 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Unimodal to Multimodal: Scaling up Projectors to Align Modalities
Sep 28, 2024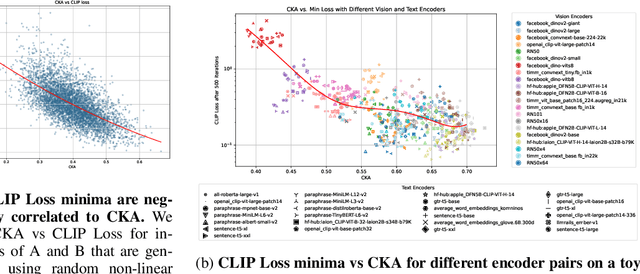
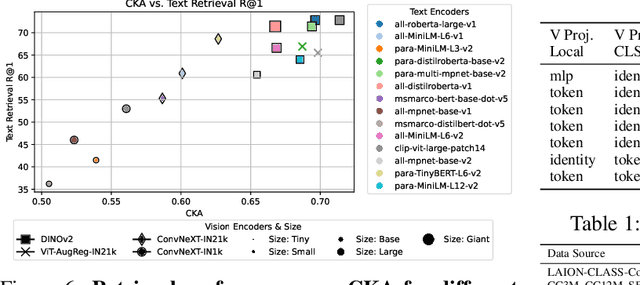

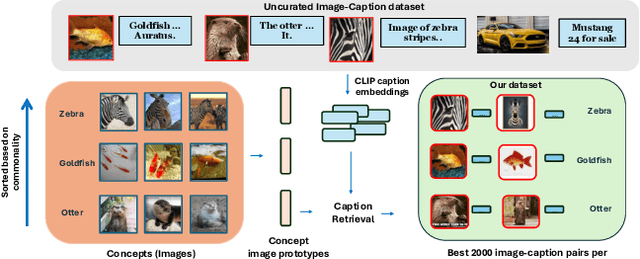
Recent contrastive multimodal vision-language models like CLIP have demonstrated robust open-world semantic understanding, becoming the standard image backbones for vision-language applications due to their aligned latent space. However, this practice has left powerful unimodal encoders for both vision and language underutilized in multimodal applications which raises a key question: Is there a plausible way to connect unimodal backbones for zero-shot vision-language tasks? To this end, we propose a novel approach that aligns vision and language modalities using only projection layers on pretrained, frozen unimodal encoders. Our method exploits the high semantic similarity between embedding spaces of well-trained vision and language models. It involves selecting semantically similar encoders in the latent space, curating a concept-rich dataset of image-caption pairs, and training simple MLP projectors. We evaluated our approach on 12 zero-shot classification datasets and 2 image-text retrieval datasets. Our best model, utilizing DINOv2 and All-Roberta-Large text encoder, achieves 76\(\%\) accuracy on ImageNet with a 20-fold reduction in data and 65 fold reduction in compute requirements. The proposed framework enhances the accessibility of model development while enabling flexible adaptation across diverse scenarios, offering an efficient approach to building multimodal models by utilizing existing unimodal architectures. Code and datasets will be released soon.
Do Vision and Language Encoders Represent the World Similarly?
Jan 10, 2024



Aligned text-image encoders such as CLIP have become the de facto model for vision-language tasks. Furthermore, modality-specific encoders achieve impressive performances in their respective domains. This raises a central question: does an alignment exist between uni-modal vision and language encoders since they fundamentally represent the same physical world? Analyzing the latent spaces structure of vision and language models on image-caption benchmarks using the Centered Kernel Alignment (CKA), we find that the representation spaces of unaligned and aligned encoders are semantically similar. In the absence of statistical similarity in aligned encoders like CLIP, we show that a possible matching of unaligned encoders exists without any training. We frame this as a seeded graph-matching problem exploiting the semantic similarity between graphs and propose two methods - a Fast Quadratic Assignment Problem optimization, and a novel localized CKA metric-based matching/retrieval. We demonstrate the effectiveness of this on several downstream tasks including cross-lingual, cross-domain caption matching and image classification.
EgoSchema: A Diagnostic Benchmark for Very Long-form Video Language Understanding
Aug 17, 2023



We introduce EgoSchema, a very long-form video question-answering dataset, and benchmark to evaluate long video understanding capabilities of modern vision and language systems. Derived from Ego4D, EgoSchema consists of over 5000 human curated multiple choice question answer pairs, spanning over 250 hours of real video data, covering a very broad range of natural human activity and behavior. For each question, EgoSchema requires the correct answer to be selected between five given options based on a three-minute-long video clip. While some prior works have proposed video datasets with long clip lengths, we posit that merely the length of the video clip does not truly capture the temporal difficulty of the video task that is being considered. To remedy this, we introduce temporal certificate sets, a general notion for capturing the intrinsic temporal understanding length associated with a broad range of video understanding tasks & datasets. Based on this metric, we find EgoSchema to have intrinsic temporal lengths over 5.7x longer than the second closest dataset and 10x to 100x longer than any other video understanding dataset. Further, our evaluation of several current state-of-the-art video and language models shows them to be severely lacking in long-term video understanding capabilities. Even models with several billions of parameters achieve QA accuracy less than 33% (random is 20%) on the EgoSchema multi-choice question answering task, while humans achieve about 76% accuracy. We posit that \name{}{}, with its long intrinsic temporal structures and diverse complexity, would serve as a valuable evaluation probe for developing effective long-term video understanding systems in the future. Data and Zero-shot model evaluation code are open-sourced for both public and commercial use under the Ego4D license at http://egoschema.github.io