 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtelierEval: Agentic Evaluation of Humans & LLMs as Text-to-Image Prompters
May 21, 2026Text-to-image (T2I) systems increasingly rely on upstream prompters, either humans or multimodal large language models (MLLMs), to translate user intent into detailed prompts. Yet current benchmarks fix the prompt and only evaluate T2I models, leaving the prompting proficiency of this upstream component entirely unmeasured. We introduce AtelierEval, the first unified benchmark that quantifies prompting proficiency across 360 expert-crafted tasks. Grounded in a cognitive view, it spans three task categories and instantiates tasks using a taxonomy of real-world challenges, with a dual interface for both humans and MLLMs. To enable scalable and reliable evaluation, we propose AtelierJudge, a skill-based, memory-augmented agentic evaluator. It produces subjective and objective scores for prompt-image pairs, achieving a Spearman correlation of 0.79 with human experts, approaching human performance. Extensive experiments benchmark 8 MLLMs against 48 human users across 4 T2I backends, validate AtelierEval as a robust diagnostic tool, and reveal the superiority of mimicry over planning, advocating for an image-augmented direction for future prompters. Our work is released to support future research.
The Supportiveness-Safety Tradeoff in LLM Well-Being Agents
Feb 04, 2026Large language models (LLMs) are being integrated into socially assistive robots (SARs) and other conversational agents providing mental health and well-being support. These agents are often designed to sound empathic and supportive in order to maximize user's engagement, yet it remains unclear how increasing the level of supportive framing in system prompts influences safety relevant behavior. We evaluated 6 LLMs across 3 system prompts with varying levels of supportiveness on 80 synthetic queries spanning 4 well-being domains (1440 responses). An LLM judge framework, validated against human ratings, assessed safety and care quality. Moderately supportive prompts improved empathy and constructive support while maintaining safety. In contrast, strongly validating prompts significantly degraded safety and, in some cases, care across all domains, with substantial variation across models. We discuss implications for prompt design, model selection, and domain specific safeguards in SARs deployment.
T2IBias: Uncovering Societal Bias Encoded in the Latent Space of Text-to-Image Generative Models
Nov 15, 2025Text-to-image (T2I) generative models are largely used in AI-powered real-world applications and value creation. However, their strategic deployment raises critical concerns for responsible AI management, particularly regarding the reproduction and amplification of race- and gender-related stereotypes that can undermine organizational ethics. In this work, we investigate whether such societal biases are systematically encoded within the pretrained latent spaces of state-of-the-art T2I models. We conduct an empirical study across the five most popular open-source models, using ten neutral, profession-related prompts to generate 100 images per profession, resulting in a dataset of 5,000 images evaluated by diverse human assessors representing different races and genders. We demonstrate that all five models encode and amplify pronounced societal skew: caregiving and nursing roles are consistently feminized, while high-status professions such as corporate CEO, politician, doctor, and lawyer are overwhelmingly represented by males and mostly White individuals. We further identify model-specific patterns, such as QWEN-Image's near-exclusive focus on East Asian outputs, Kandinsky's dominance of White individuals, and SDXL's comparatively broader but still biased distributions. These results provide critical insights for AI project managers and practitioners, enabling them to select equitable AI models and customized prompts that generate images in alignment with the principles of responsible AI. We conclude by discussing the risks of these biases and proposing actionable strategies for bias mitigation in building responsible GenAI systems. The code and Data Repository: https://github.com/Sufianlab/T2IBias
On the Stability of the Jacobian Matrix in Deep Neural Networks
Jun 10, 2025Deep neural networks are known to suffer from exploding or vanishing gradients as depth increases, a phenomenon closely tied to the spectral behavior of the input-output Jacobian. Prior work has identified critical initialization schemes that ensure Jacobian stability, but these analyses are typically restricted to fully connected networks with i.i.d. weights. In this work, we go significantly beyond these limitations: we establish a general stability theorem for deep neural networks that accommodates sparsity (such as that introduced by pruning) and non-i.i.d., weakly correlated weights (e.g. induced by training). Our results rely on recent advances in random matrix theory, and provide rigorous guarantees for spectral stability in a much broader class of network models. This extends the theoretical foundation for initialization schemes in modern neural networks with structured and dependent randomness.
Decompose-ToM: Enhancing Theory of Mind Reasoning in Large Language Models through Simulation and Task Decomposition
Jan 15, 2025Theory of Mind (ToM) is the ability to understand and reflect on the mental states of others. Although this capability is crucial for human interaction, testing on Large Language Models (LLMs) reveals that they possess only a rudimentary understanding of it. Although the most capable closed-source LLMs have come close to human performance on some ToM tasks, they still perform poorly on complex variations of the task that involve more structured reasoning. In this work, we utilize the concept of "pretend-play", or ``Simulation Theory'' from cognitive psychology to propose ``Decompose-ToM'': an LLM-based inference algorithm that improves model performance on complex ToM tasks. We recursively simulate user perspectives and decompose the ToM task into a simpler set of functions: subject identification, question-reframing, world model updation, and knowledge availability. We test the algorithm on higher-order ToM tasks and a task testing for ToM capabilities in a conversational setting, demonstrating that our approach shows significant improvement across models compared to baseline methods while requiring minimal prompt tuning across tasks and no additional model training.
