 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Deep Learning Model Inference on Arm CPUs with Ultra-Low Bit Quantization and Runtime
Paper and Code
Jul 18, 2022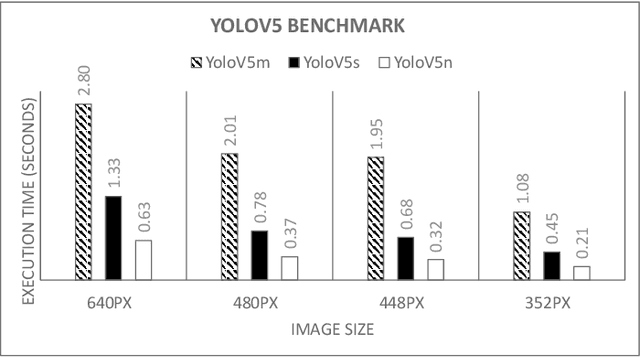
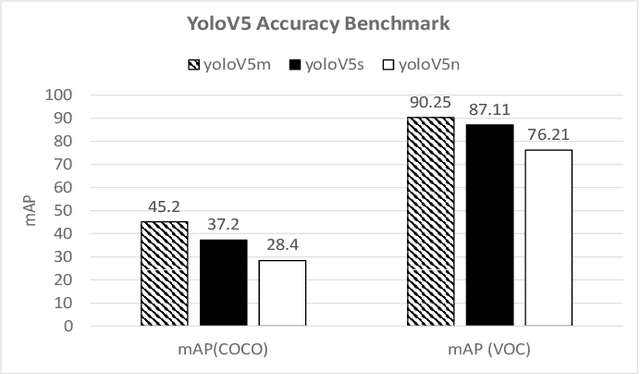
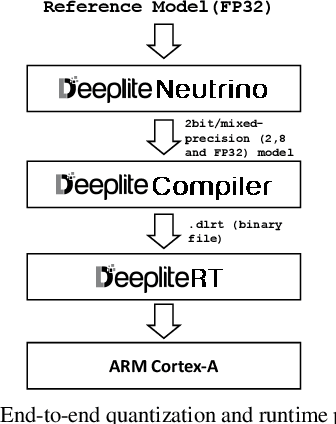
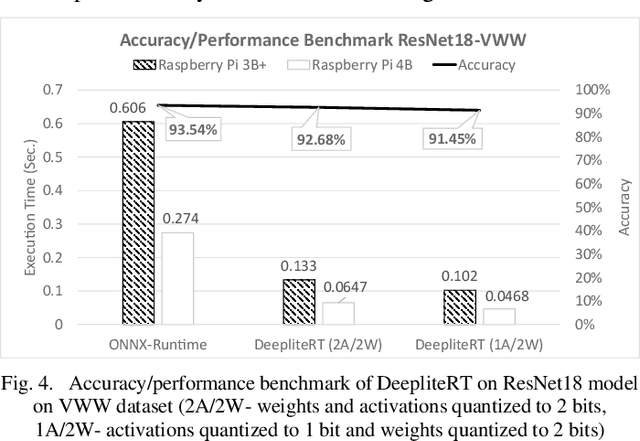
Deep Learning has been one of the most disruptive technological advancements in recent times. The high performance of deep learning models comes at the expense of high computational, storage and power requirements. Sensing the immediate need for accelerating and compressing these models to improve on-device performance, we introduce Deeplite Neutrino for production-ready optimization of the models and Deeplite Runtime for deployment of ultra-low bit quantized models on Arm-based platforms. We implement low-level quantization kernels for Armv7 and Armv8 architectures enabling deployment on the vast array of 32-bit and 64-bit Arm-based devices. With efficient implementations using vectorization, parallelization, and tiling, we realize speedups of up to 2x and 2.2x compared to TensorFlow Lite with XNNPACK backend on classification and detection models, respectively. We also achieve significant speedups of up to 5x and 3.2x compared to ONNX Runtime for classification and detection models, respectively.