 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Symbolic Adversarial Learning Framework for Evolving Fake News Generation and Detection
Aug 27, 2025Rapid LLM advancements heighten fake news risks by enabling the automatic generation of increasingly sophisticated misinformation. Previous detection methods, including fine-tuned small models or LLM-based detectors, often struggle with its dynamically evolving nature. In this work, we propose a novel framework called the Symbolic Adversarial Learning Framework (SALF), which implements an adversarial training paradigm by an agent symbolic learning optimization process, rather than relying on numerical updates. SALF introduces a paradigm where the generation agent crafts deceptive narratives, and the detection agent uses structured debates to identify logical and factual flaws for detection, and they iteratively refine themselves through such adversarial interactions. Unlike traditional neural updates, we represent agents using agent symbolic learning, where learnable weights are defined by agent prompts, and simulate back-propagation and gradient descent by operating on natural language representations of weights, loss, and gradients. Experiments on two multilingual benchmark datasets demonstrate SALF's effectiveness, showing it generates sophisticated fake news that degrades state-of-the-art detection performance by up to 53.4% in Chinese and 34.2% in English on average. SALF also refines detectors, improving detection of refined content by up to 7.7%. We hope our work inspires further exploration into more robust, adaptable fake news detection systems.
Learning in Chaos: Efficient Autoscaling and Self-healing for Distributed Training at the Edge
May 19, 2025Frequent node and link changes in edge AI clusters disrupt distributed training, while traditional checkpoint-based recovery and cloud-centric autoscaling are too slow for scale-out and ill-suited to chaotic and self-governed edge. This paper proposes Chaos, a resilient and scalable edge distributed training system with built-in self-healing and autoscaling. It speeds up scale-out by using multi-neighbor replication with fast shard scheduling, allowing a new node to pull the latest training state from nearby neighbors in parallel while balancing the traffic load between them. It also uses a cluster monitor to track resource and topology changes to assist scheduler decisions, and handles scaling events through peer negotiation protocols, enabling fully self-governed autoscaling without a central admin. Extensive experiments show that Chaos consistently achieves much lower scale-out delays than Pollux, EDL, and Autoscaling, and handles scale-in, connect-link, and disconnect-link events within 1 millisecond, making it smoother to handle node joins, exits, and failures. It also delivers the lowest idle time, showing superior resource use and scalability as the cluster grows.
Token Level Routing Inference System for Edge Devices
Apr 10, 2025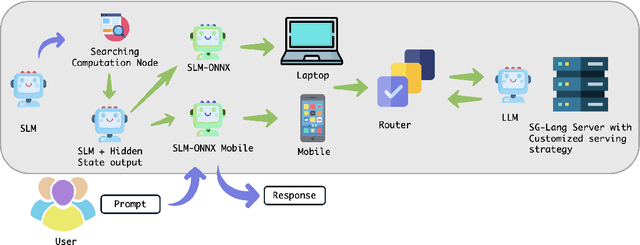
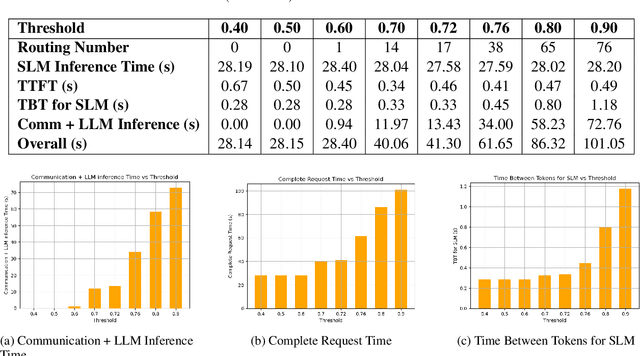
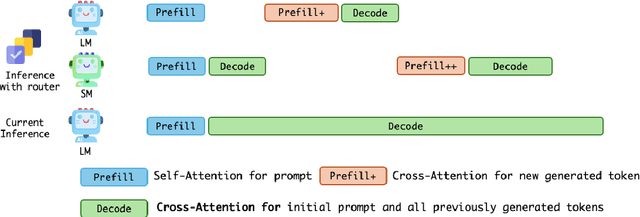
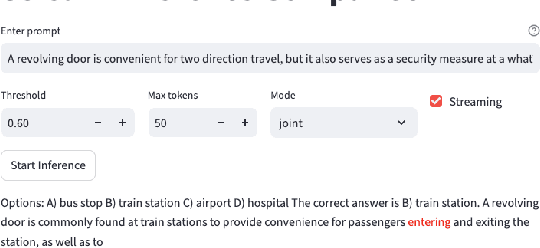
