 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLoCoRA: Federated learning compression with low-rank adaptation
Jun 20, 2024



Low-Rank Adaptation (LoRA) methods have gained popularity in efficient parameter fine-tuning of models containing hundreds of billions of parameters. In this work, instead, we demonstrate the application of LoRA methods to train small-vision models in Federated Learning (FL) from scratch. We first propose an aggregation-agnostic method to integrate LoRA within FL, named FLoCoRA, showing that the method is capable of reducing communication costs by 4.8 times, while having less than 1% accuracy degradation, for a CIFAR-10 classification task with a ResNet-8. Next, we show that the same method can be extended with an affine quantization scheme, dividing the communication cost by 18.6 times, while comparing it with the standard method, with still less than 1% of accuracy loss, tested with on a ResNet-18 model. Our formulation represents a strong baseline for message size reduction, even when compared to conventional model compression works, while also reducing the training memory requirements due to the low-rank adaptation.
PEFSL: A deployment Pipeline for Embedded Few-Shot Learning on a FPGA SoC
Apr 30, 2024This paper tackles the challenges of implementing few-shot learning on embedded systems, specifically FPGA SoCs, a vital approach for adapting to diverse classification tasks, especially when the costs of data acquisition or labeling prove to be prohibitively high. Our contributions encompass the development of an end-to-end open-source pipeline for a few-shot learning platform for object classification on a FPGA SoCs. The pipeline is built on top of the Tensil open-source framework, facilitating the design, training, evaluation, and deployment of DNN backbones tailored for few-shot learning. Additionally, we showcase our work's potential by building and deploying a low-power, low-latency demonstrator trained on the MiniImageNet dataset with a dataflow architecture. The proposed system has a latency of 30 ms while consuming 6.2 W on the PYNQ-Z1 board.
Federated learning compression designed for lightweight communications
Oct 23, 2023Federated Learning (FL) is a promising distributed method for edge-level machine learning, particularly for privacysensitive applications such as those in military and medical domains, where client data cannot be shared or transferred to a cloud computing server. In many use-cases, communication cost is a major challenge in FL due to its natural intensive network usage. Client devices, such as smartphones or Internet of Things (IoT) nodes, have limited resources in terms of energy, computation, and memory. To address these hardware constraints, lightweight models and compression techniques such as pruning and quantization are commonly adopted in centralised paradigms. In this paper, we investigate the impact of compression techniques on FL for a typical image classification task. Going further, we demonstrate that a straightforward method can compresses messages up to 50% while having less than 1% of accuracy loss, competing with state-of-the-art techniques.
Energy Consumption Analysis of pruned Semantic Segmentation Networks on an Embedded GPU
Jun 13, 2022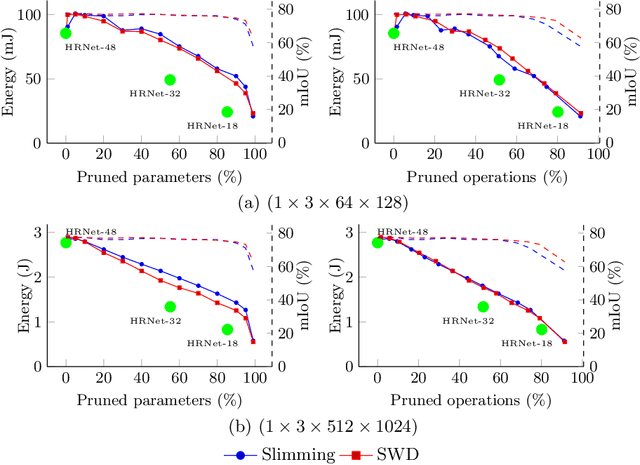
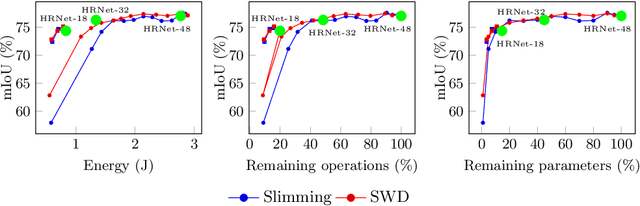
Deep neural networks are the state of the art in many computer vision tasks. Their deployment in the context of autonomous vehicles is of particular interest, since their limitations in terms of energy consumption prohibit the use of very large networks, that typically reach the best performance. A common method to reduce the complexity of these architectures, without sacrificing accuracy, is to rely on pruning, in which the least important portions are eliminated. There is a large literature on the subject, but interestingly few works have measured the actual impact of pruning on energy. In this work, we are interested in measuring it in the specific context of semantic segmentation for autonomous driving, using the Cityscapes dataset. To this end, we analyze the impact of recently proposed structured pruning methods when trained architectures are deployed on a Jetson Xavier embedded GPU.
