 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom predictions to confidence intervals: an empirical study of conformal prediction methods for in-context learning
Apr 22, 2025Transformers have become a standard architecture in machine learning, demonstrating strong in-context learning (ICL) abilities that allow them to learn from the prompt at inference time. However, uncertainty quantification for ICL remains an open challenge, particularly in noisy regression tasks. This paper investigates whether ICL can be leveraged for distribution-free uncertainty estimation, proposing a method based on conformal prediction to construct prediction intervals with guaranteed coverage. While traditional conformal methods are computationally expensive due to repeated model fitting, we exploit ICL to efficiently generate confidence intervals in a single forward pass. Our empirical analysis compares this approach against ridge regression-based conformal methods, showing that conformal prediction with in-context learning (CP with ICL) achieves robust and scalable uncertainty estimates. Additionally, we evaluate its performance under distribution shifts and establish scaling laws to guide model training. These findings bridge ICL and conformal prediction, providing a theoretically grounded and new framework for uncertainty quantification in transformer-based models.
Optimizing Diffusion Models for Joint Trajectory Prediction and Controllable Generation
Aug 01, 2024



Diffusion models are promising for joint trajectory prediction and controllable generation in autonomous driving, but they face challenges of inefficient inference steps and high computational demands. To tackle these challenges, we introduce Optimal Gaussian Diffusion (OGD) and Estimated Clean Manifold (ECM) Guidance. OGD optimizes the prior distribution for a small diffusion time $T$ and starts the reverse diffusion process from it. ECM directly injects guidance gradients to the estimated clean manifold, eliminating extensive gradient backpropagation throughout the network. Our methodology streamlines the generative process, enabling practical applications with reduced computational overhead. Experimental validation on the large-scale Argoverse 2 dataset demonstrates our approach's superior performance, offering a viable solution for computationally efficient, high-quality joint trajectory prediction and controllable generation for autonomous driving. Our project webpage is at https://yixiaowang7.github.io/OptTrajDiff_Page/.
Class Balanced Dynamic Acquisition for Domain Adaptive Semantic Segmentation using Active Learning
Nov 23, 2023



Domain adaptive active learning is leading the charge in label-efficient training of neural networks. For semantic segmentation, state-of-the-art models jointly use two criteria of uncertainty and diversity to select training labels, combined with a pixel-wise acquisition strategy. However, we show that such methods currently suffer from a class imbalance issue which degrades their performance for larger active learning budgets. We then introduce Class Balanced Dynamic Acquisition (CBDA), a novel active learning method that mitigates this issue, especially in high-budget regimes. The more balanced labels increase minority class performance, which in turn allows the model to outperform the previous baseline by 0.6, 1.7, and 2.4 mIoU for budgets of 5%, 10%, and 20%, respectively. Additionally, the focus on minority classes leads to improvements of the minimum class performance of 0.5, 2.9, and 4.6 IoU respectively. The top-performing model even exceeds the fully supervised baseline, showing that a more balanced label than the entire ground truth can be beneficial.
On permutation symmetries in Bayesian neural network posteriors: a variational perspective
Oct 16, 2023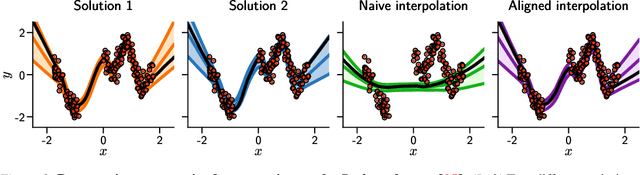
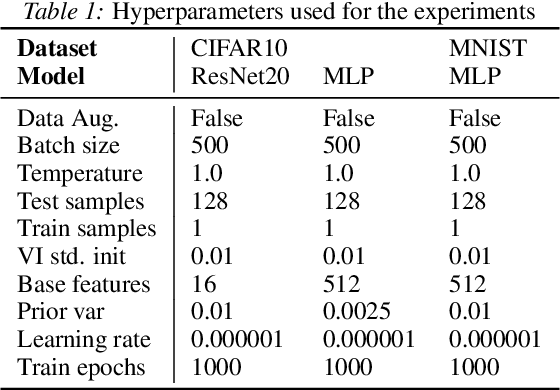
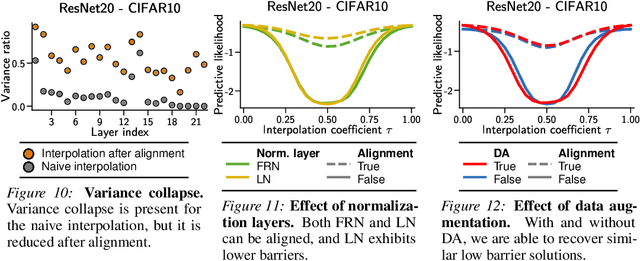
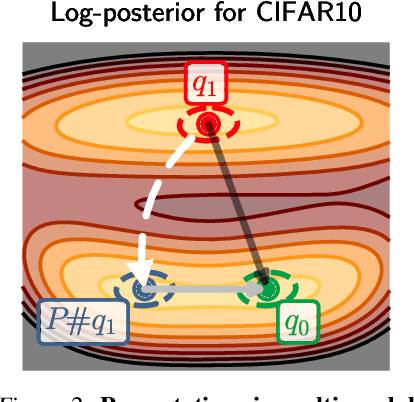
The elusive nature of gradient-based optimization in neural networks is tied to their loss landscape geometry, which is poorly understood. However recent work has brought solid evidence that there is essentially no loss barrier between the local solutions of gradient descent, once accounting for weight-permutations that leave the network's computation unchanged. This raises questions for approximate inference in Bayesian neural networks (BNNs), where we are interested in marginalizing over multiple points in the loss landscape. In this work, we first extend the formalism of marginalized loss barrier and solution interpolation to BNNs, before proposing a matching algorithm to search for linearly connected solutions. This is achieved by aligning the distributions of two independent approximate Bayesian solutions with respect to permutation matrices. We build on the results of Ainsworth et al. (2023), reframing the problem as a combinatorial optimization one, using an approximation to the sum of bilinear assignment problem. We then experiment on a variety of architectures and datasets, finding nearly zero marginalized loss barriers for linearly connected solutions.
Energy Consumption Analysis of pruned Semantic Segmentation Networks on an Embedded GPU
Jun 13, 2022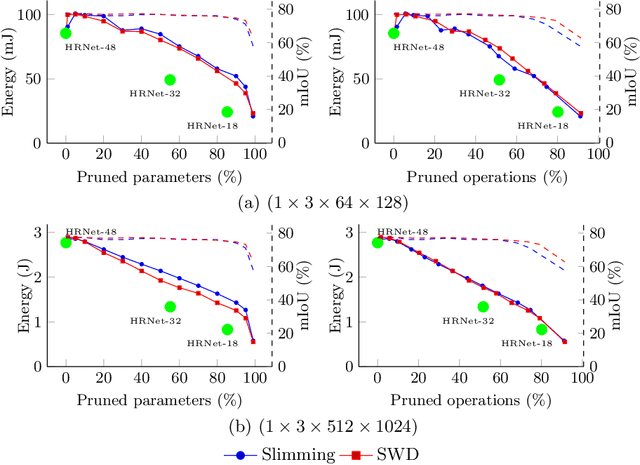
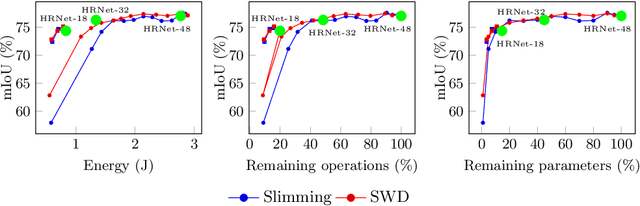
Deep neural networks are the state of the art in many computer vision tasks. Their deployment in the context of autonomous vehicles is of particular interest, since their limitations in terms of energy consumption prohibit the use of very large networks, that typically reach the best performance. A common method to reduce the complexity of these architectures, without sacrificing accuracy, is to rely on pruning, in which the least important portions are eliminated. There is a large literature on the subject, but interestingly few works have measured the actual impact of pruning on energy. In this work, we are interested in measuring it in the specific context of semantic segmentation for autonomous driving, using the Cityscapes dataset. To this end, we analyze the impact of recently proposed structured pruning methods when trained architectures are deployed on a Jetson Xavier embedded GPU.
