 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Deep Learning Model Inference on Arm CPUs with Ultra-Low Bit Quantization and Runtime
Jul 18, 2022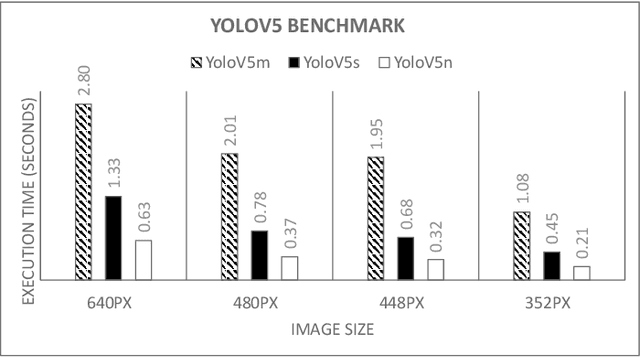
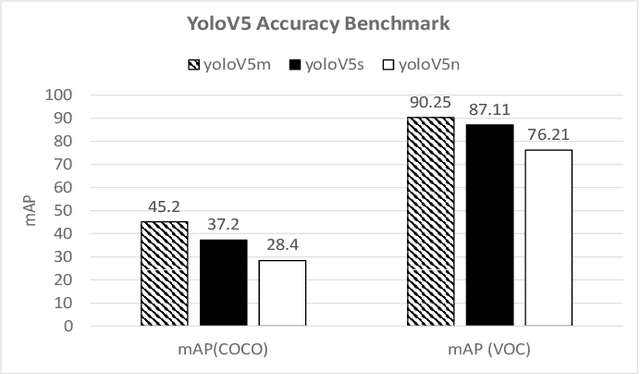
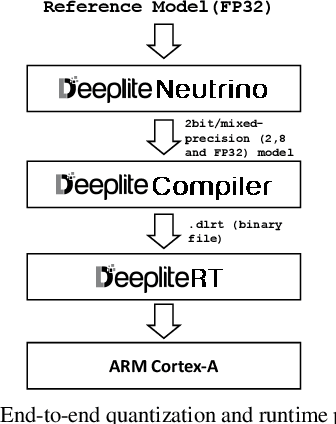
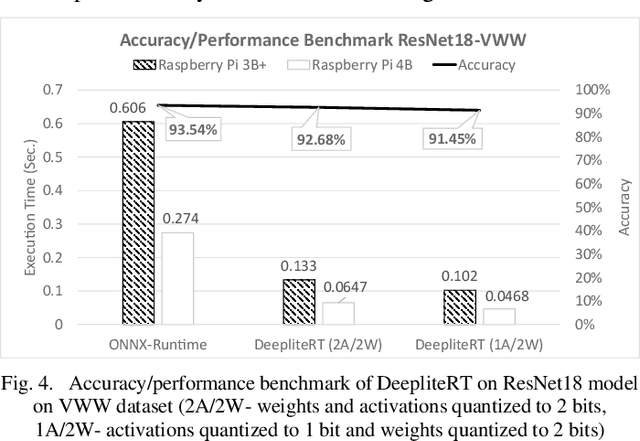
Deep Learning has been one of the most disruptive technological advancements in recent times. The high performance of deep learning models comes at the expense of high computational, storage and power requirements. Sensing the immediate need for accelerating and compressing these models to improve on-device performance, we introduce Deeplite Neutrino for production-ready optimization of the models and Deeplite Runtime for deployment of ultra-low bit quantized models on Arm-based platforms. We implement low-level quantization kernels for Armv7 and Armv8 architectures enabling deployment on the vast array of 32-bit and 64-bit Arm-based devices. With efficient implementations using vectorization, parallelization, and tiling, we realize speedups of up to 2x and 2.2x compared to TensorFlow Lite with XNNPACK backend on classification and detection models, respectively. We also achieve significant speedups of up to 5x and 3.2x compared to ONNX Runtime for classification and detection models, respectively.
