 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Unimodal to Multimodal: Scaling up Projectors to Align Modalities
Sep 28, 2024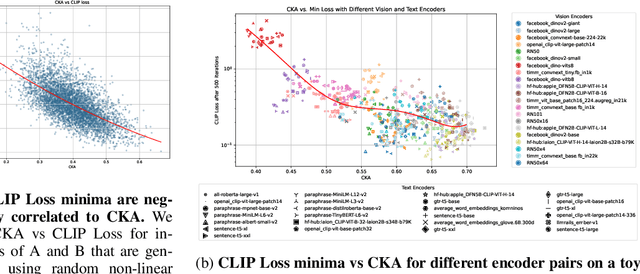

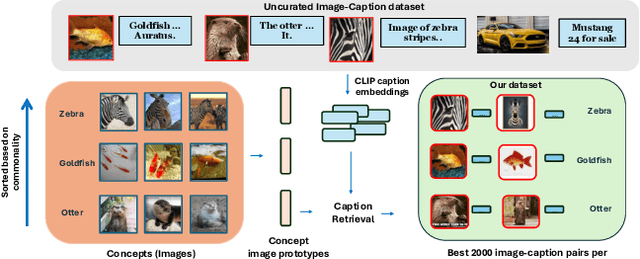
Recent contrastive multimodal vision-language models like CLIP have demonstrated robust open-world semantic understanding, becoming the standard image backbones for vision-language applications due to their aligned latent space. However, this practice has left powerful unimodal encoders for both vision and language underutilized in multimodal applications which raises a key question: Is there a plausible way to connect unimodal backbones for zero-shot vision-language tasks? To this end, we propose a novel approach that aligns vision and language modalities using only projection layers on pretrained, frozen unimodal encoders. Our method exploits the high semantic similarity between embedding spaces of well-trained vision and language models. It involves selecting semantically similar encoders in the latent space, curating a concept-rich dataset of image-caption pairs, and training simple MLP projectors. We evaluated our approach on 12 zero-shot classification datasets and 2 image-text retrieval datasets. Our best model, utilizing DINOv2 and All-Roberta-Large text encoder, achieves 76\(\%\) accuracy on ImageNet with a 20-fold reduction in data and 65 fold reduction in compute requirements. The proposed framework enhances the accessibility of model development while enabling flexible adaptation across diverse scenarios, offering an efficient approach to building multimodal models by utilizing existing unimodal architectures. Code and datasets will be released soon.
Falcon2-11B Technical Report
Jul 20, 2024



We introduce Falcon2-11B, a foundation model trained on over five trillion tokens, and its multimodal counterpart, Falcon2-11B-vlm, which is a vision-to-text model. We report our findings during the training of the Falcon2-11B which follows a multi-stage approach where the early stages are distinguished by their context length and a final stage where we use a curated, high-quality dataset. Additionally, we report the effect of doubling the batch size mid-training and how training loss spikes are affected by the learning rate. The downstream performance of the foundation model is evaluated on established benchmarks, including multilingual and code datasets. The foundation model shows strong generalization across all the tasks which makes it suitable for downstream finetuning use cases. For the vision language model, we report the performance on several benchmarks and show that our model achieves a higher average score compared to open-source models of similar size. The model weights and code of both Falcon2-11B and Falcon2-11B-vlm are made available under a permissive license.
ViSpeR: Multilingual Audio-Visual Speech Recognition
May 27, 2024This work presents an extensive and detailed study on Audio-Visual Speech Recognition (AVSR) for five widely spoken languages: Chinese, Spanish, English, Arabic, and French. We have collected large-scale datasets for each language except for English, and have engaged in the training of supervised learning models. Our model, ViSpeR, is trained in a multi-lingual setting, resulting in competitive performance on newly established benchmarks for each language. The datasets and models are released to the community with an aim to serve as a foundation for triggering and feeding further research work and exploration on Audio-Visual Speech Recognition, an increasingly important area of research. Code available at \href{https://github.com/YasserdahouML/visper}{https://github.com/YasserdahouML/visper}.
Do Vision and Language Encoders Represent the World Similarly?