Leveraging Structured Pruning of Convolutional Neural Networks
Jun 13, 2022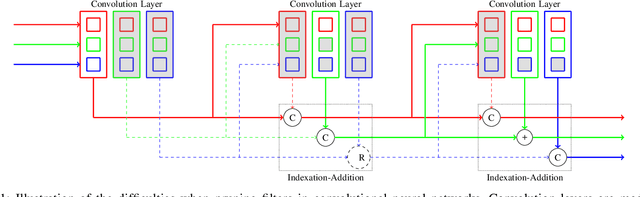
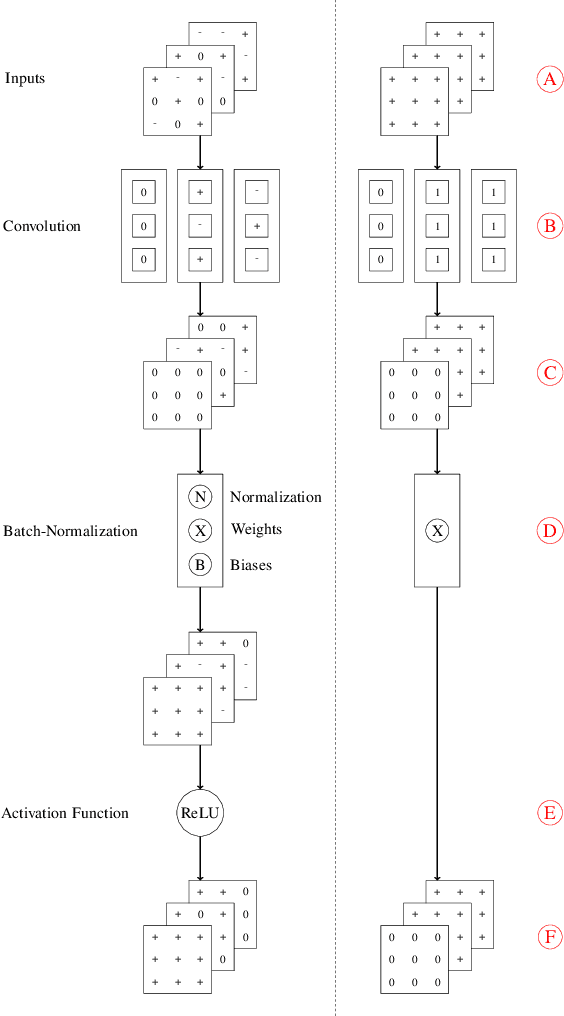
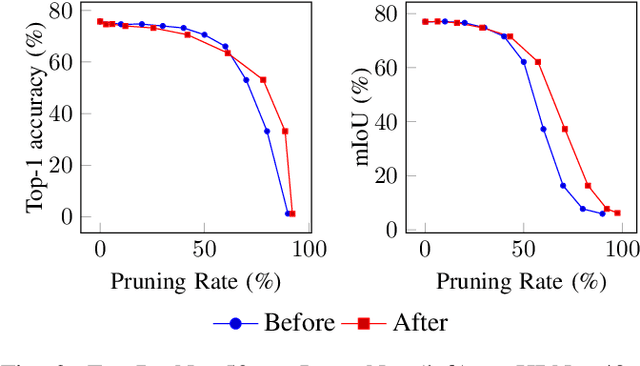
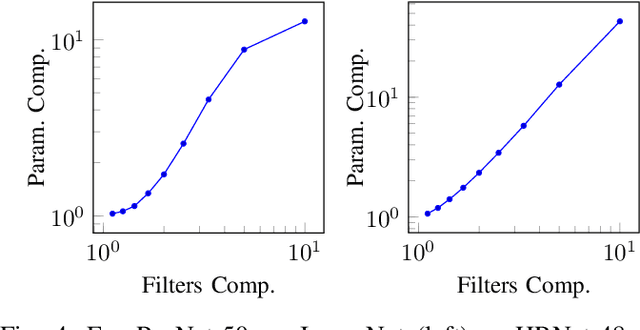
Structured pruning is a popular method to reduce the cost of convolutional neural networks, that are the state of the art in many computer vision tasks. However, depending on the architecture, pruning introduces dimensional discrepancies which prevent the actual reduction of pruned networks. To tackle this problem, we propose a method that is able to take any structured pruning mask and generate a network that does not encounter any of these problems and can be leveraged efficiently. We provide an accurate description of our solution and show results of gains, in energy consumption and inference time on embedded hardware, of pruned convolutional neural networks.
