 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Few-Shot Learning for Edge AI via Knowledge Distillation on MobileViT
Mar 27, 2026Efficient and adaptable deep learning models are an important area of deep learning research, driven by the need for highly efficient models on edge devices. Few-shot learning enables the use of deep learning models in low-data regimes, a capability that is highly sought after in real-world applications where collecting large annotated datasets is costly or impractical. This challenge is particularly relevant in edge scenarios, where connectivity may be limited, low-latency responses are required, or energy consumption constraints are critical. We propose and evaluate a pre-training method for the MobileViT backbone designed for edge computing. Specifically, we employ knowledge distillation, which transfers the generalization ability of a large-scale teacher model to a lightweight student model. This method achieves accuracy improvements of 14% and 6.7% for one-shot and five-shot classification, respectively, on the MiniImageNet benchmark, compared to the ResNet12 baseline, while reducing by 69% the number of parameters and by 88% the computational complexity of the model, in FLOPs. Furthermore, we deployed the proposed models on a Jetson Orin Nano platform and measured power consumption directly at the power supply, showing that the dynamic energy consumption is reduced by 37% with a latency of 2.6 ms. These results demonstrate that the proposed method is a promising and practical solution for deploying few-shot learning models on edge AI hardware.
MONET: Modeling and Optimization of neural NEtwork Training from Edge to Data Centers
Mar 16, 2026While hardware-software co-design has significantly improved the efficiency of neural network inference, modeling the training phase remains a critical yet underexplored challenge. Training workloads impose distinct constraints, particularly regarding memory footprint and backpropagation complexity, which existing inference-focused tools fail to capture. This paper introduces MONET, a framework designed to model the training of neural networks on heterogeneous dataflow accelerators. MONET builds upon Stream, an experimentally verified framework that that models the inference of neural networks on heterogeneous dataflow accelerators with layer fusion. Using MONET, we explore the design space of ResNet-18 and a small GPT-2, demonstrating the framework's capability to model training workflows and find better hardware architectures. We then further examine problems that become more complex in neural network training due to the larger design space, such as determining the best layer-fusion configuration. Additionally, we use our framework to find interesting trade-offs in activation checkpointing, with the help of a genetic algorithm. Our findings highlight the importance of a holistic approach to hardware-software co-design for scalable and efficient deep learning deployment.
Event Classification of Accelerometer Data for Industrial Package Monitoring with Embedded Deep Learning
Jun 05, 2025Package monitoring is an important topic in industrial applications, with significant implications for operational efficiency and ecological sustainability. In this study, we propose an approach that employs an embedded system, placed on reusable packages, to detect their state (on a Forklift, in a Truck, or in an undetermined location). We aim to design a system with a lifespan of several years, corresponding to the lifespan of reusable packages. Our analysis demonstrates that maximizing device lifespan requires minimizing wake time. We propose a pipeline that includes data processing, training, and evaluation of the deep learning model designed for imbalanced, multiclass time series data collected from an embedded sensor. The method uses a one-dimensional Convolutional Neural Network architecture to classify accelerometer data from the IoT device. Before training, two data augmentation techniques are tested to solve the imbalance problem of the dataset: the Synthetic Minority Oversampling TEchnique and the ADAptive SYNthetic sampling approach. After training, compression techniques are implemented to have a small model size. On the considered twoclass problem, the methodology yields a precision of 94.54% for the first class and 95.83% for the second class, while compression techniques reduce the model size by a factor of four. The trained model is deployed on the IoT device, where it operates with a power consumption of 316 mW during inference.
DeepGEMM: Accelerated Ultra Low-Precision Inference on CPU Architectures using Lookup Tables
Apr 18, 2023



A lot of recent progress has been made in ultra low-bit quantization, promising significant improvements in latency, memory footprint and energy consumption on edge devices. Quantization methods such as Learned Step Size Quantization can achieve model accuracy that is comparable to full-precision floating-point baselines even with sub-byte quantization. However, it is extremely challenging to deploy these ultra low-bit quantized models on mainstream CPU devices because commodity SIMD (Single Instruction, Multiple Data) hardware typically supports no less than 8-bit precision. To overcome this limitation, we propose DeepGEMM, a lookup table based approach for the execution of ultra low-precision convolutional neural networks on SIMD hardware. The proposed method precomputes all possible products of weights and activations, stores them in a lookup table, and efficiently accesses them at inference time to avoid costly multiply-accumulate operations. Our 2-bit implementation outperforms corresponding 8-bit integer kernels in the QNNPACK framework by up to 1.74x on x86 platforms.
