models, Pollux dynamically (re-)assigns resources to maximize cluster-wide goodput, while continually optimizing each DL job to better utilize those resources. In experiments with real DL training jobs and with trace-driven simulations, Pollux reduces average job completion time by 25%-50% relative to state-of-the-art DL schedulers, even when all jobs are submitted with ideal resource and training configurations. Based on the observation that the statistical efficiency of DL training can change over time, we also show that Pollux can reduce the cost of training large models in cloud environments by 25%.
Fault Tolerance in Iterative-Convergent Machine Learning
Oct 17, 2018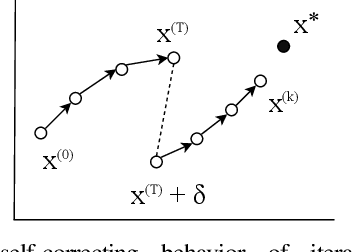
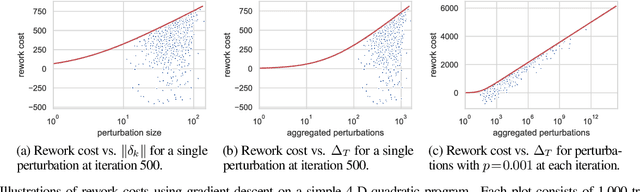
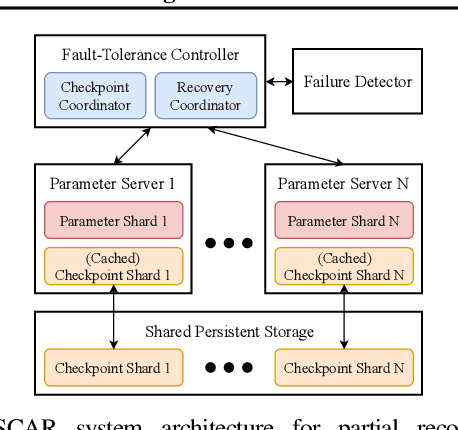
Machine learning (ML) training algorithms often possess an inherent self-correcting behavior due to their iterative-convergent nature. Recent systems exploit this property to achieve adaptability and efficiency in unreliable computing environments by relaxing the consistency of execution and allowing calculation errors to be self-corrected during training. However, the behavior of such systems are only well understood for specific types of calculation errors, such as those caused by staleness, reduced precision, or asynchronicity, and for specific types of training algorithms, such as stochastic gradient descent. In this paper, we develop a general framework to quantify the effects of calculation errors on iterative-convergent algorithms and use this framework to design new strategies for checkpoint-based fault tolerance. Our framework yields a worst-case upper bound on the iteration cost of arbitrary perturbations to model parameters during training. Our system, SCAR, employs strategies which reduce the iteration cost upper bound due to perturbations incurred when recovering from checkpoints. We show that SCAR can reduce the iteration cost of partial failures by 78% - 95% when compared with traditional checkpoint-based fault tolerance across a variety of ML models and training algorithms.