 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalcon Perception
Mar 28, 2026Perception-centric systems are typically implemented with a modular encoder-decoder pipeline: a vision backbone for feature extraction and a separate decoder (or late-fusion module) for task prediction. This raises a central question: is this architectural separation essential or can a single early-fusion stack do both perception and task modeling at scale? We introduce Falcon Perception, a unified dense Transformer that processes image patches and text tokens in a shared parameter space from the first layer, using a hybrid attention pattern (bidirectional among image tokens, causal for prediction tokens) to combine global visual context with autoregressive, variable-length instance generation. To keep dense outputs practical, Falcon Perception retains a lightweight token interface and decodes continuous spatial outputs with specialized heads, enabling parallel high-resolution mask prediction. Our design promotes simplicity: we keep a single scalable backbone and shift complexity toward data and training signals, adding only small heads where outputs are continuous and dense. On SA-Co, Falcon Perception improves mask quality to 68.0 Macro-F$_1$ compared to 62.3 of SAM3. We also introduce PBench, a benchmark targeting compositional prompts (OCR, spatial constraints, relations) and dense long-context regimes, where the model shows better gains. Finally, we extend the same early-fusion recipe to Falcon OCR: a compact 300M-parameter model which attains 80.3% on olmOCR and 88.64 on OmniDocBench.
VisRes Bench: On Evaluating the Visual Reasoning Capabilities of VLMs
Dec 24, 2025Vision-Language Models (VLMs) have achieved remarkable progress across tasks such as visual question answering and image captioning. Yet, the extent to which these models perform visual reasoning as opposed to relying on linguistic priors remains unclear. To address this, we introduce VisRes Bench, a benchmark designed to study visual reasoning in naturalistic settings without contextual language supervision. Analyzing model behavior across three levels of complexity, we uncover clear limitations in perceptual and relational visual reasoning capacities. VisRes isolates distinct reasoning abilities across its levels. Level 1 probes perceptual completion and global image matching under perturbations such as blur, texture changes, occlusion, and rotation; Level 2 tests rule-based inference over a single attribute (e.g., color, count, orientation); and Level 3 targets compositional reasoning that requires integrating multiple visual attributes. Across more than 19,000 controlled task images, we find that state-of-the-art VLMs perform near random under subtle perceptual perturbations, revealing limited abstraction beyond pattern recognition. We conclude by discussing how VisRes provides a unified framework for advancing abstract visual reasoning in multimodal research.
AMoE: Agglomerative Mixture-of-Experts Vision Foundation Model
Dec 23, 2025Vision foundation models trained via multi-teacher distillation offer a promising path toward unified visual representations, yet the learning dynamics and data efficiency of such approaches remain underexplored. In this paper, we systematically study multi-teacher distillation for vision foundation models and identify key factors that enable training at lower computational cost. We introduce Agglomerative Mixture-of-Experts Vision Foundation Models (AMoE), which distill knowledge from SigLIP2 and DINOv3 simultaneously into a Mixture-of-Experts student. We show that (1) our Asymmetric Relation-Knowledge Distillation loss preserves the geometric properties of each teacher while enabling effective knowledge transfer, (2) token-balanced batching that packs varying-resolution images into sequences with uniform token budgets stabilizes representation learning across resolutions without sacrificing performance, and (3) hierarchical clustering and sampling of training data--typically reserved for self-supervised learning--substantially improves sample efficiency over random sampling for multi-teacher distillation. By combining these findings, we curate OpenLVD200M, a 200M-image corpus that demonstrates superior efficiency for multi-teacher distillation. Instantiated in a Mixture-of-Experts. We release OpenLVD200M and distilled models.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