QReg: On Regularization Effects of Quantization
Jun 27, 2022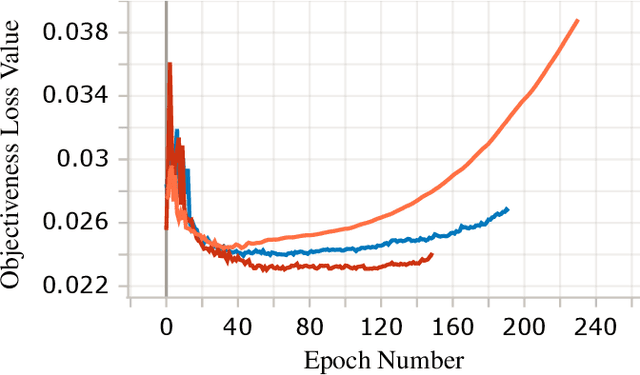
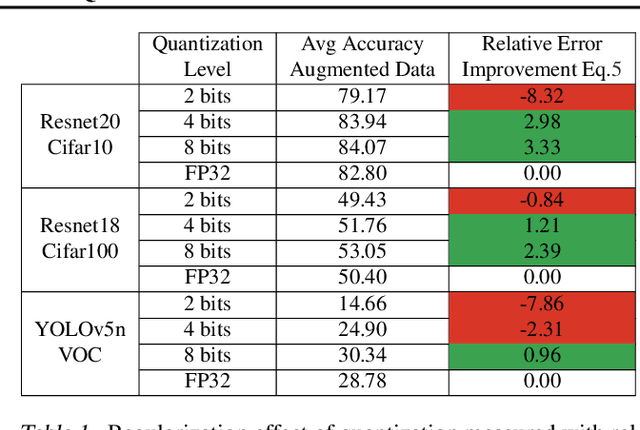
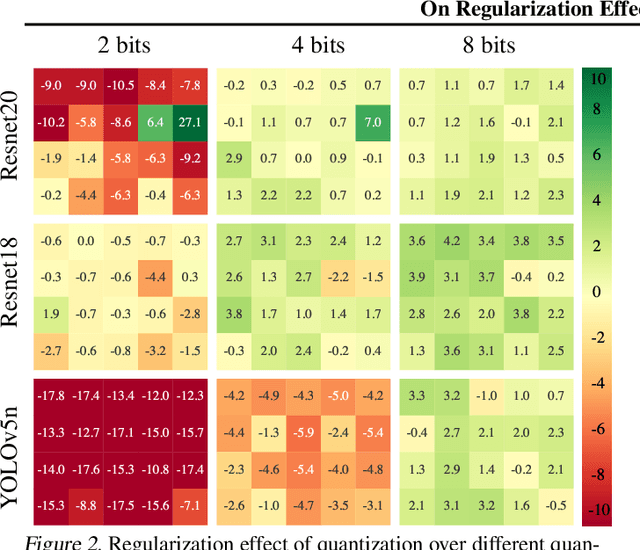
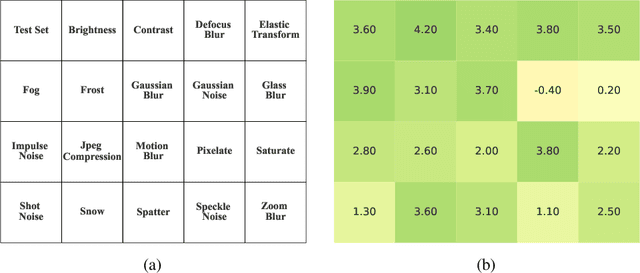
In this paper we study the effects of quantization in DNN training. We hypothesize that weight quantization is a form of regularization and the amount of regularization is correlated with the quantization level (precision). We confirm our hypothesis by providing analytical study and empirical results. By modeling weight quantization as a form of additive noise to weights, we explore how this noise propagates through the network at training time. We then show that the magnitude of this noise is correlated with the level of quantization. To confirm our analytical study, we performed an extensive list of experiments summarized in this paper in which we show that the regularization effects of quantization can be seen in various vision tasks and models, over various datasets. Based on our study, we propose that 8-bit quantization provides a reliable form of regularization in different vision tasks and models.