Leveraging Structured Pruning of Convolutional Neural Networks
Jun 13, 2022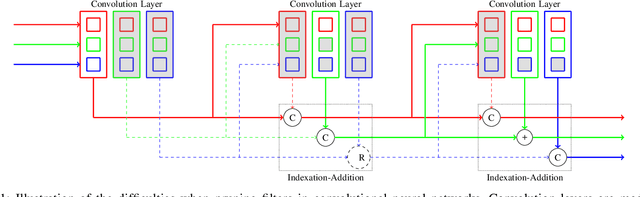
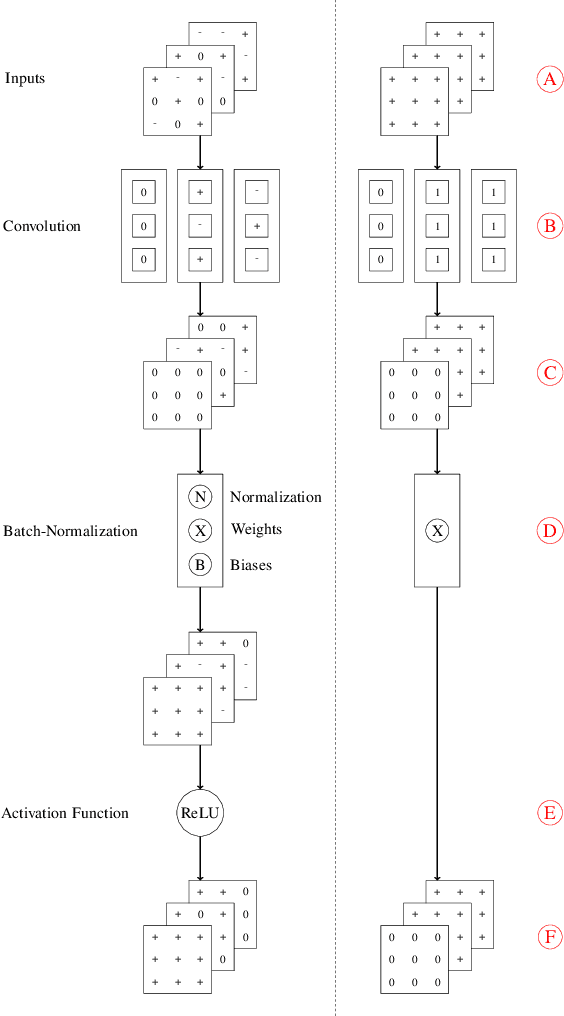
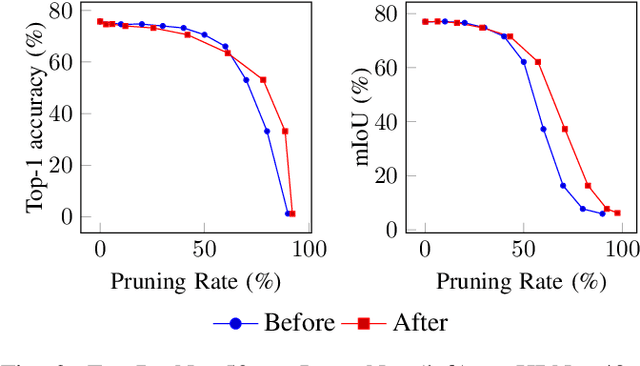
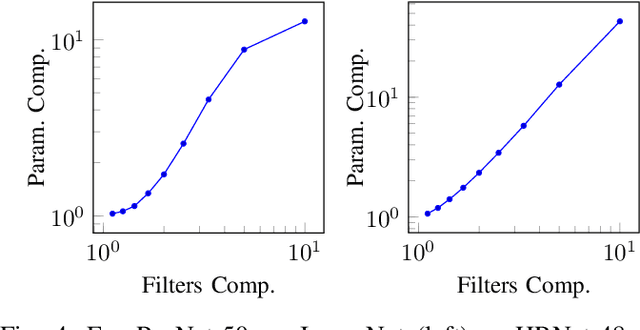
Structured pruning is a popular method to reduce the cost of convolutional neural networks, that are the state of the art in many computer vision tasks. However, depending on the architecture, pruning introduces dimensional discrepancies which prevent the actual reduction of pruned networks. To tackle this problem, we propose a method that is able to take any structured pruning mask and generate a network that does not encounter any of these problems and can be leveraged efficiently. We provide an accurate description of our solution and show results of gains, in energy consumption and inference time on embedded hardware, of pruned convolutional neural networks.
Continuous Pruning of Deep Convolutional Networks Using Selective Weight Decay
Dec 22, 2020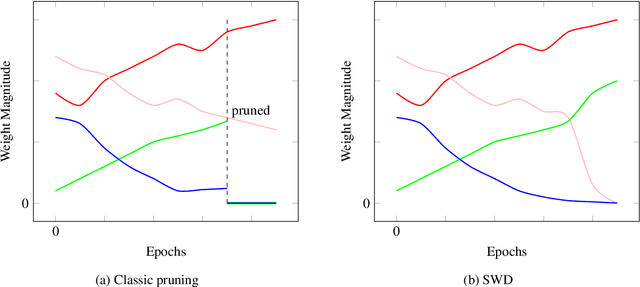
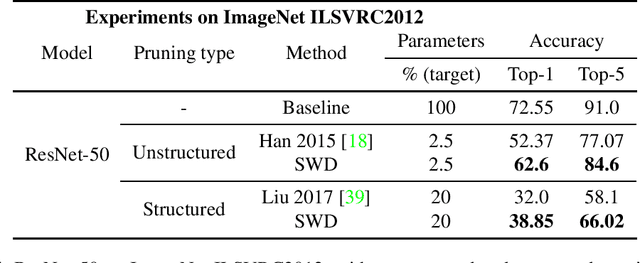
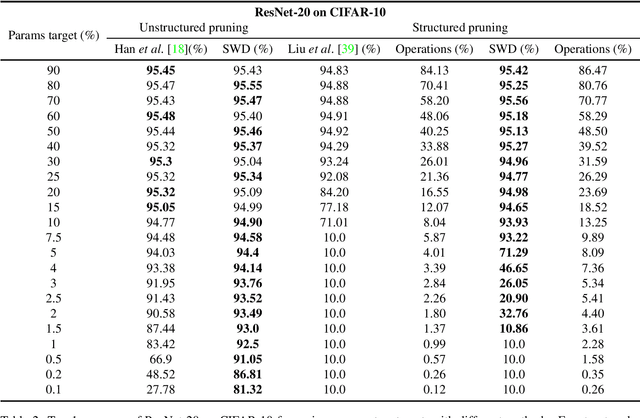