From Unimodal to Multimodal: Scaling up Projectors to Align Modalities
Sep 28, 2024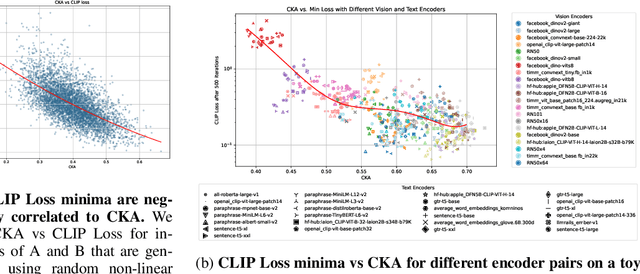
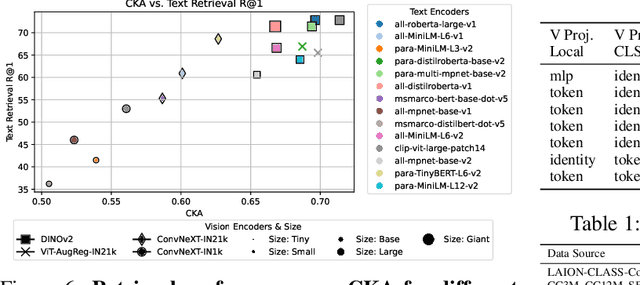

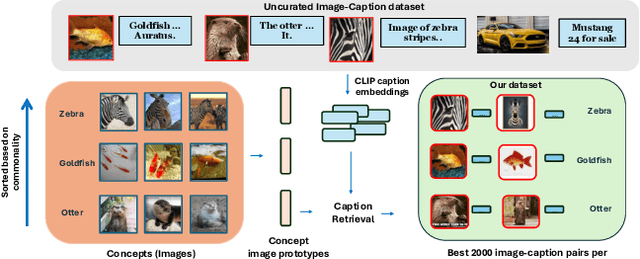
Recent contrastive multimodal vision-language models like CLIP have demonstrated robust open-world semantic understanding, becoming the standard image backbones for vision-language applications due to their aligned latent space. However, this practice has left powerful unimodal encoders for both vision and language underutilized in multimodal applications which raises a key question: Is there a plausible way to connect unimodal backbones for zero-shot vision-language tasks? To this end, we propose a novel approach that aligns vision and language modalities using only projection layers on pretrained, frozen unimodal encoders. Our method exploits the high semantic similarity between embedding spaces of well-trained vision and language models. It involves selecting semantically similar encoders in the latent space, curating a concept-rich dataset of image-caption pairs, and training simple MLP projectors. We evaluated our approach on 12 zero-shot classification datasets and 2 image-text retrieval datasets. Our best model, utilizing DINOv2 and All-Roberta-Large text encoder, achieves 76\(\%\) accuracy on ImageNet with a 20-fold reduction in data and 65 fold reduction in compute requirements. The proposed framework enhances the accessibility of model development while enabling flexible adaptation across diverse scenarios, offering an efficient approach to building multimodal models by utilizing existing unimodal architectures. Code and datasets will be released soon.
Falcon2-11B Technical Report
Jul 20, 2024



We introduce Falcon2-11B, a foundation model trained on over five trillion tokens, and its multimodal counterpart, Falcon2-11B-vlm, which is a vision-to-text model. We report our findings during the training of the Falcon2-11B which follows a multi-stage approach where the early stages are distinguished by their context length and a final stage where we use a curated, high-quality dataset. Additionally, we report the effect of doubling the batch size mid-training and how training loss spikes are affected by the learning rate. The downstream performance of the foundation model is evaluated on established benchmarks, including multilingual and code datasets. The foundation model shows strong generalization across all the tasks which makes it suitable for downstream finetuning use cases. For the vision language model, we report the performance on several benchmarks and show that our model achieves a higher average score compared to open-source models of similar size. The model weights and code of both Falcon2-11B and Falcon2-11B-vlm are made available under a permissive license.
ViSpeR: Multilingual Audio-Visual Speech Recognition
May 27, 2024This work presents an extensive and detailed study on Audio-Visual Speech Recognition (AVSR) for five widely spoken languages: Chinese, Spanish, English, Arabic, and French. We have collected large-scale datasets for each language except for English, and have engaged in the training of supervised learning models. Our model, ViSpeR, is trained in a multi-lingual setting, resulting in competitive performance on newly established benchmarks for each language. The datasets and models are released to the community with an aim to serve as a foundation for triggering and feeding further research work and exploration on Audio-Visual Speech Recognition, an increasingly important area of research. Code available at \href{https://github.com/YasserdahouML/visper}{https://github.com/YasserdahouML/visper}.