Continuous Pruning of Deep Convolutional Networks Using Selective Weight Decay
Dec 22, 2020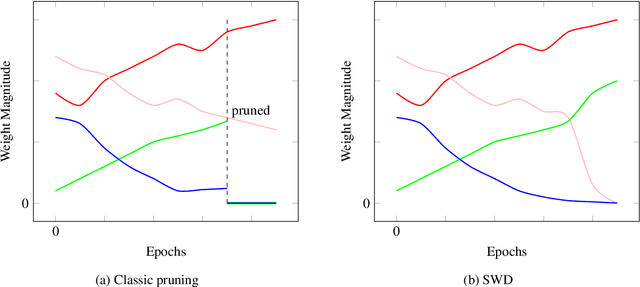
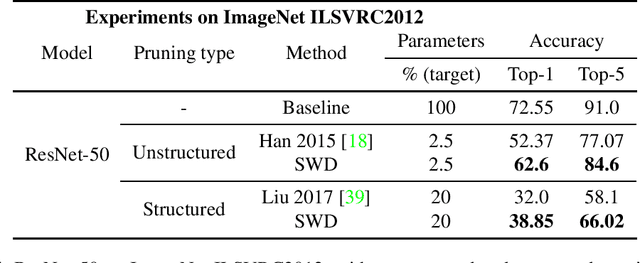
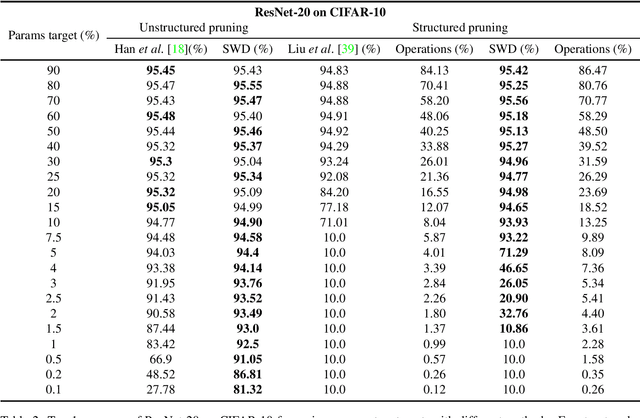
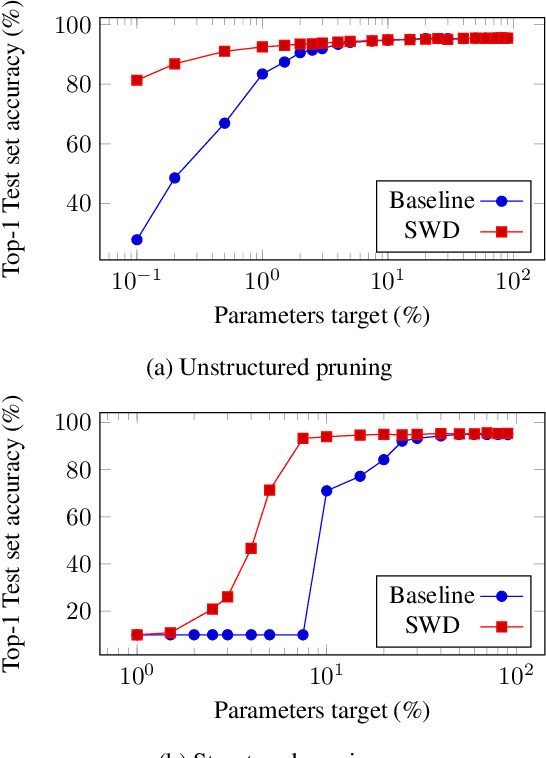
During the last decade, deep convolutional networks have become the reference for many machine learning tasks, especially in computer vision. However, large computational needs make them hard to deploy on resource-constrained hardware. Pruning has emerged as a standard way to compress such large networks. Yet, the severe perturbation caused by most pruning approaches is thought to hinder their efficacy. Drawing inspiration from Lagrangian Smoothing, we introduce a new technique, Selective Weight Decay (SWD), which achieves continuous pruning throughout training. Our theoretically-grounded approach is versatile and can be applied to any problem, network or pruning structure. We show that SWD compares favorably to other approaches in terms of performance/parameters ratio on the CIFAR-10 and ImageNet ILSVRC2012 datasets. On CIFAR-10 and unstructured pruning, for a target rate of 0.1% unpruned parameters, SWD attains a Top-1 accuracy of 81.32% while the reference method only reaches 27.78%. On CIFAR-10 and structured pruning, for a target rate of 2.5% unpruned parameters, the reference technique drops at 10% (random guess) while SWD maintains the Top-1 accuracy at 93.22%. On the ImageNet ILSVRC2012 dataset with unstructured pruning and the same target rate of 2.5%, SWD attains 84.6% Top-5 accuracy instead of the 77.07% reached by the reference.