 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSycophancy Hides Linearly in the Attention Heads
Jan 23, 2026We find that correct-to-incorrect sycophancy signals are most linearly separable within multi-head attention activations. Motivated by the linear representation hypothesis, we train linear probes across the residual stream, multilayer perceptron (MLP), and attention layers to analyze where these signals emerge. Although separability appears in the residual stream and MLPs, steering using these probes is most effective in a sparse subset of middle-layer attention heads. Using TruthfulQA as the base dataset, we find that probes trained on it transfer effectively to other factual QA benchmarks. Furthermore, comparing our discovered direction to previously identified "truthful" directions reveals limited overlap, suggesting that factual accuracy, and deference resistance, arise from related but distinct mechanisms. Attention-pattern analysis further indicates that the influential heads attend disproportionately to expressions of user doubt, contributing to sycophantic shifts. Overall, these findings suggest that sycophancy can be mitigated through simple, targeted linear interventions that exploit the internal geometry of attention activations.
Mitigating Watermark Stealing Attacks in Generative Models via Multi-Key Watermarking
Jul 10, 2025Watermarking offers a promising solution for GenAI providers to establish the provenance of their generated content. A watermark is a hidden signal embedded in the generated content, whose presence can later be verified using a secret watermarking key. A threat to GenAI providers are \emph{watermark stealing} attacks, where users forge a watermark into content that was \emph{not} generated by the provider's models without access to the secret key, e.g., to falsely accuse the provider. Stealing attacks collect \emph{harmless} watermarked samples from the provider's model and aim to maximize the expected success rate of generating \emph{harmful} watermarked samples. Our work focuses on mitigating stealing attacks while treating the underlying watermark as a black-box. Our contributions are: (i) Proposing a multi-key extension to mitigate stealing attacks that can be applied post-hoc to any watermarking method across any modality. (ii) We provide theoretical guarantees and demonstrate empirically that our method makes forging substantially less effective across multiple datasets, and (iii) we formally define the threat of watermark forging as the task of generating harmful, watermarked content and model this threat via security games.
Mechanistic Insights into Grokking from the Embedding Layer
May 21, 2025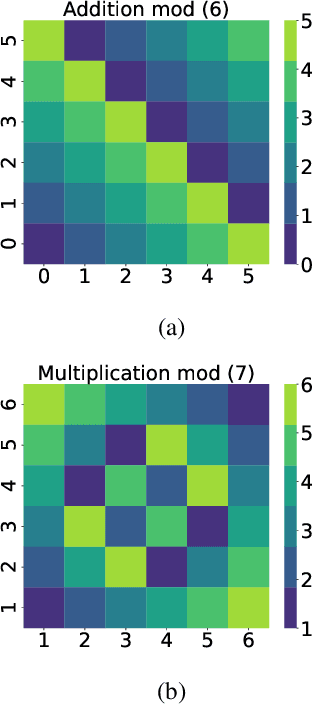
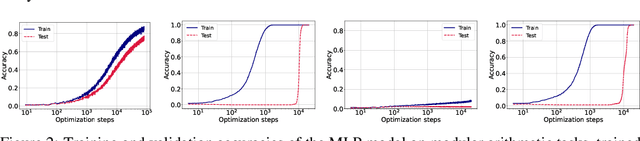
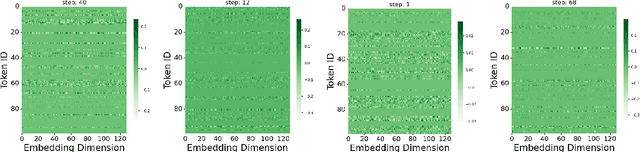
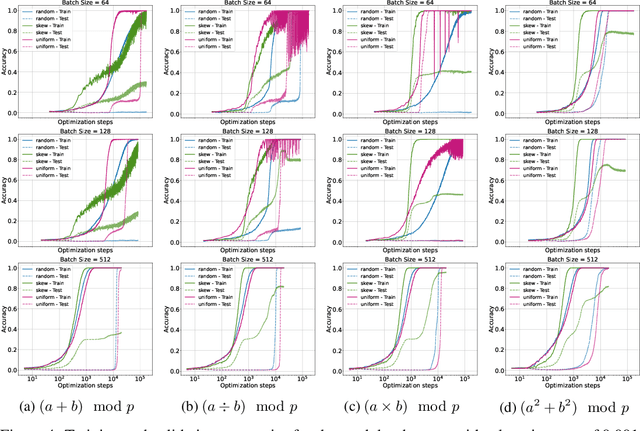
Grokking, a delayed generalization in neural networks after perfect training performance, has been observed in Transformers and MLPs, but the components driving it remain underexplored. We show that embeddings are central to grokking: introducing them into MLPs induces delayed generalization in modular arithmetic tasks, whereas MLPs without embeddings can generalize immediately. Our analysis identifies two key mechanisms: (1) Embedding update dynamics, where rare tokens stagnate due to sparse gradient updates and weight decay, and (2) Bilinear coupling, where the interaction between embeddings and downstream weights introduces saddle points and increases sensitivity to initialization. To confirm these mechanisms, we investigate frequency-aware sampling, which balances token updates by minimizing gradient variance, and embedding-specific learning rates, derived from the asymmetric curvature of the bilinear loss landscape. We prove that an adaptive learning rate ratio, \(\frac{\eta_E}{\eta_W} \propto \frac{\sigma_{\max}(E)}{\sigma_{\max}(W)} \cdot \frac{f_W}{f_E}\), mitigates bilinear coupling effects, accelerating convergence. Our methods not only improve grokking dynamics but also extend to broader challenges in Transformer optimization, where bilinear interactions hinder efficient training.
Number Representations in LLMs: A Computational Parallel to Human Perception
Feb 22, 2025Humans are believed to perceive numbers on a logarithmic mental number line, where smaller values are represented with greater resolution than larger ones. This cognitive bias, supported by neuroscience and behavioral studies, suggests that numerical magnitudes are processed in a sublinear fashion rather than on a uniform linear scale. Inspired by this hypothesis, we investigate whether large language models (LLMs) exhibit a similar logarithmic-like structure in their internal numerical representations. By analyzing how numerical values are encoded across different layers of LLMs, we apply dimensionality reduction techniques such as PCA and PLS followed by geometric regression to uncover latent structures in the learned embeddings. Our findings reveal that the model's numerical representations exhibit sublinear spacing, with distances between values aligning with a logarithmic scale. This suggests that LLMs, much like humans, may encode numbers in a compressed, non-uniform manner.
Reducing Hyperparameter Tuning Costs in ML, Vision and Language Model Training Pipelines via Memoization-Awareness
Nov 06, 2024