Energy Consumption Analysis of pruned Semantic Segmentation Networks on an Embedded GPU
Jun 13, 2022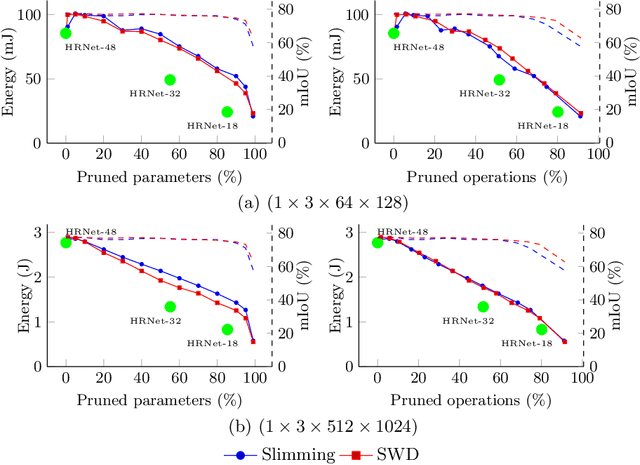
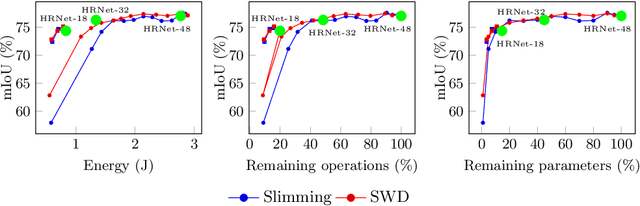
Deep neural networks are the state of the art in many computer vision tasks. Their deployment in the context of autonomous vehicles is of particular interest, since their limitations in terms of energy consumption prohibit the use of very large networks, that typically reach the best performance. A common method to reduce the complexity of these architectures, without sacrificing accuracy, is to rely on pruning, in which the least important portions are eliminated. There is a large literature on the subject, but interestingly few works have measured the actual impact of pruning on energy. In this work, we are interested in measuring it in the specific context of semantic segmentation for autonomous driving, using the Cityscapes dataset. To this end, we analyze the impact of recently proposed structured pruning methods when trained architectures are deployed on a Jetson Xavier embedded GPU.
Leveraging Structured Pruning of Convolutional Neural Networks
Jun 13, 2022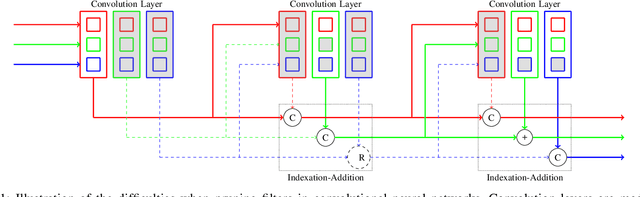
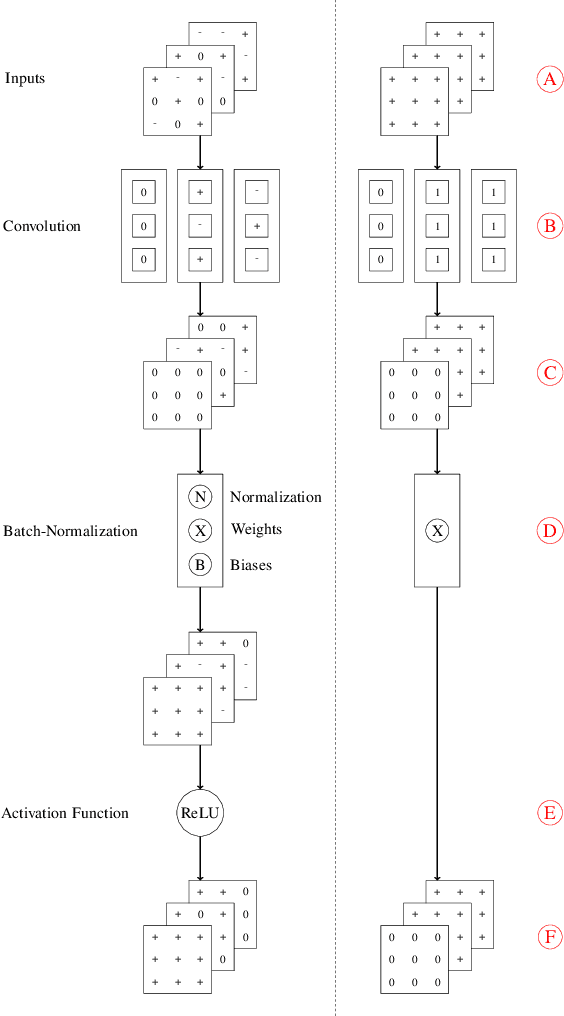
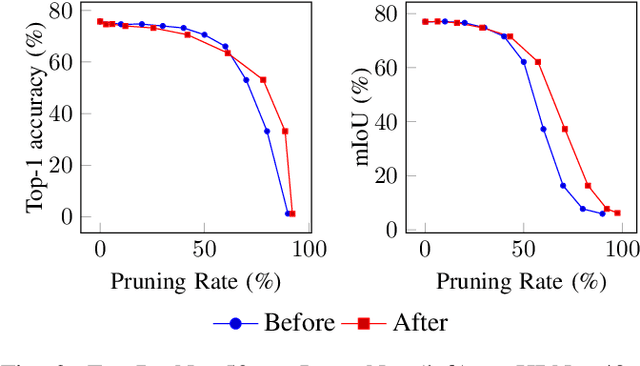
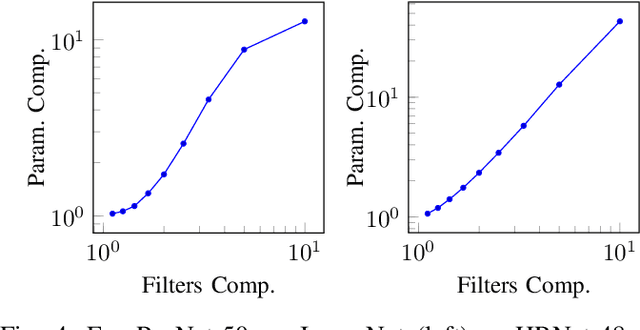
Structured pruning is a popular method to reduce the cost of convolutional neural networks, that are the state of the art in many computer vision tasks. However, depending on the architecture, pruning introduces dimensional discrepancies which prevent the actual reduction of pruned networks. To tackle this problem, we propose a method that is able to take any structured pruning mask and generate a network that does not encounter any of these problems and can be leveraged efficiently. We provide an accurate description of our solution and show results of gains, in energy consumption and inference time on embedded hardware, of pruned convolutional neural networks.
Using Deep Neural Networks to Predict and Improve the Performance of Polar Codes
May 11, 2021



Polar codes can theoretically achieve very competitive Frame Error Rates. In practice, their performance may depend on the chosen decoding procedure, as well as other parameters of the communication system they are deployed upon. As a consequence, designing efficient polar codes for a specific context can quickly become challenging. In this paper, we introduce a methodology that consists in training deep neural networks to predict the frame error rate of polar codes based on their frozen bit construction sequence. We introduce an algorithm based on Projected Gradient Descent that leverages the gradient of the neural network function to generate promising frozen bit sequences. We showcase on generated datasets the ability of the proposed methodology to produce codes more efficient than those used to train the neural networks, even when the latter are selected among the most efficient ones.
