 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalcon-H1R: Pushing the Reasoning Frontiers with a Hybrid Model for Efficient Test-Time Scaling
Jan 05, 2026This work introduces Falcon-H1R, a 7B-parameter reasoning-optimized model that establishes the feasibility of achieving competitive reasoning performance with small language models (SLMs). Falcon-H1R stands out for its parameter efficiency, consistently matching or outperforming SOTA reasoning models that are $2\times$ to $7\times$ larger across a variety of reasoning-intensive benchmarks. These results underscore the importance of careful data curation and targeted training strategies (via both efficient SFT and RL scaling) in delivering significant performance gains without increasing model size. Furthermore, Falcon-H1R advances the 3D limits of reasoning efficiency by combining faster inference (through its hybrid-parallel architecture design), token efficiency, and higher accuracy. This unique blend makes Falcon-H1R-7B a practical backbone for scaling advanced reasoning systems, particularly in scenarios requiring extensive chain-of-thoughts generation and parallel test-time scaling. Leveraging the recently introduced DeepConf approach, Falcon-H1R achieves state-of-the-art test-time scaling efficiency, offering substantial improvements in both accuracy and computational cost. As a result, Falcon-H1R demonstrates that compact models, through targeted model training and architectural choices, can deliver robust and scalable reasoning performance.
Falcon-H1: A Family of Hybrid-Head Language Models Redefining Efficiency and Performance
Jul 30, 2025In this report, we introduce Falcon-H1, a new series of large language models (LLMs) featuring hybrid architecture designs optimized for both high performance and efficiency across diverse use cases. Unlike earlier Falcon models built solely on Transformer or Mamba architectures, Falcon-H1 adopts a parallel hybrid approach that combines Transformer-based attention with State Space Models (SSMs), known for superior long-context memory and computational efficiency. We systematically revisited model design, data strategy, and training dynamics, challenging conventional practices in the field. Falcon-H1 is released in multiple configurations, including base and instruction-tuned variants at 0.5B, 1.5B, 1.5B-deep, 3B, 7B, and 34B parameters. Quantized instruction-tuned models are also available, totaling over 30 checkpoints on Hugging Face Hub. Falcon-H1 models demonstrate state-of-the-art performance and exceptional parameter and training efficiency. The flagship Falcon-H1-34B matches or outperforms models up to 70B scale, such as Qwen3-32B, Qwen2.5-72B, and Llama3.3-70B, while using fewer parameters and less data. Smaller models show similar trends: the Falcon-H1-1.5B-Deep rivals current leading 7B-10B models, and Falcon-H1-0.5B performs comparably to typical 7B models from 2024. These models excel across reasoning, mathematics, multilingual tasks, instruction following, and scientific knowledge. With support for up to 256K context tokens and 18 languages, Falcon-H1 is suitable for a wide range of applications. All models are released under a permissive open-source license, underscoring our commitment to accessible and impactful AI research.
On the Stability of the Jacobian Matrix in Deep Neural Networks
Jun 10, 2025Deep neural networks are known to suffer from exploding or vanishing gradients as depth increases, a phenomenon closely tied to the spectral behavior of the input-output Jacobian. Prior work has identified critical initialization schemes that ensure Jacobian stability, but these analyses are typically restricted to fully connected networks with i.i.d. weights. In this work, we go significantly beyond these limitations: we establish a general stability theorem for deep neural networks that accommodates sparsity (such as that introduced by pruning) and non-i.i.d., weakly correlated weights (e.g. induced by training). Our results rely on recent advances in random matrix theory, and provide rigorous guarantees for spectral stability in a much broader class of network models. This extends the theoretical foundation for initialization schemes in modern neural networks with structured and dependent randomness.
High-Dimensional Analysis of Bootstrap Ensemble Classifiers
May 20, 2025Bootstrap methods have long been a cornerstone of ensemble learning in machine learning. This paper presents a theoretical analysis of bootstrap techniques applied to the Least Square Support Vector Machine (LSSVM) ensemble in the context of large and growing sample sizes and feature dimensionalities. Leveraging tools from Random Matrix Theory, we investigate the performance of this classifier that aggregates decision functions from multiple weak classifiers, each trained on different subsets of the data. We provide insights into the use of bootstrap methods in high-dimensional settings, enhancing our understanding of their impact. Based on these findings, we propose strategies to select the number of subsets and the regularization parameter that maximize the performance of the LSSVM. Empirical experiments on synthetic and real-world datasets validate our theoretical results.