The training or fine-tuning of machine learning, vision, and language models is often implemented as a pipeline: a sequence of stages encompassing data preparation, model training and evaluation. In this paper, we exploit pipeline structures to reduce the cost of hyperparameter tuning for model training/fine-tuning, which is particularly valuable for language models given their high costs in GPU-days. We propose a "memoization-aware" Bayesian Optimization (BO) algorithm, EEIPU, that works in tandem with a pipeline caching system, allowing it to evaluate significantly more hyperparameter candidates per GPU-day than other tuning algorithms. The result is better-quality hyperparameters in the same amount of search time, or equivalently, reduced search time to reach the same hyperparameter quality. In our benchmarks on machine learning (model ensembles), vision (convolutional architecture) and language (T5 architecture) pipelines, we compare EEIPU against recent BO algorithms: EEIPU produces an average of $103\%$ more hyperparameter candidates (within the same budget), and increases the validation metric by an average of $108\%$ more than other algorithms (where the increase is measured starting from the end of warm-up iterations).
Improving Personalisation in Valence and Arousal Prediction using Data Augmentation
Apr 13, 2024
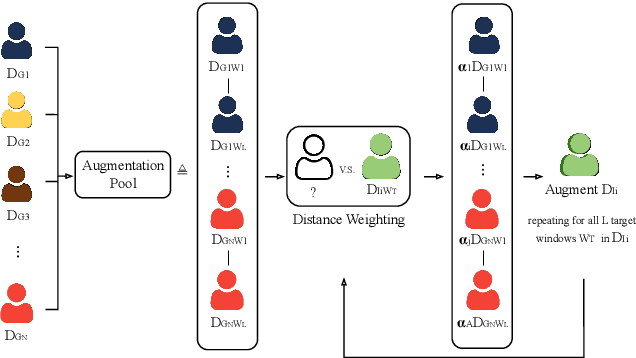

In the field of emotion recognition and Human-Machine Interaction (HMI), personalised approaches have exhibited their efficacy in capturing individual-specific characteristics and enhancing affective prediction accuracy. However, personalisation techniques often face the challenge of limited data for target individuals. This paper presents our work on an enhanced personalisation strategy, that leverages data augmentation to develop tailored models for continuous valence and arousal prediction. Our proposed approach, Distance Weighting Augmentation (DWA), employs a weighting-based augmentation method that expands a target individual's dataset, leveraging distance metrics to identify similar samples at the segment-level. Experimental results on the MuSe-Personalisation 2023 Challenge dataset demonstrate that our method significantly improves the performance of features sets which have low baseline performance, on the test set. This improvement in poor-performing features comes without sacrificing performance on high-performing features. In particular, our method achieves a maximum combined testing CCC of 0.78, compared to the reported baseline score of 0.76 (reproduced at 0.72). It also achieved a peak arousal and valence scores of 0.81 and 0.76, compared to reproduced baseline scores of 0.76 and 0.67 respectively. Through this work, we make significant contributions to the advancement of personalised affective computing models, enhancing the practicality and adaptability of data-level personalisation in real world contexts.
Explainability Matters: Backdoor Attacks on Medical Imaging
Dec 30, 2020



Deep neural networks have been shown to be vulnerable to backdoor attacks, which could be easily introduced to the training set prior to model training. Recent work has focused on investigating backdoor attacks on natural images or toy datasets. Consequently, the exact impact of backdoors is not yet fully understood in complex real-world applications, such as in medical imaging where misdiagnosis can be very costly. In this paper, we explore the impact of backdoor attacks on a multi-label disease classification task using chest radiography, with the assumption that the attacker can manipulate the training dataset to execute the attack. Extensive evaluation of a state-of-the-art architecture demonstrates that by introducing images with few-pixel perturbations into the training set, an attacker can execute the backdoor successfully without having to be involved with the training procedure. A simple 3$\times$3 pixel trigger can achieve up to 1.00 Area Under the Receiver Operating Characteristic (AUROC) curve on the set of infected images. In the set of clean images, the backdoored neural network could still achieve up to 0.85 AUROC, highlighting the stealthiness of the attack. As the use of deep learning based diagnostic systems proliferates in clinical practice, we also show how explainability is indispensable in this context, as it can identify spatially localized backdoors in inference time.