Improving Personalisation in Valence and Arousal Prediction using Data Augmentation
Apr 13, 2024
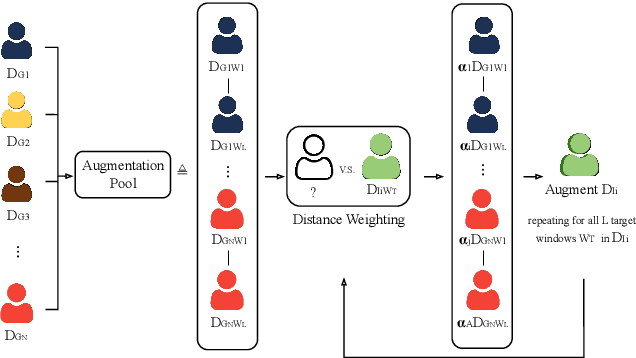

In the field of emotion recognition and Human-Machine Interaction (HMI), personalised approaches have exhibited their efficacy in capturing individual-specific characteristics and enhancing affective prediction accuracy. However, personalisation techniques often face the challenge of limited data for target individuals. This paper presents our work on an enhanced personalisation strategy, that leverages data augmentation to develop tailored models for continuous valence and arousal prediction. Our proposed approach, Distance Weighting Augmentation (DWA), employs a weighting-based augmentation method that expands a target individual's dataset, leveraging distance metrics to identify similar samples at the segment-level. Experimental results on the MuSe-Personalisation 2023 Challenge dataset demonstrate that our method significantly improves the performance of features sets which have low baseline performance, on the test set. This improvement in poor-performing features comes without sacrificing performance on high-performing features. In particular, our method achieves a maximum combined testing CCC of 0.78, compared to the reported baseline score of 0.76 (reproduced at 0.72). It also achieved a peak arousal and valence scores of 0.81 and 0.76, compared to reproduced baseline scores of 0.76 and 0.67 respectively. Through this work, we make significant contributions to the advancement of personalised affective computing models, enhancing the practicality and adaptability of data-level personalisation in real world contexts.
A Survey on Personalized Affective Computing in Human-Machine Interaction
Apr 01, 2023In computing, the aim of personalization is to train a model that caters to a specific individual or group of people by optimizing one or more performance metrics and adhering to specific constraints. In this paper, we discuss the need for personalization in affective and personality computing (hereinafter referred to as affective computing). We present a survey of state-of-the-art approaches for personalization in affective computing. Our review spans training techniques and objectives towards the personalization of affective computing models. We group existing approaches into seven categories: (1) Target-specific Models, (2) Group-specific Models, (3) Weighting-based Approaches, (4) Fine-tuning Approaches, (5) Multitask Learning, (6) Generative-based Models, and (7) Feature Augmentation. Additionally, we provide a statistical meta-analysis of the surveyed literature, analyzing the prevalence of different affective computing tasks, interaction modes, interaction contexts, and the level of personalization among the surveyed works. Based on that, we provide a road-map for those who are interested in exploring this direction.