Accurate and Diverse LLM Mathematical Reasoning via Automated PRM-Guided GFlowNets
Apr 28, 2025Achieving both accuracy and diverse reasoning remains challenging for Large Language Models (LLMs) in complex domains like mathematics. A key bottleneck is evaluating intermediate reasoning steps to guide generation without costly human annotations. To address this, we first introduce a novel Process Reward Model (PRM) trained automatically using Monte Carlo Tree Search coupled with a similarity-based data augmentation technique, effectively capturing step-level reasoning quality. Leveraging this PRM, we then adapt Generative Flow Networks (GFlowNets) to operate at the reasoning step level. Unlike traditional reinforcement learning focused on maximizing a single reward, GFlowNets naturally sample diverse, high-quality solutions proportional to their rewards, as measured by our PRM. Empirical evaluation shows strong improvements in both accuracy and solution diversity on challenging mathematical benchmarks (e.g., +2.59% absolute accuracy on MATH Level 5 for Llama3.2-3B), with effective generalization to unseen datasets (+9.4% absolute on SAT MATH). Our work demonstrates the potential of PRM-guided, step-level GFlowNets for developing more robust and versatile mathematical reasoning in LLMs.
Maximizing the Potential of Synthetic Data: Insights from Random Matrix Theory
Oct 11, 2024



Synthetic data has gained attention for training large language models, but poor-quality data can harm performance (see, e.g., Shumailov et al. (2023); Seddik et al. (2024)). A potential solution is data pruning, which retains only high-quality data based on a score function (human or machine feedback). Previous work Feng et al. (2024) analyzed models trained on synthetic data as sample size increases. We extend this by using random matrix theory to derive the performance of a binary classifier trained on a mix of real and pruned synthetic data in a high dimensional setting. Our findings identify conditions where synthetic data could improve performance, focusing on the quality of the generative model and verification strategy. We also show a smooth phase transition in synthetic label noise, contrasting with prior sharp behavior in infinite sample limits. Experiments with toy models and large language models validate our theoretical results.
Alignment with Preference Optimization Is All You Need for LLM Safety
Sep 12, 2024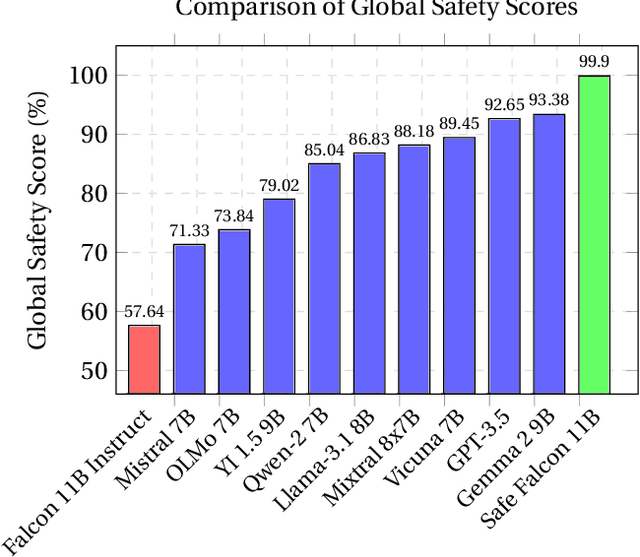
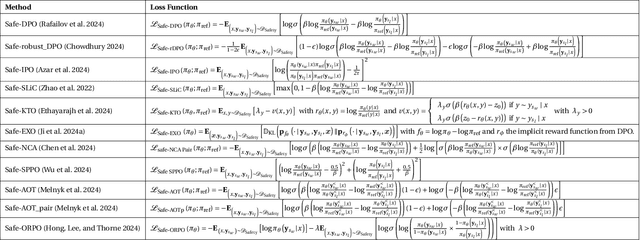
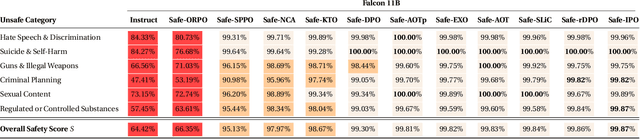

We demonstrate that preference optimization methods can effectively enhance LLM safety. Applying various alignment techniques to the Falcon 11B model using safety datasets, we achieve a significant boost in global safety score (from $57.64\%$ to $99.90\%$) as measured by LlamaGuard 3 8B, competing with state-of-the-art models. On toxicity benchmarks, average scores in adversarial settings dropped from over $0.6$ to less than $0.07$. However, this safety improvement comes at the cost of reduced general capabilities, particularly in math, suggesting a trade-off. We identify noise contrastive alignment (Safe-NCA) as an optimal method for balancing safety and performance. Our study ultimately shows that alignment techniques can be sufficient for building safe and robust models.