Jan 10, 2024



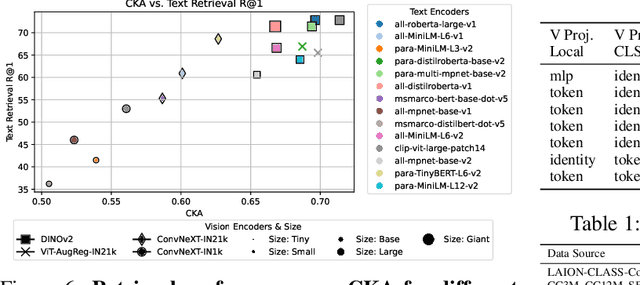
Aligned text-image encoders such as CLIP have become the de facto model for vision-language tasks. Furthermore, modality-specific encoders achieve impressive performances in their respective domains. This raises a central question: does an alignment exist between uni-modal vision and language encoders since they fundamentally represent the same physical world? Analyzing the latent spaces structure of vision and language models on image-caption benchmarks using the Centered Kernel Alignment (CKA), we find that the representation spaces of unaligned and aligned encoders are semantically similar. In the absence of statistical similarity in aligned encoders like CLIP, we show that a possible matching of unaligned encoders exists without any training. We frame this as a seeded graph-matching problem exploiting the semantic similarity between graphs and propose two methods - a Fast Quadratic Assignment Problem optimization, and a novel localized CKA metric-based matching/retrieval. We demonstrate the effectiveness of this on several downstream tasks including cross-lingual, cross-domain caption matching and image classification.
Do VSR Models Generalize Beyond LRS3?
Nov 23, 2023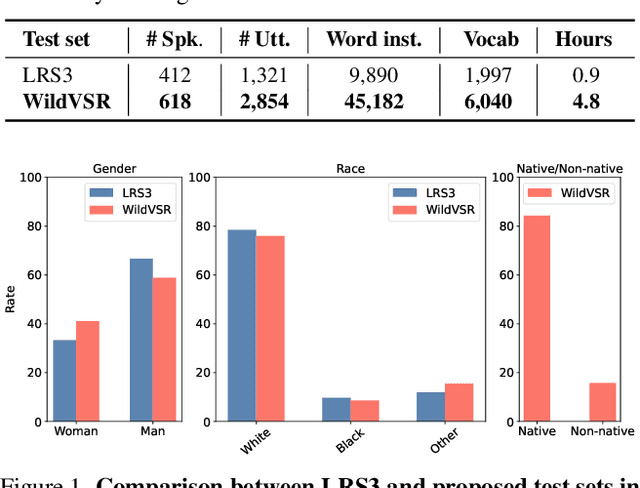
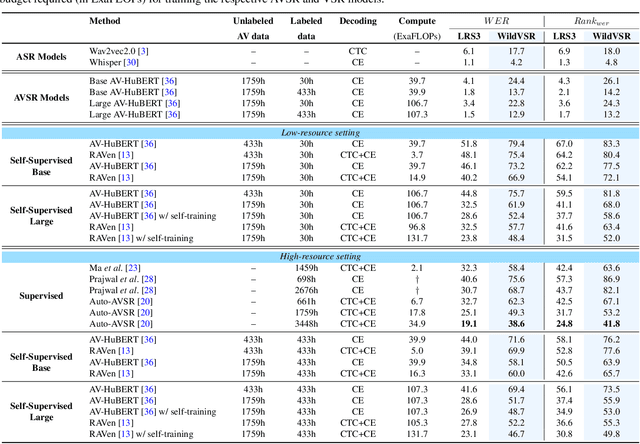
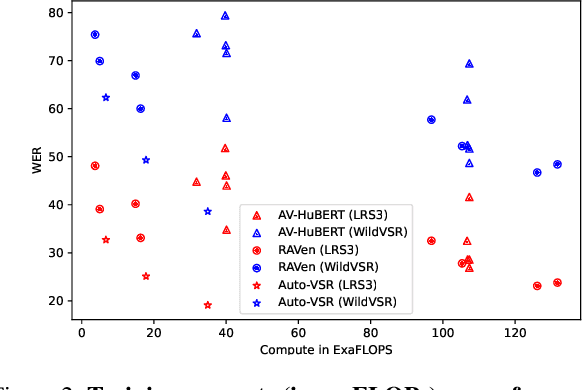
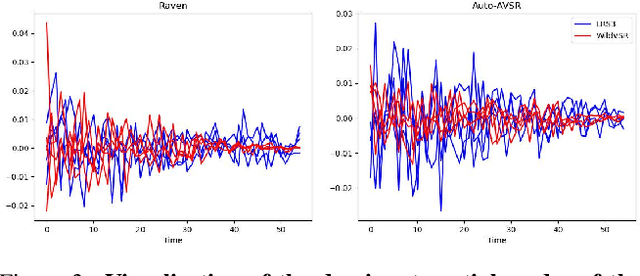
The Lip Reading Sentences-3 (LRS3) benchmark has primarily been the focus of intense research in visual speech recognition (VSR) during the last few years. As a result, there is an increased risk of overfitting to its excessively used test set, which is only one hour duration. To alleviate this issue, we build a new VSR test set named WildVSR, by closely following the LRS3 dataset creation processes. We then evaluate and analyse the extent to which the current VSR models generalize to the new test data. We evaluate a broad range of publicly available VSR models and find significant drops in performance on our test set, compared to their corresponding LRS3 results. Our results suggest that the increase in word error rates is caused by the models inability to generalize to slightly harder and in the wild lip sequences than those found in the LRS3 test set. Our new test benchmark is made public in order to enable future research towards more robust VSR models.
Learning Saliency From Fixations
Nov 23, 2023We present a novel approach for saliency prediction in images, leveraging parallel decoding in transformers to learn saliency solely from fixation maps. Models typically rely on continuous saliency maps, to overcome the difficulty of optimizing for the discrete fixation map. We attempt to replicate the experimental setup that generates saliency datasets. Our approach treats saliency prediction as a direct set prediction problem, via a global loss that enforces unique fixations prediction through bipartite matching and a transformer encoder-decoder architecture. By utilizing a fixed set of learned fixation queries, the cross-attention reasons over the image features to directly output the fixation points, distinguishing it from other modern saliency predictors. Our approach, named Saliency TRansformer (SalTR), achieves metric scores on par with state-of-the-art approaches on the Salicon and MIT300 benchmarks.