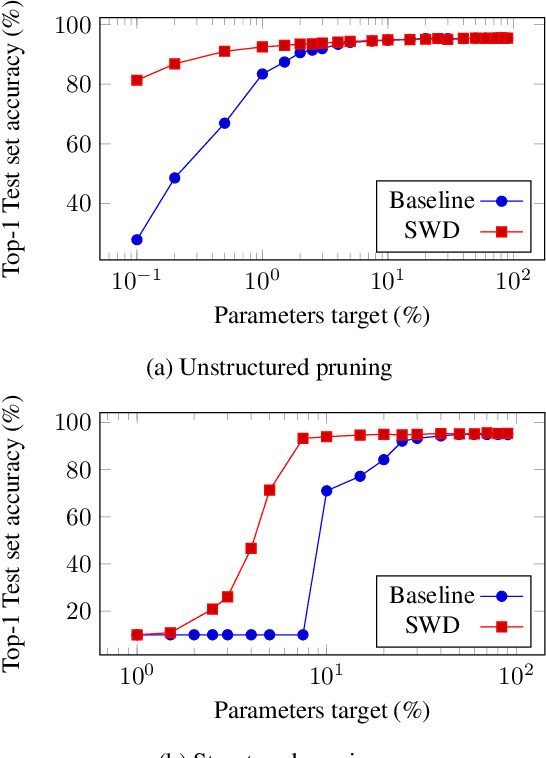
During the last decade, deep convolutional networks have become the reference for many machine learning tasks, especially in computer vision. However, large computational needs make them hard to deploy on resource-constrained hardware. Pruning has emerged as a standard way to compress such large networks. Yet, the severe perturbation caused by most pruning approaches is thought to hinder their efficacy. Drawing inspiration from Lagrangian Smoothing, we introduce a new technique, Selective Weight Decay (SWD), which achieves continuous pruning throughout training. Our theoretically-grounded approach is versatile and can be applied to any problem, network or pruning structure. We show that SWD compares favorably to other approaches in terms of performance/parameters ratio on the CIFAR-10 and ImageNet ILSVRC2012 datasets. On CIFAR-10 and unstructured pruning, for a target rate of 0.1% unpruned parameters, SWD attains a Top-1 accuracy of 81.32% while the reference method only reaches 27.78%. On CIFAR-10 and structured pruning, for a target rate of 2.5% unpruned parameters, the reference