On Causal Inference for Data-free Structured Pruning
Dec 19, 2021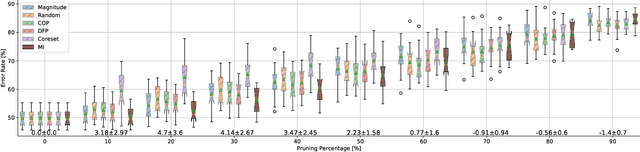
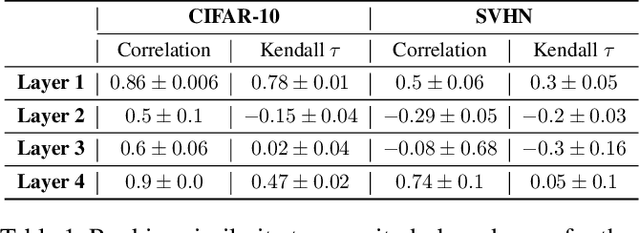
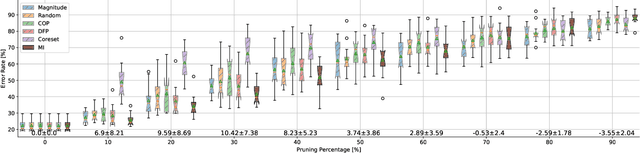

Neural networks (NNs) are making a large impact both on research and industry. Nevertheless, as NNs' accuracy increases, it is followed by an expansion in their size, required number of compute operations and energy consumption. Increase in resource consumption results in NNs' reduced adoption rate and real-world deployment impracticality. Therefore, NNs need to be compressed to make them available to a wider audience and at the same time decrease their runtime costs. In this work, we approach this challenge from a causal inference perspective, and we propose a scoring mechanism to facilitate structured pruning of NNs. The approach is based on measuring mutual information under a maximum entropy perturbation, sequentially propagated through the NN. We demonstrate the method's performance on two datasets and various NNs' sizes, and we show that our approach achieves competitive performance under challenging conditions.
Deeplite Neutrino: An End-to-End Framework for Constrained Deep Learning Model Optimization
Jan 13, 2021
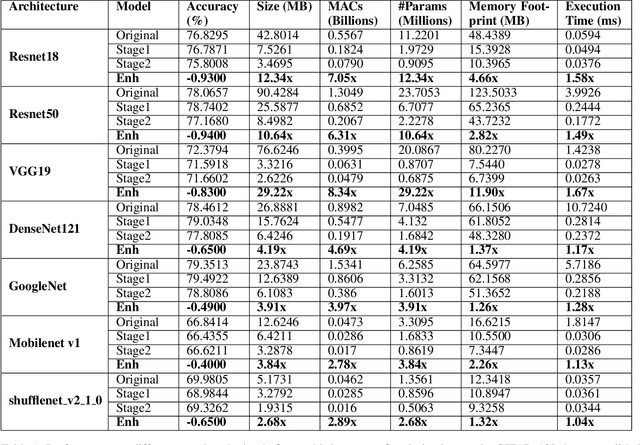
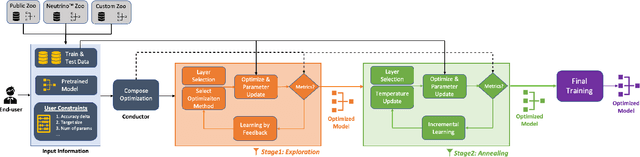
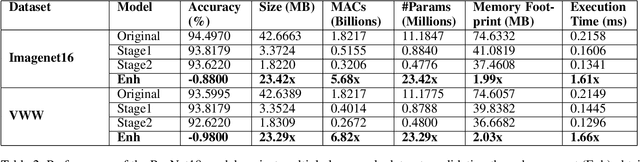
Designing deep learning-based solutions is becoming a race for training deeper models with a greater number of layers. While a large-size deeper model could provide competitive accuracy, it creates a lot of logistical challenges and unreasonable resource requirements during development and deployment. This has been one of the key reasons for deep learning models not being excessively used in various production environments, especially in edge devices. There is an immediate requirement for optimizing and compressing these deep learning models, to enable on-device intelligence. In this research, we introduce a black-box framework, Deeplite Neutrino for production-ready optimization of deep learning models. The framework provides an easy mechanism for the end-users to provide constraints such as a tolerable drop in accuracy or target size of the optimized models, to guide the whole optimization process. The framework is easy to include in an existing production pipeline and is available as a Python Package, supporting PyTorch and Tensorflow libraries. The optimization performance of the framework is shown across multiple benchmark datasets and popular deep learning models. Further, the framework is currently used in production and the results and testimonials from several clients are summarized.
