 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepliteRT: Computer Vision at the Edge
Sep 19, 2023
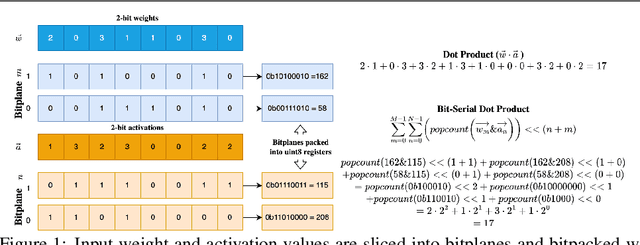
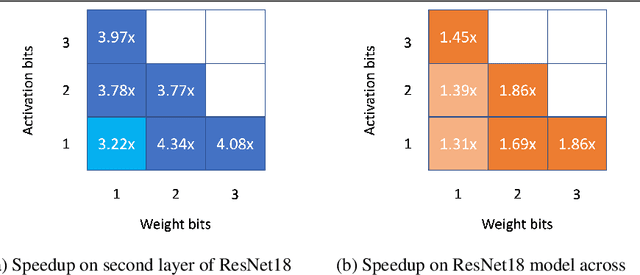
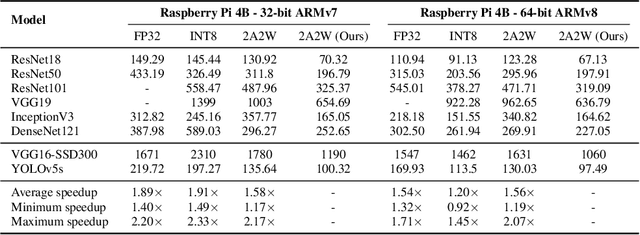
The proliferation of edge devices has unlocked unprecedented opportunities for deep learning model deployment in computer vision applications. However, these complex models require considerable power, memory and compute resources that are typically not available on edge platforms. Ultra low-bit quantization presents an attractive solution to this problem by scaling down the model weights and activations from 32-bit to less than 8-bit. We implement highly optimized ultra low-bit convolution operators for ARM-based targets that outperform existing methods by up to 4.34x. Our operator is implemented within Deeplite Runtime (DeepliteRT), an end-to-end solution for the compilation, tuning, and inference of ultra low-bit models on ARM devices. Compiler passes in DeepliteRT automatically convert a fake-quantized model in full precision to a compact ultra low-bit representation, easing the process of quantized model deployment on commodity hardware. We analyze the performance of DeepliteRT on classification and detection models against optimized 32-bit floating-point, 8-bit integer, and 2-bit baselines, achieving significant speedups of up to 2.20x, 2.33x and 2.17x, respectively.
DeepGEMM: Accelerated Ultra Low-Precision Inference on CPU Architectures using Lookup Tables
Apr 18, 2023



A lot of recent progress has been made in ultra low-bit quantization, promising significant improvements in latency, memory footprint and energy consumption on edge devices. Quantization methods such as Learned Step Size Quantization can achieve model accuracy that is comparable to full-precision floating-point baselines even with sub-byte quantization. However, it is extremely challenging to deploy these ultra low-bit quantized models on mainstream CPU devices because commodity SIMD (Single Instruction, Multiple Data) hardware typically supports no less than 8-bit precision. To overcome this limitation, we propose DeepGEMM, a lookup table based approach for the execution of ultra low-precision convolutional neural networks on SIMD hardware. The proposed method precomputes all possible products of weights and activations, stores them in a lookup table, and efficiently accesses them at inference time to avoid costly multiply-accumulate operations. Our 2-bit implementation outperforms corresponding 8-bit integer kernels in the QNNPACK framework by up to 1.74x on x86 platforms.
Accelerating Deep Learning Model Inference on Arm CPUs with Ultra-Low Bit Quantization and Runtime
Jul 18, 2022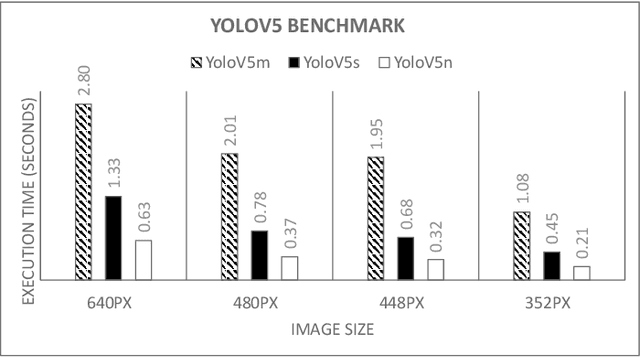
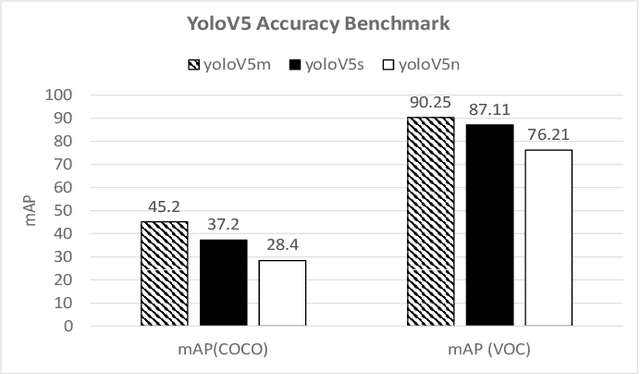
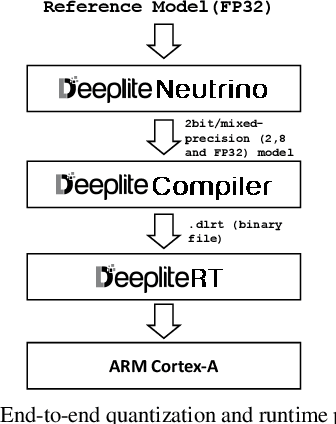
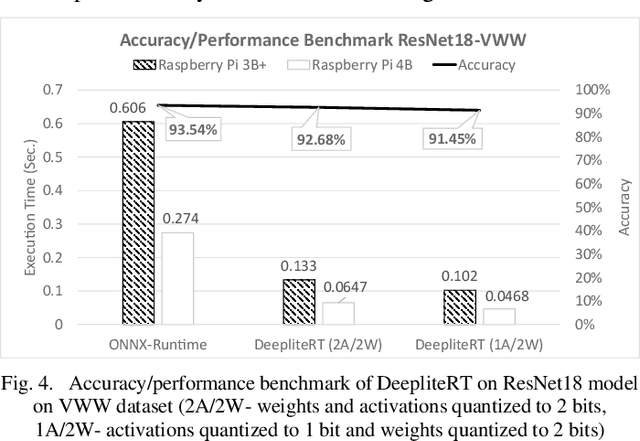
Deep Learning has been one of the most disruptive technological advancements in recent times. The high performance of deep learning models comes at the expense of high computational, storage and power requirements. Sensing the immediate need for accelerating and compressing these models to improve on-device performance, we introduce Deeplite Neutrino for production-ready optimization of the models and Deeplite Runtime for deployment of ultra-low bit quantized models on Arm-based platforms. We implement low-level quantization kernels for Armv7 and Armv8 architectures enabling deployment on the vast array of 32-bit and 64-bit Arm-based devices. With efficient implementations using vectorization, parallelization, and tiling, we realize speedups of up to 2x and 2.2x compared to TensorFlow Lite with XNNPACK backend on classification and detection models, respectively. We also achieve significant speedups of up to 5x and 3.2x compared to ONNX Runtime for classification and detection models, respectively.