Continuous Pruning of Deep Convolutional Networks Using Selective Weight Decay
Dec 22, 2020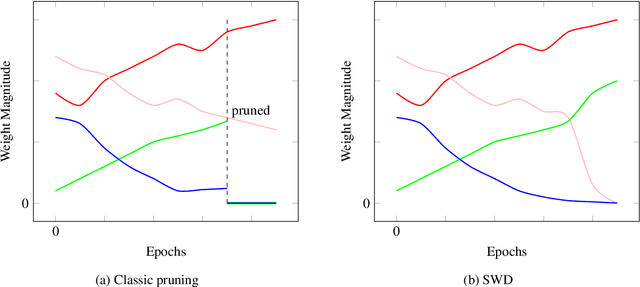
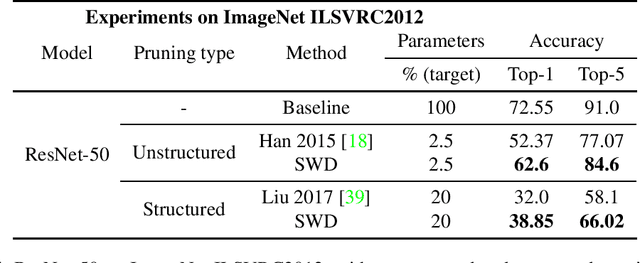
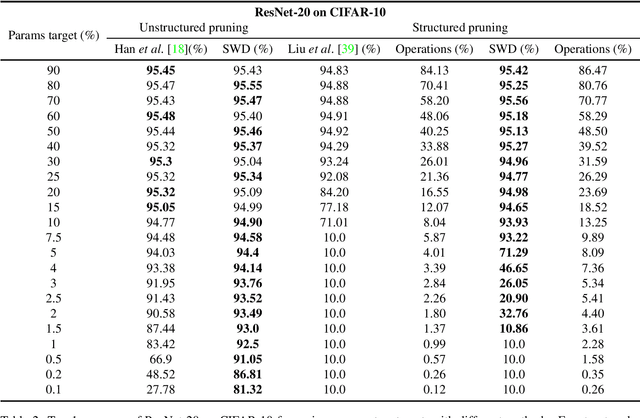
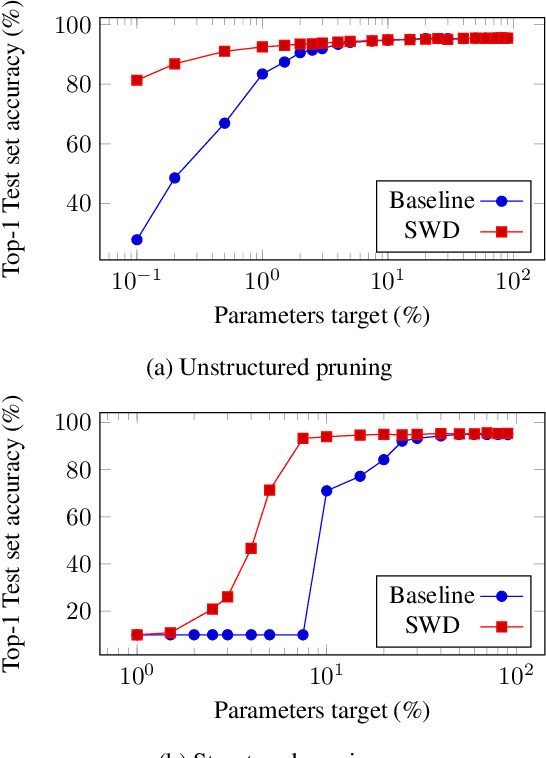
During the last decade, deep convolutional networks have become the reference for many machine learning tasks, especially in computer vision. However, large computational needs make them hard to deploy on resource-constrained hardware. Pruning has emerged as a standard way to compress such large networks. Yet, the severe perturbation caused by most pruning approaches is thought to hinder their efficacy. Drawing inspiration from Lagrangian Smoothing, we introduce a new technique, Selective Weight Decay (SWD), which achieves continuous pruning throughout training. Our theoretically-grounded approach is versatile and can be applied to any problem, network or pruning structure. We show that SWD compares favorably to other approaches in terms of performance/parameters ratio on the CIFAR-10 and ImageNet ILSVRC2012 datasets. On CIFAR-10 and unstructured pruning, for a target rate of 0.1% unpruned parameters, SWD attains a Top-1 accuracy of 81.32% while the reference method only reaches 27.78%. On CIFAR-10 and structured pruning, for a target rate of 2.5% unpruned parameters, the reference technique drops at 10% (random guess) while SWD maintains the Top-1 accuracy at 93.22%. On the ImageNet ILSVRC2012 dataset with unstructured pruning and the same target rate of 2.5%, SWD attains 84.6% Top-5 accuracy instead of the 77.07% reached by the reference.