Lip2Vec: Efficient and Robust Visual Speech Recognition via Latent-to-Latent Visual to Audio Representation Mapping
Aug 11, 2023Visual Speech Recognition (VSR) differs from the common perception tasks as it requires deeper reasoning over the video sequence, even by human experts. Despite the recent advances in VSR, current approaches rely on labeled data to fully train or finetune their models predicting the target speech. This hinders their ability to generalize well beyond the training set and leads to performance degeneration under out-of-distribution challenging scenarios. Unlike previous works that involve auxiliary losses or complex training procedures and architectures, we propose a simple approach, named Lip2Vec that is based on learning a prior model. Given a robust visual speech encoder, this network maps the encoded latent representations of the lip sequence to their corresponding latents from the audio pair, which are sufficiently invariant for effective text decoding. The generated audio representation is then decoded to text using an off-the-shelf Audio Speech Recognition (ASR) model. The proposed model compares favorably with fully-supervised learning methods on the LRS3 dataset achieving 26 WER. Unlike SoTA approaches, our model keeps a reasonable performance on the VoxCeleb test set. We believe that reprogramming the VSR as an ASR task narrows the performance gap between the two and paves the way for more flexible formulations of lip reading.
One-Step Distributional Reinforcement Learning
Apr 27, 2023



Reinforcement learning (RL) allows an agent interacting sequentially with an environment to maximize its long-term expected return. In the distributional RL (DistrRL) paradigm, the agent goes beyond the limit of the expected value, to capture the underlying probability distribution of the return across all time steps. The set of DistrRL algorithms has led to improved empirical performance. Nevertheless, the theory of DistrRL is still not fully understood, especially in the control case. In this paper, we present the simpler one-step distributional reinforcement learning (OS-DistrRL) framework encompassing only the randomness induced by the one-step dynamics of the environment. Contrary to DistrRL, we show that our approach comes with a unified theory for both policy evaluation and control. Indeed, we propose two OS-DistrRL algorithms for which we provide an almost sure convergence analysis. The proposed approach compares favorably with categorical DistrRL on various environments.