On permutation symmetries in Bayesian neural network posteriors: a variational perspective
Oct 16, 2023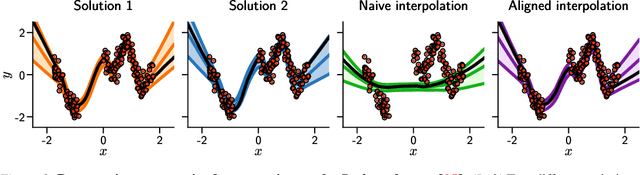
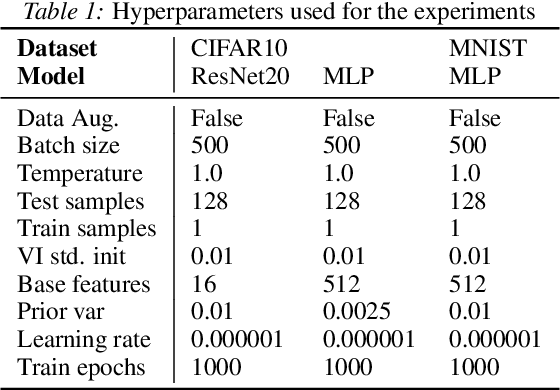
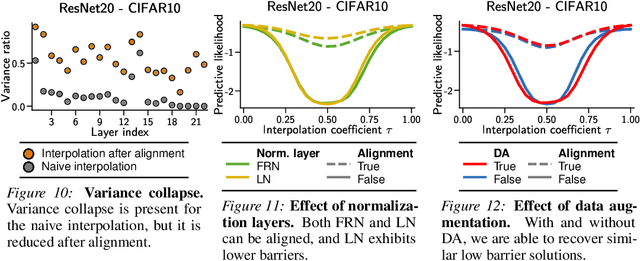
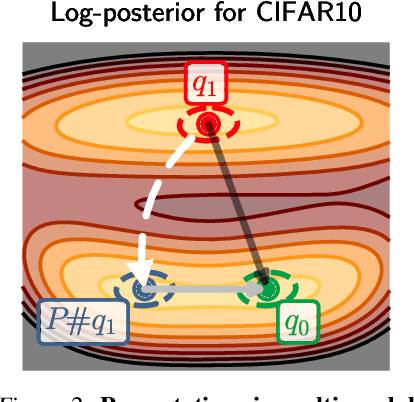
The elusive nature of gradient-based optimization in neural networks is tied to their loss landscape geometry, which is poorly understood. However recent work has brought solid evidence that there is essentially no loss barrier between the local solutions of gradient descent, once accounting for weight-permutations that leave the network's computation unchanged. This raises questions for approximate inference in Bayesian neural networks (BNNs), where we are interested in marginalizing over multiple points in the loss landscape. In this work, we first extend the formalism of marginalized loss barrier and solution interpolation to BNNs, before proposing a matching algorithm to search for linearly connected solutions. This is achieved by aligning the distributions of two independent approximate Bayesian solutions with respect to permutation matrices. We build on the results of Ainsworth et al. (2023), reframing the problem as a combinatorial optimization one, using an approximation to the sum of bilinear assignment problem. We then experiment on a variety of architectures and datasets, finding nearly zero marginalized loss barriers for linearly connected solutions.
CLDA: Contrastive Learning for Semi-Supervised Domain Adaptation
Jun 30, 2021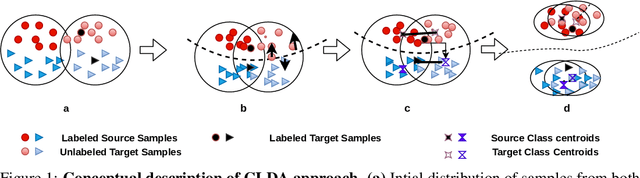
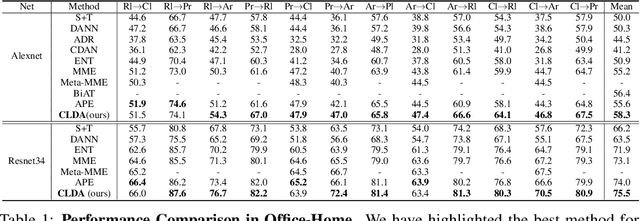
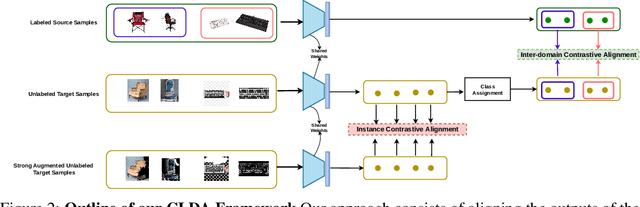
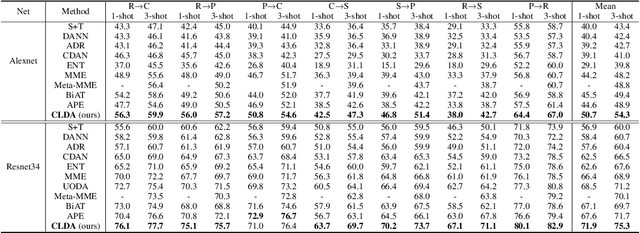
Unsupervised Domain Adaptation (UDA) aims to align the labeled source distribution with the unlabeled target distribution to obtain domain invariant predictive models. However, the application of well-known UDA approaches does not generalize well in Semi-Supervised Domain Adaptation (SSDA) scenarios where few labeled samples from the target domain are available. In this paper, we propose a simple Contrastive Learning framework for semi-supervised Domain Adaptation (CLDA) that attempts to bridge the intra-domain gap between the labeled and unlabeled target distributions and inter-domain gap between source and unlabeled target distribution in SSDA. We suggest employing class-wise contrastive learning to reduce the inter-domain gap and instance-level contrastive alignment between the original (input image) and strongly augmented unlabeled target images to minimize the intra-domain discrepancy. We have shown empirically that both of these modules complement each other to achieve superior performance. Experiments on three well-known domain adaptation benchmark datasets namely DomainNet, Office-Home, and Office31 demonstrate the effectiveness of our approach. CLDA achieves state-of-the-art results on all the above datasets.
Semi-Supervised Action Recognition with Temporal Contrastive Learning
Feb 04, 2021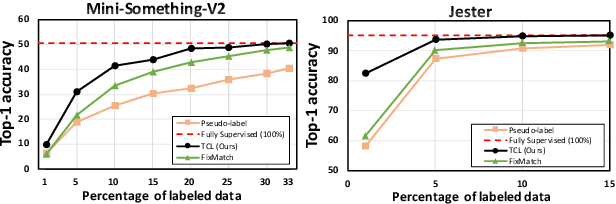
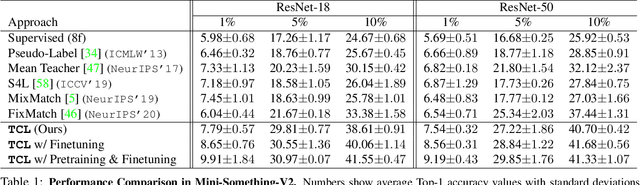
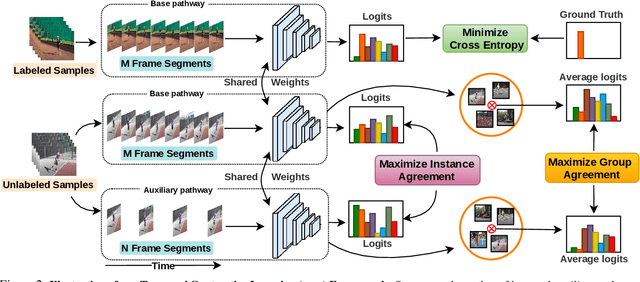
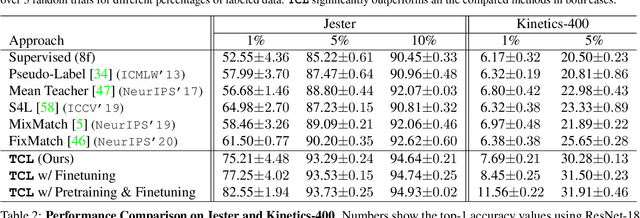
Learning to recognize actions from only a handful of labeled videos is a challenging problem due to the scarcity of tediously collected activity labels. We approach this problem by learning a two-pathway temporal contrastive model using unlabeled videos at two different speeds leveraging the fact that changing video speed does not change an action. Specifically, we propose to maximize the similarity between encoded representations of the same video at two different speeds as well as minimize the similarity between different videos played at different speeds. This way we use the rich supervisory information in terms of 'time' that is present in otherwise unsupervised pool of videos. With this simple yet effective strategy of manipulating video playback rates, we considerably outperform video extensions of sophisticated state-of-the-art semi-supervised image recognition methods across multiple diverse benchmark datasets and network architectures. Interestingly, our proposed approach benefits from out-of-domain unlabeled videos showing generalization and robustness. We also perform rigorous ablations and analysis to validate our approach.