The computational complexity of large language model (LLM) inference significantly constrains their deployment efficiency on edge devices. In contrast, small language models offer faster decoding and lower resource consumption but often suffer from degraded response quality and heightened susceptibility to hallucinations. To address this trade-off, collaborative decoding, in which a large model assists in generating critical tokens, has emerged as a promising solution. This paradigm leverages the strengths of both model types by enabling high-quality inference through selective intervention of the large model, while maintaining the speed and efficiency of the smaller model. In this work, we present a novel collaborative decoding inference system that allows small models to perform on-device inference while selectively consulting a cloud-based large model for critical token generation. Remarkably, the system achieves a 60% performance gain on CommonsenseQA using only a 0.5B model on an M1 MacBook, with under 7% of tokens generation uploaded to the large model in the cloud.
Hawkeye:Efficient Reasoning with Model Collaboration
Apr 01, 2025Chain-of-Thought (CoT) reasoning has demonstrated remarkable effectiveness in enhancing the reasoning abilities of large language models (LLMs). However, its efficiency remains a challenge due to the generation of excessive intermediate reasoning tokens, which introduce semantic redundancy and overly detailed reasoning steps. Moreover, computational expense and latency are significant concerns, as the cost scales with the number of output tokens, including those intermediate steps. In this work, we observe that most CoT tokens are unnecessary, and retaining only a small portion of them is sufficient for producing high-quality responses. Inspired by this, we propose HAWKEYE, a novel post-training and inference framework where a large model produces concise CoT instructions to guide a smaller model in response generation. HAWKEYE quantifies redundancy in CoT reasoning and distills high-density information via reinforcement learning. By leveraging these concise CoTs, HAWKEYE is able to expand responses while reducing token usage and computational cost significantly. Our evaluation shows that HAWKEYE can achieve comparable response quality using only 35% of the full CoTs, while improving clarity, coherence, and conciseness by approximately 10%. Furthermore, HAWKEYE can accelerate end-to-end reasoning by up to 3.4x on complex math tasks while reducing inference cost by up to 60%. HAWKEYE will be open-sourced and the models will be available soon.
J-Invariant Volume Shuffle for Self-Supervised Cryo-Electron Tomogram Denoising on Single Noisy Volume
Nov 22, 2024
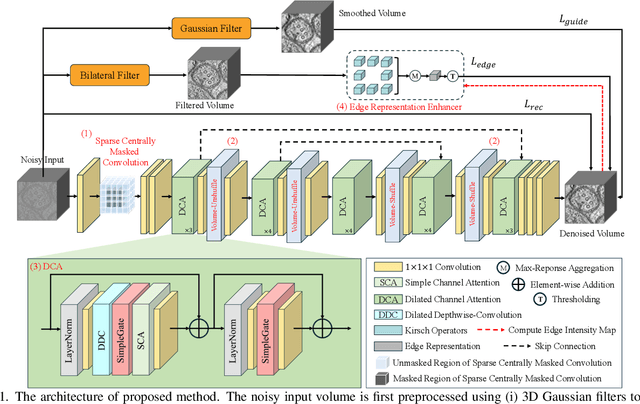


Cryo-Electron Tomography (Cryo-ET) enables detailed 3D visualization of cellular structures in near-native states but suffers from low signal-to-noise ratio due to imaging constraints. Traditional denoising methods and supervised learning approaches often struggle with complex noise patterns and the lack of paired datasets. Self-supervised methods, which utilize noisy input itself as a target, have been studied; however, existing Cryo-ET self-supervised denoising methods face significant challenges due to losing information during training and the learned incomplete noise patterns. In this paper, we propose a novel self-supervised learning model that denoises Cryo-ET volumetric images