technique drops at 10% (random guess) while SWD maintains the Top-1 accuracy at 93.22%. On the ImageNet ILSVRC2012 dataset with unstructured pruning and the same target rate of 2.5%, SWD attains 84.6% Top-5 accuracy instead of the 77.07% reached by the reference.
Efficient Hardware Implementation of Incremental Learning and Inference on Chip
Nov 18, 2019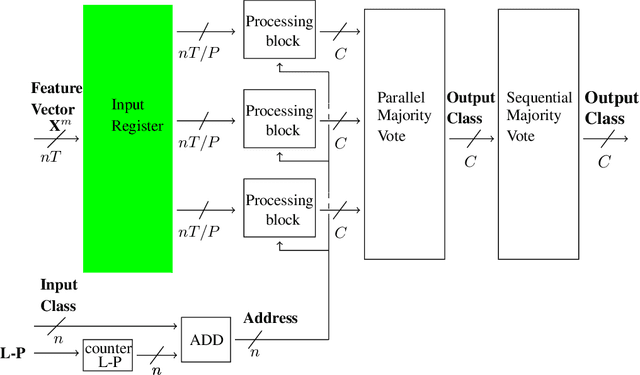
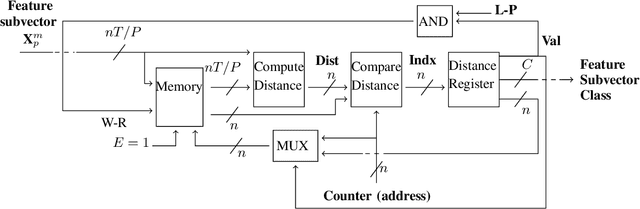
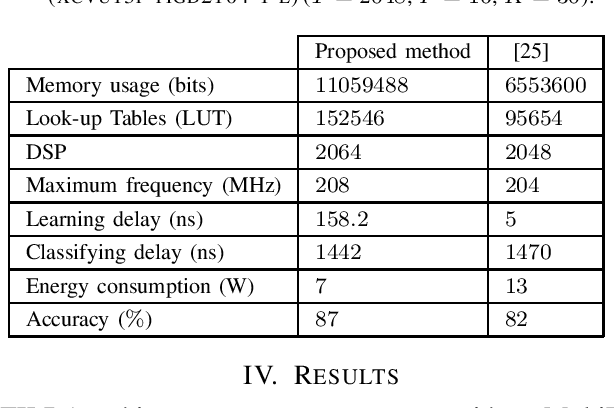
In this paper, we tackle the problem of incrementally learning a classifier, one example at a time, directly on chip. To this end, we propose an efficient hardware implementation of a recently introduced incremental learning procedure that achieves state-of-the-art performance by combining transfer learning with majority votes and quantization techniques. The proposed design is able to accommodate for both new examples and new classes directly on the chip. We detail the hardware implementation of the method (implemented on FPGA target) and show it requires limited resources while providing a significant acceleration compared to using a CPU.