Hierarchical Adversarially Learned Inference
Feb 04, 2018
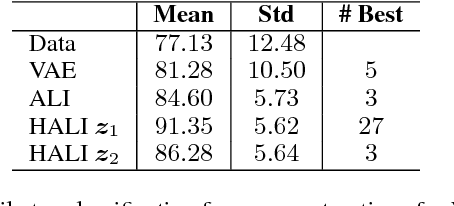

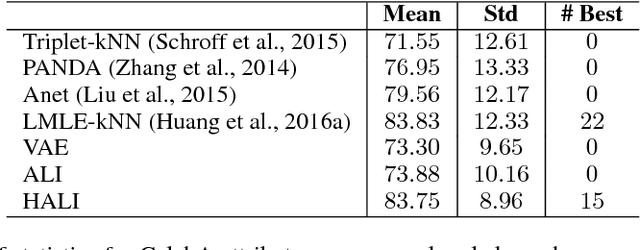
We propose a novel hierarchical generative model with a simple Markovian structure and a corresponding inference model. Both the generative and inference model are trained using the adversarial learning paradigm. We demonstrate that the hierarchical structure supports the learning of progressively more abstract representations as well as providing semantically meaningful reconstructions with different levels of fidelity. Furthermore, we show that minimizing the Jensen-Shanon divergence between the generative and inference network is enough to minimize the reconstruction error. The resulting semantically meaningful hierarchical latent structure discovery is exemplified on the CelebA dataset. There, we show that the features learned by our model in an unsupervised way outperform the best handcrafted features. Furthermore, the extracted features remain competitive when compared to several recent deep supervised approaches on an attribute prediction task on CelebA. Finally, we leverage the model's inference network to achieve state-of-the-art performance on a semi-supervised variant of the MNIST digit classification task.