using a single noisy volume. Our method features a U-shape J-invariant blind spot network with sparse centrally masked convolutions, dilated channel attention blocks, and volume unshuffle/shuffle technique. The volume-unshuffle/shuffle technique expands receptive fields and utilizes multi-scale representations, significantly improving noise reduction and structural preservation. Experimental results demonstrate that our approach achieves superior performance compared to existing methods, advancing Cryo-ET data processing for structural biology research
FIAS: Feature Imbalance-Aware Medical Image Segmentation with Dynamic Fusion and Mixing Attention
Nov 16, 2024
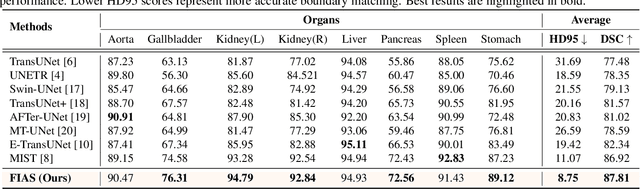

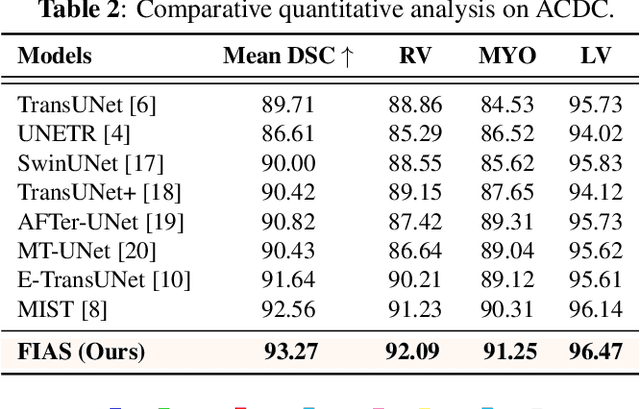
With the growing application of transformer in computer vision, hybrid architecture that combine convolutional neural networks (CNNs) and transformers demonstrates competitive ability in medical image segmentation. However, direct fusion of features from CNNs and transformers often leads to feature imbalance and redundant information. To address these issues, we propose a Feaure Imbalance-Aware Segmentation (FIAS) network, which incorporates a dual-path encoder and a novel Mixing Attention (MixAtt) decoder. The dual-branches encoder integrates a DilateFormer for long-range global feature extraction and a Depthwise Multi-Kernel (DMK) convolution for capturing fine-grained local details. A Context-Aware Fusion (CAF) block dynamically balances the contribution of these global and local features, preventing feature imbalance. The MixAtt decoder further enhances segmentation accuracy by combining self-attention and Monte Carlo attention, enabling the model to capture both small details and large-scale dependencies. Experimental results on the Synapse multi-organ and ACDC datasets demonstrate the strong competitiveness of our approach in medical image segmentation tasks.
Reducing Hyperparameter Tuning Costs in ML, Vision and Language Model Training Pipelines via Memoization-Awareness
Nov 06, 2024



The training or fine-tuning of machine learning, vision, and language models is often implemented as a pipeline: a sequence of stages encompassing data preparation, model training and evaluation. In this paper, we exploit pipeline structures to reduce the cost of hyperparameter tuning for model training/fine-tuning, which is particularly valuable for language models given their high costs in GPU-days. We propose a "memoization-aware" Bayesian Optimization (BO) algorithm, EEIPU, that works in tandem with a pipeline caching system, allowing it to evaluate significantly more hyperparameter candidates per GPU-day than other tuning algorithms. The result is better-quality hyperparameters in the same amount of search time, or equivalently, reduced search time to reach the same hyperparameter quality. In our benchmarks on machine learning (model ensembles), vision (convolutional architecture) and language (T5 architecture) pipelines, we compare EEIPU against recent BO algorithms: EEIPU produces an average of $103\%$ more hyperparameter candidates (within the same budget), and increases the validation metric by an average of $108\%$ more than other algorithms (where the increase is measured starting from the end of warm-up iterations).