Quantized Guided Pruning for Efficient Hardware Implementations of Convolutional Neural Networks
Dec 29, 2018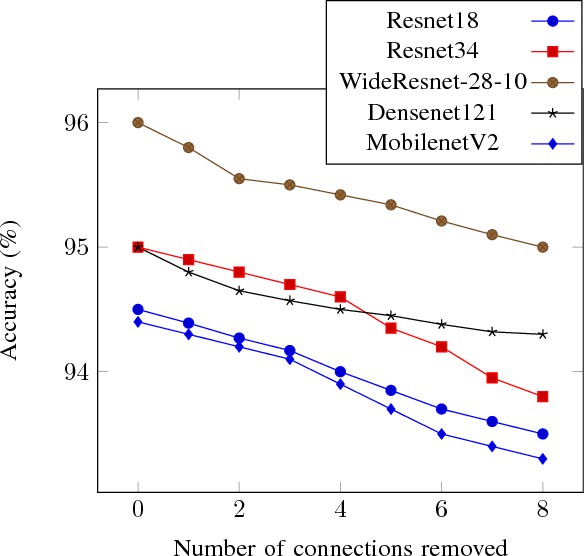
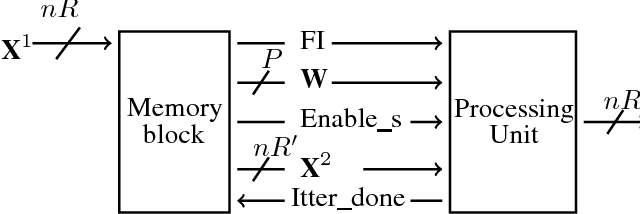
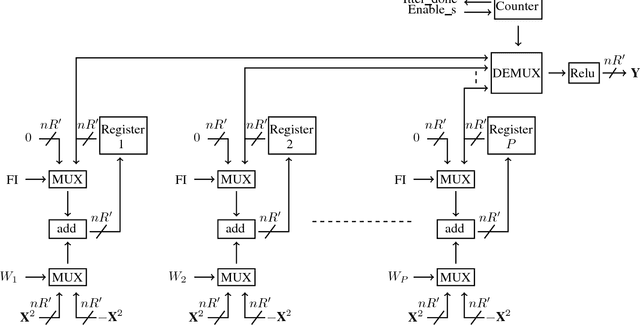
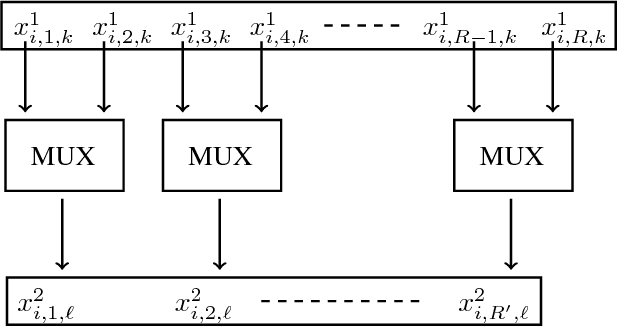
Convolutional Neural Networks (CNNs) are state-of-the-art in numerous computer vision tasks such as object classification and detection. However, the large amount of parameters they contain leads to a high computational complexity and strongly limits their usability in budget-constrained devices such as embedded devices. In this paper, we propose a combination of a new pruning technique and a quantization scheme that effectively reduce the complexity and memory usage of convolutional layers of CNNs, and replace the complex convolutional operation by a low-cost multiplexer. We perform experiments on the CIFAR10, CIFAR100 and SVHN and show that the proposed method achieves almost state-of-the-art accuracy, while drastically reducing the computational and memory footprints. We also propose an efficient hardware architecture to accelerate CNN operations. The proposed hardware architecture is a pipeline and accommodates multiple layers working at the same time to speed up the inference process.