Adversarially Learned Inference
Feb 21, 2017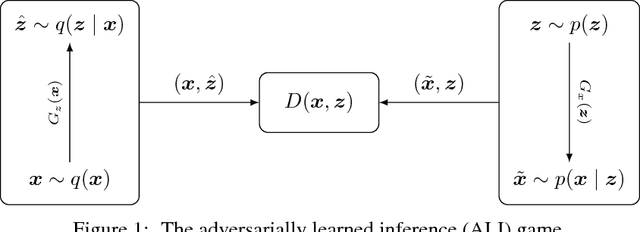
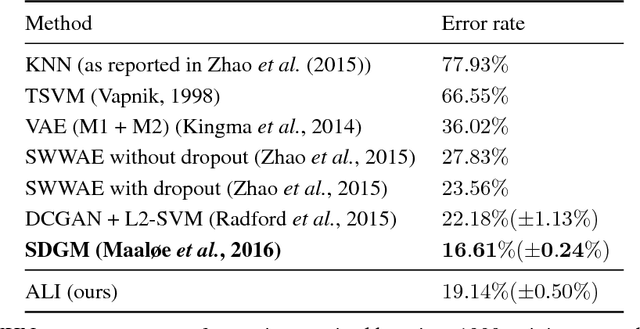

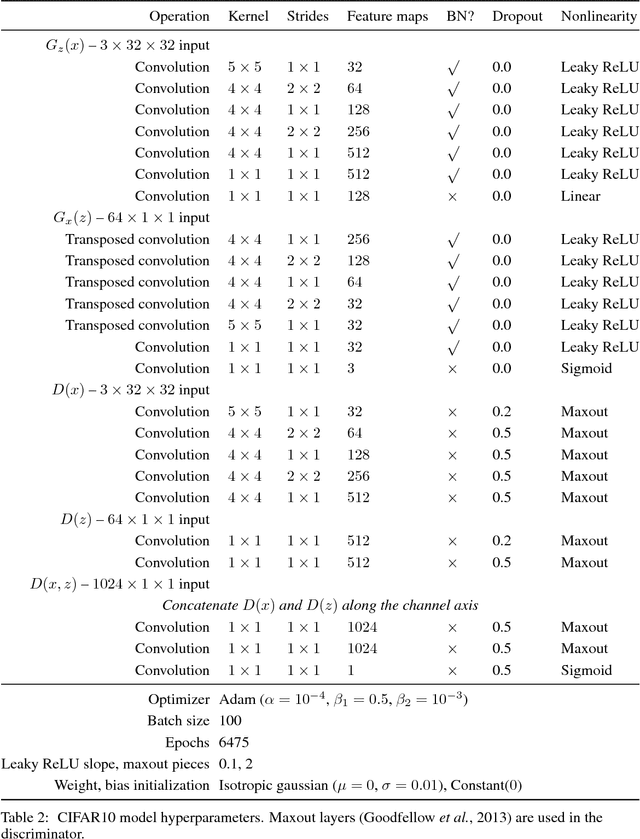
We introduce the adversarially learned inference (ALI) model, which jointly learns a generation network and an inference network using an adversarial process. The generation network maps samples from stochastic latent variables to the data space while the inference network maps training examples in data space to the space of latent variables. An adversarial game is cast between these two networks and a discriminative network is trained to distinguish between joint latent/data-space samples from the generative network and joint samples from the inference network. We illustrate the ability of the model to learn mutually coherent inference and generation networks through the inspections of model samples and reconstructions and confirm the usefulness of the learned representations by obtaining a performance competitive with state-of-the-art on the semi-supervised SVHN and CIFAR10 tasks.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016
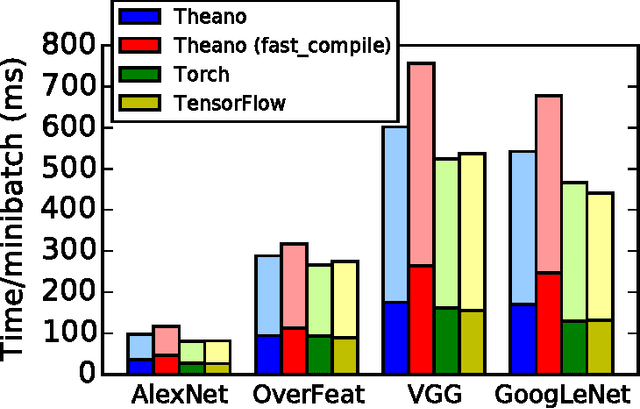
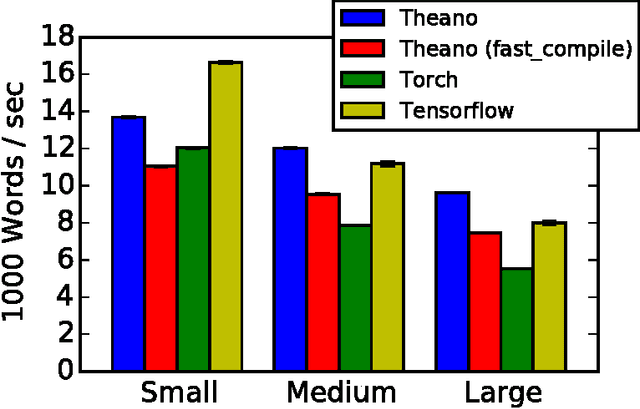
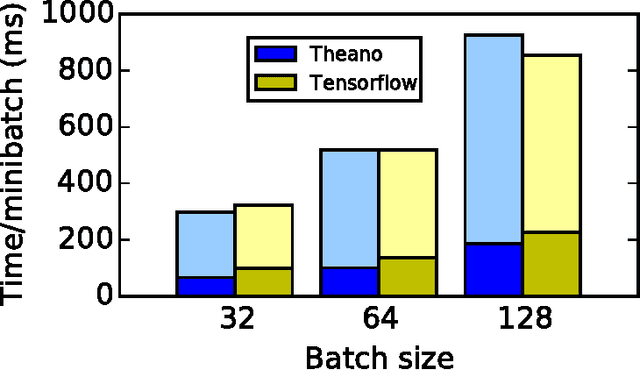
Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.