Automatic Context-Driven Inference of Engagement in HMI: A Survey
Sep 30, 2022
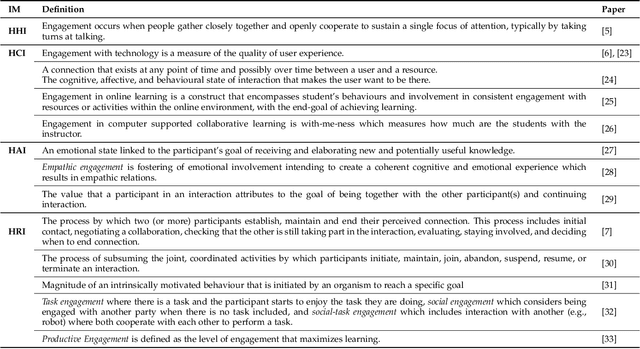
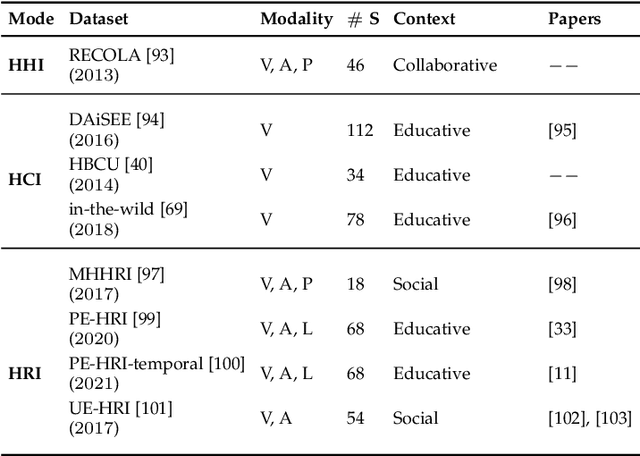
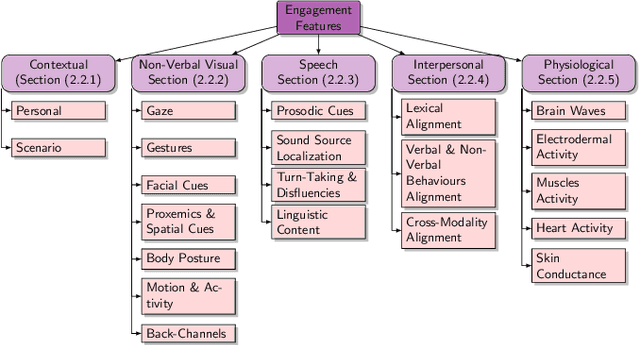
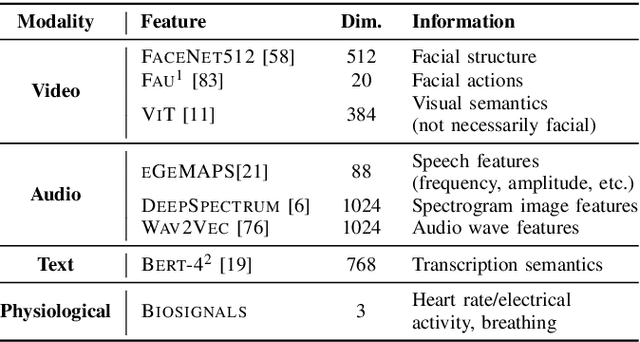
An integral part of seamless human-human communication is engagement, the process by which two or more participants establish, maintain, and end their perceived connection. Therefore, to develop successful human-centered human-machine interaction applications, automatic engagement inference is one of the tasks required to achieve engaging interactions between humans and machines, and to make machines attuned to their users, hence enhancing user satisfaction and technology acceptance. Several factors contribute to engagement state inference, which include the interaction context and interactants' behaviours and identity. Indeed, engagement is a multi-faceted and multi-modal construct that requires high accuracy in the analysis and interpretation of contextual, verbal and non-verbal cues. Thus, the development of an automated and intelligent system that accomplishes this task has been proven to be challenging so far. This paper presents a comprehensive survey on previous work in engagement inference for human-machine interaction, entailing interdisciplinary definition, engagement components and factors, publicly available datasets, ground truth assessment, and most commonly used features and methods, serving as a guide for the development of future human-machine interaction interfaces with reliable context-aware engagement inference capability. An in-depth review across embodied and disembodied interaction modes, and an emphasis on the interaction context of which engagement perception modules are integrated sets apart the presented survey from existing surveys.
Distinguishing Engagement Facets: An Essential Component for AI-based Healthcare
Nov 22, 2021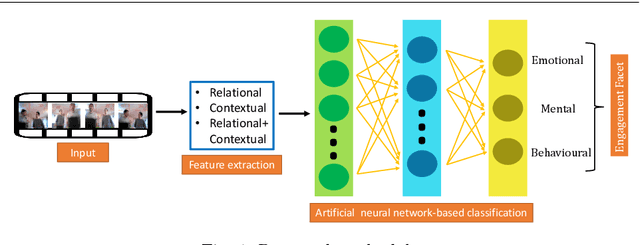

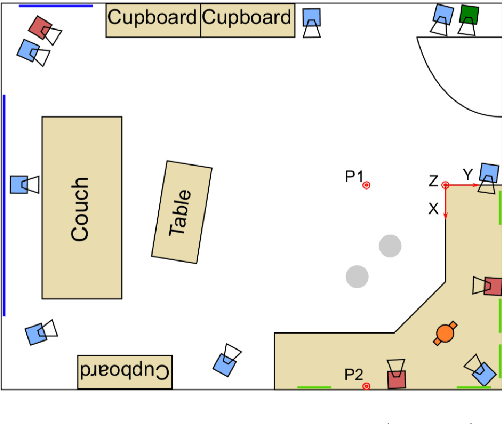
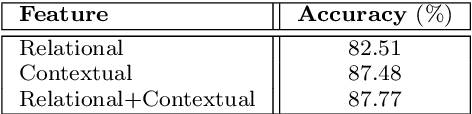
Engagement in Human-Machine Interaction is the process by which entities participating in the interaction establish, maintain, and end their perceived connection. It is essential to monitor the engagement state of patients in various AI-based healthcare paradigms. This includes medical conditions that alter social behavior such as Autism Spectrum Disorder (ASD) or Attention-Deficit/Hyperactivity Disorder (ADHD). Engagement is a multifaceted construct which is composed of behavioral, emotional, and mental components. Previous research has neglected the multi-faceted nature of engagement. In this paper, a system is presented to distinguish these facets using contextual and relational features. This can facilitate further fine-grained analysis. Several machine learning classifiers including traditional and deep learning models are compared for this task. A highest accuracy of 74.57% with an F-Score and mean absolute error of 0.74 and 0.23 respectively was obtained on a balanced dataset of 22242 instances with neural network-based classification.