Falcon2-11B Technical Report
Jul 20, 2024



We introduce Falcon2-11B, a foundation model trained on over five trillion tokens, and its multimodal counterpart, Falcon2-11B-vlm, which is a vision-to-text model. We report our findings during the training of the Falcon2-11B which follows a multi-stage approach where the early stages are distinguished by their context length and a final stage where we use a curated, high-quality dataset. Additionally, we report the effect of doubling the batch size mid-training and how training loss spikes are affected by the learning rate. The downstream performance of the foundation model is evaluated on established benchmarks, including multilingual and code datasets. The foundation model shows strong generalization across all the tasks which makes it suitable for downstream finetuning use cases. For the vision language model, we report the performance on several benchmarks and show that our model achieves a higher average score compared to open-source models of similar size. The model weights and code of both Falcon2-11B and Falcon2-11B-vlm are made available under a permissive license.
High-dimensional Learning with Noisy Labels
May 23, 2024This paper provides theoretical insights into high-dimensional binary classification with class-conditional noisy labels. Specifically, we study the behavior of a linear classifier with a label noisiness aware loss function, when both the dimension of data $p$ and the sample size $n$ are large and comparable. Relying on random matrix theory by supposing a Gaussian mixture data model, the performance of the linear classifier when $p,n\to \infty$ is shown to converge towards a limit, involving scalar statistics of the data. Importantly, our findings show that the low-dimensional intuitions to handle label noise do not hold in high-dimension, in the sense that the optimal classifier in low-dimension dramatically fails in high-dimension. Based on our derivations, we design an optimized method that is shown to be provably more efficient in handling noisy labels in high dimensions. Our theoretical conclusions are further confirmed by experiments on real datasets, where we show that our optimized approach outperforms the considered baselines.
How Bad is Training on Synthetic Data? A Statistical Analysis of Language Model Collapse
Apr 07, 2024

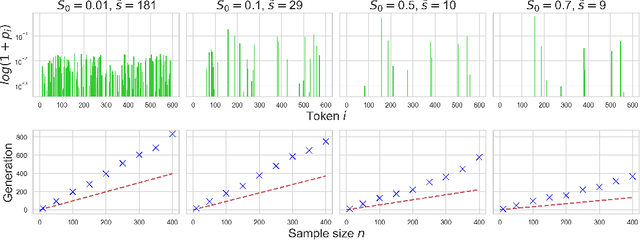
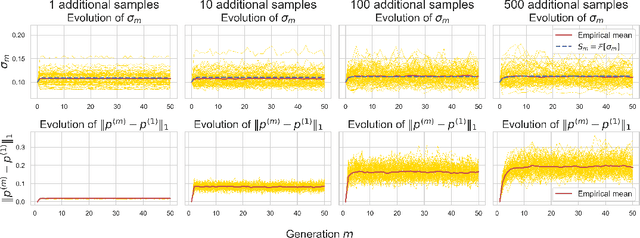
The phenomenon of model collapse, introduced in (Shumailov et al., 2023), refers to the deterioration in performance that occurs when new models are trained on synthetic data generated from previously trained models. This recursive training loop makes the tails of the original distribution disappear, thereby making future-generation models forget about the initial (real) distribution. With the aim of rigorously understanding model collapse in language models, we consider in this paper a statistical model that allows us to characterize the impact of various recursive training scenarios. Specifically, we demonstrate that model collapse cannot be avoided when training solely on synthetic data. However, when mixing both real and synthetic data, we provide an estimate of a maximal amount of synthetic data below which model collapse can eventually be avoided. Our theoretical conclusions are further supported by empirical validations.