 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Pruning of Deep Convolutional Networks Using Selective Weight Decay
Paper and Code
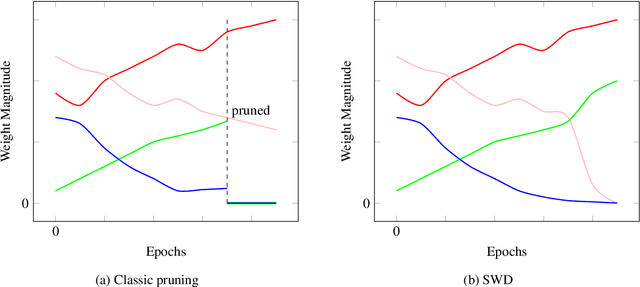
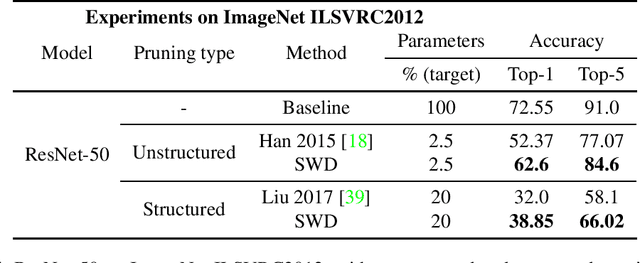
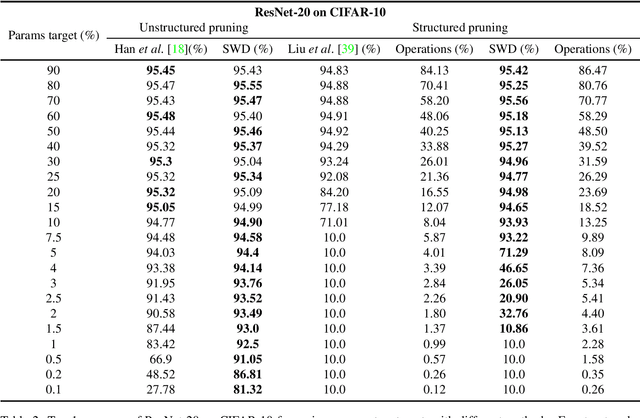
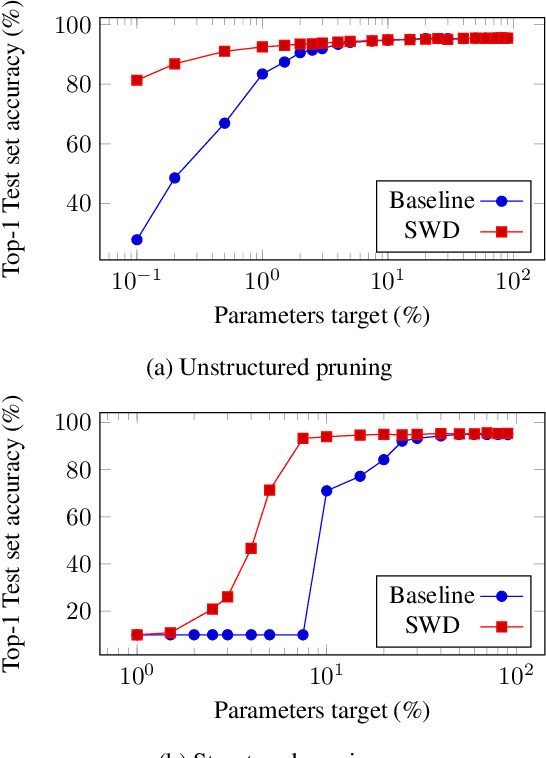
During the last decade, deep convolutional networks have become the reference for many machine learning tasks, especially in computer vision. However, large computational needs make them hard to deploy on resource-constrained hardware. Pruning has emerged as a standard way to compress such large networks. Yet, the severe perturbation caused by most pruning approaches is thought to hinder their efficacy. Drawing inspiration from Lagrangian Smoothing, we introduce a new technique, Selective Weight Decay (SWD), which achieves continuous pruning throughout training. Our theoretically-grounded approach is versatile and can be applied to any problem, network or pruning structure. We show that SWD compares favorably to other approaches in terms of performance/parameters ratio on the CIFAR-10 and ImageNet ILSVRC2012 datasets. On CIFAR-10 and unstructured pruning, for a target rate of 0.1% unpruned parameters, SWD attains a Top-1 accuracy of 81.32% while the reference method only reaches 27.78%. On CIFAR-10 and structured pruning, for a target rate of 2.5% unpruned parameters, the reference technique drops at 10% (random guess) while SWD maintains the Top-1 accuracy at 93.22%. On the ImageNet ILSVRC2012 dataset with unstructured pruning and the same target rate of 2.5%, SWD attains 84.6% Top-5 accuracy instead of the 77.07% reached by the reference.