Deep Multi-Facial Patches Aggregation Network For Facial Expression Recognition
Feb 20, 2020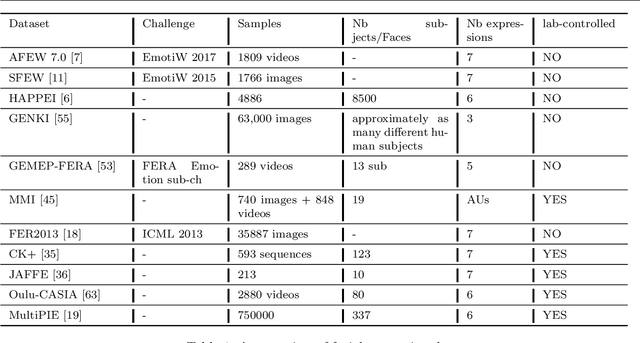
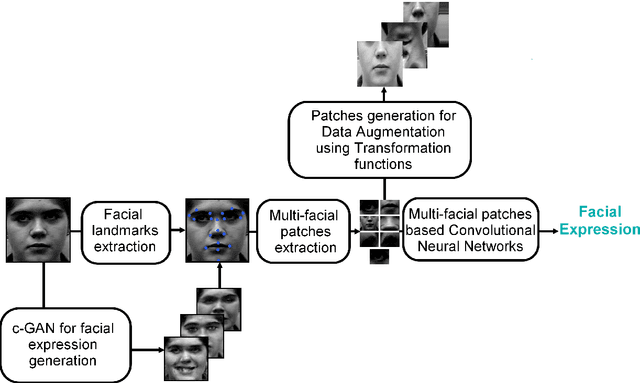
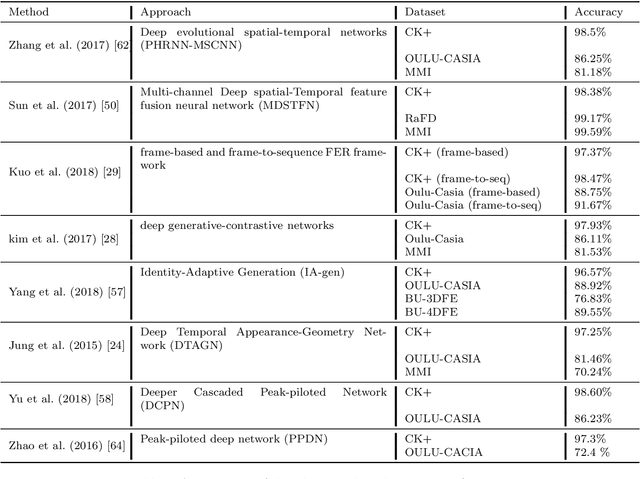
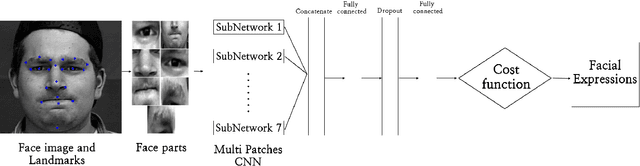
In this paper, we propose an approach for Facial Expressions Recognition (FER) based on a deep multi-facial patches aggregation network. Deep features are learned from facial patches using deep sub-networks and aggregated within one deep architecture for expression classification . Several problems may affect the performance of deep-learning based FER approaches, in particular, the small size of existing FER datasets which might not be sufficient to train large deep learning networks. Moreover, it is extremely time-consuming to collect and annotate a large number of facial images. To account for this, we propose two data augmentation techniques for facial expression generation to expand FER labeled training datasets. We evaluate the proposed framework on three FER datasets. Results show that the proposed approach achieves state-of-art FER deep learning approaches performance when the model is trained and tested on images from the same dataset. Moreover, the proposed data augmentation techniques improve the expression recognition rate, and thus can be a solution for training deep learning FER models using small datasets. The accuracy degrades significantly when testing for dataset bias.