Transfer Incremental Learning using Data Augmentation
Oct 04, 2018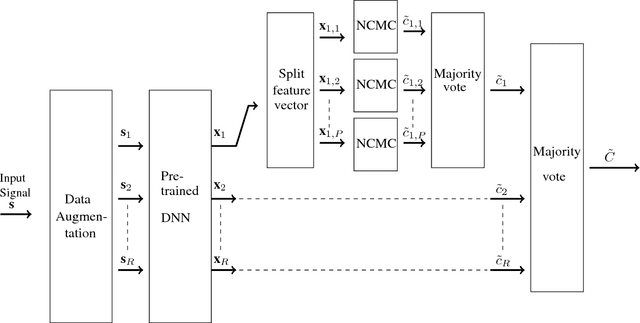
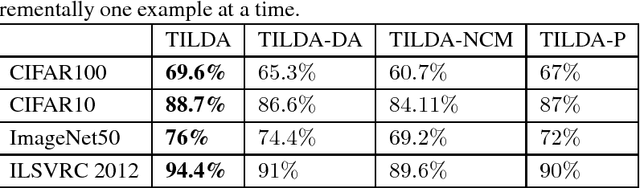
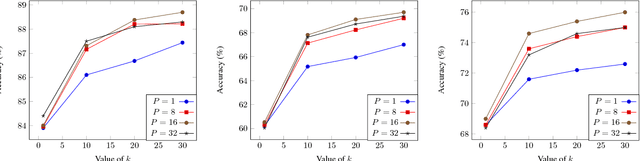
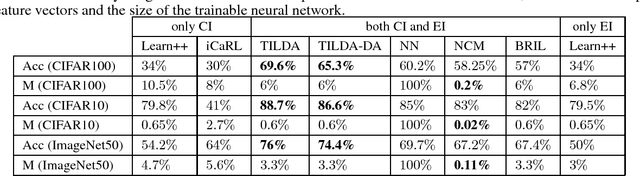
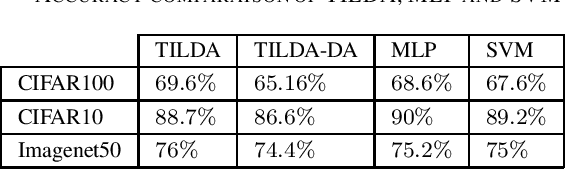
Deep learning-based methods have reached state of the art performances, relying on large quantity of available data and computational power. Such methods still remain highly inappropriate when facing a major open machine learning problem, which consists of learning incrementally new classes and examples over time. Combining the outstanding performances of Deep Neural Networks (DNNs) with the flexibility of incremental learning techniques is a promising venue of research. In this contribution, we introduce Transfer Incremental Learning using Data Augmentation (TILDA). TILDA is based on pre-trained DNNs as feature extractor, robust selection of feature vectors in subspaces using a nearest-class-mean based technique, majority votes and data augmentation at both the training and the prediction stages. Experiments on challenging vision datasets demonstrate the ability of the proposed method for low complexity incremental learning, while achieving significantly better accuracy than existing incremental counterparts.