Continual Learning of Nonlinear Independent Representations
Aug 11, 2024
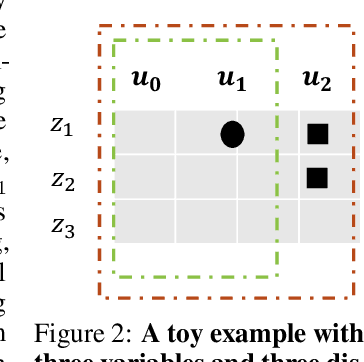
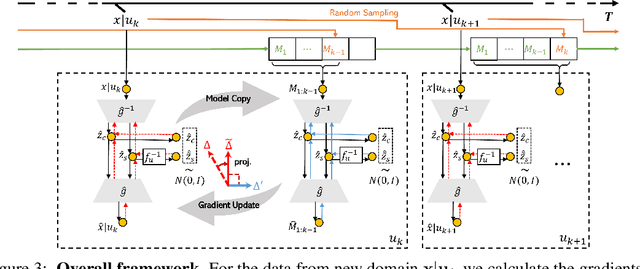
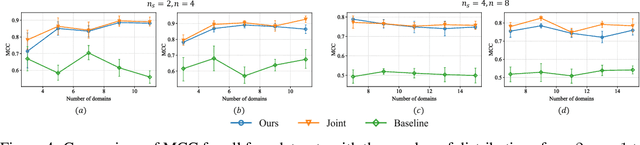
Identifying the causal relations between interested variables plays a pivotal role in representation learning as it provides deep insights into the dataset. Identifiability, as the central theme of this approach, normally hinges on leveraging data from multiple distributions (intervention, distribution shift, time series, etc.). Despite the exciting development in this field, a practical but often overlooked problem is: what if those distribution shifts happen sequentially? In contrast, any intelligence possesses the capacity to abstract and refine learned knowledge sequentially -- lifelong learning. In this paper, with a particular focus on the nonlinear independent component analysis (ICA) framework, we move one step forward toward the question of enabling models to learn meaningful (identifiable) representations in a sequential manner, termed continual causal representation learning. We theoretically demonstrate that model identifiability progresses from a subspace level to a component-wise level as the number of distributions increases. Empirically, we show that our method achieves performance comparable to nonlinear ICA methods trained jointly on multiple offline distributions and, surprisingly, the incoming new distribution does not necessarily benefit the identification of all latent variables.
A Factuality and Diversity Reconciled Decoding Method for Knowledge-Grounded Dialogue Generation
Jul 08, 2024Grounding external knowledge can enhance the factuality of responses in dialogue generation. However, excessive emphasis on it might result in the lack of engaging and diverse expressions. Through the introduction of randomness in sampling, current approaches can increase the diversity. Nevertheless, such sampling method could undermine the factuality in dialogue generation. In this study, to discover a solution for advancing creativity without relying on questionable randomness and to subtly reconcile the factuality and diversity within the source-grounded paradigm, a novel method named DoGe is proposed. DoGe can dynamically alternate between the utilization of internal parameter knowledge and external source knowledge based on the model's factual confidence. Extensive experiments on three widely-used datasets show that DoGe can not only enhance response diversity but also maintain factuality, and it significantly surpasses other various decoding strategy baselines.
Multi-level Adaptive Contrastive Learning for Knowledge Internalization in Dialogue Generation
Oct 17, 2023Knowledge-grounded dialogue generation aims to mitigate the issue of text degeneration by incorporating external knowledge to supplement the context. However, the model often fails to internalize this information into responses in a human-like manner. Instead, it simply inserts segments of the provided knowledge into generic responses. As a result, the generated responses tend to be tedious, incoherent, and in lack of interactivity which means the degeneration problem is still unsolved. In this work, we first find that such copying-style degeneration is primarily due to the weak likelihood objective, which allows the model to "cheat" the objective by merely duplicating knowledge segments in a superficial pattern matching based on overlap. To overcome this challenge, we then propose a Multi-level Adaptive Contrastive Learning (MACL) framework that dynamically samples negative examples and subsequently penalizes degeneration behaviors at both the token-level and sequence-level. Extensive experiments on the WoW dataset demonstrate the effectiveness of our approach across various pre-trained models.