 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws of Motion Forecasting and Planning -- A Technical Report
Jun 09, 2025We study the empirical scaling laws of a family of encoder-decoder autoregressive transformer models on the task of joint motion forecasting and planning in the autonomous driving domain. Using a 500 thousand hours driving dataset, we demonstrate that, similar to language modeling, model performance improves as a power-law function of the total compute budget, and we observe a strong correlation between model training loss and model evaluation metrics. Most interestingly, closed-loop metrics also improve with scaling, which has important implications for the suitability of open-loop metrics for model development and hill climbing. We also study the optimal scaling of the number of transformer parameters and the training data size for a training compute-optimal model. We find that as the training compute budget grows, optimal scaling requires increasing the model size 1.5x as fast as the dataset size. We also study inference-time compute scaling, where we observe that sampling and clustering the output of smaller models makes them competitive with larger models, up to a crossover point beyond which a larger models becomes more inference-compute efficient. Overall, our experimental results demonstrate that optimizing the training and inference-time scaling properties of motion forecasting and planning models is a key lever for improving their performance to address a wide variety of driving scenarios. Finally, we briefly study the utility of training on general logged driving data of other agents to improve the performance of the ego-agent, an important research area to address the scarcity of robotics data for large capacity models training.
MoST: Multi-modality Scene Tokenization for Motion Prediction
Apr 30, 2024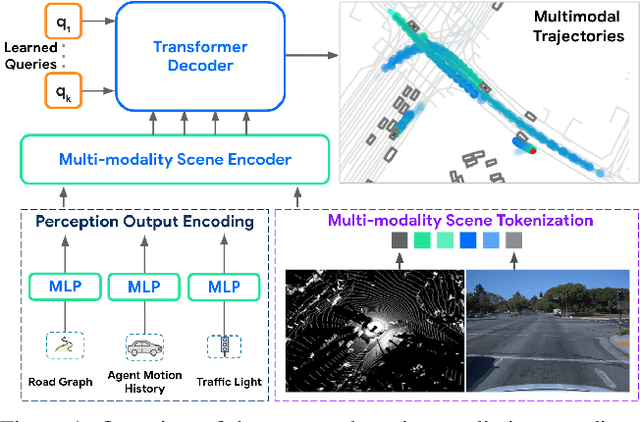

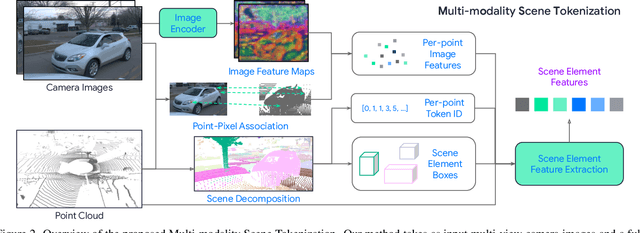
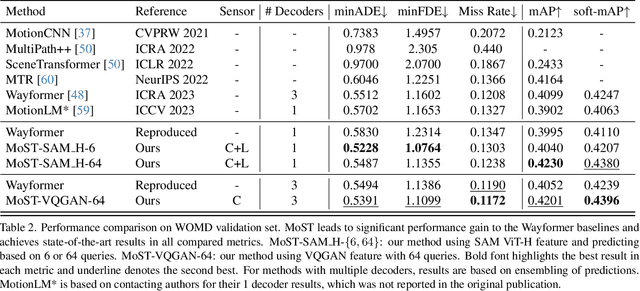
Many existing motion prediction approaches rely on symbolic perception outputs to generate agent trajectories, such as bounding boxes, road graph information and traffic lights. This symbolic representation is a high-level abstraction of the real world, which may render the motion prediction model vulnerable to perception errors (e.g., failures in detecting open-vocabulary obstacles) while missing salient information from the scene context (e.g., poor road conditions). An alternative paradigm is end-to-end learning from raw sensors. However, this approach suffers from the lack of interpretability and requires significantly more training resources. In this work, we propose tokenizing the visual world into a compact set of scene elements and then leveraging pre-trained image foundation models and LiDAR neural networks to encode all the scene elements in an open-vocabulary manner. The image foundation model enables our scene tokens to encode the general knowledge of the open world while the LiDAR neural network encodes geometry information. Our proposed representation can efficiently encode the multi-frame multi-modality observations with a few hundred tokens and is compatible with most transformer-based architectures. To evaluate our method, we have augmented Waymo Open Motion Dataset with camera embeddings. Experiments over Waymo Open Motion Dataset show that our approach leads to significant performance improvements over the state-of-the-art.
Scaling Motion Forecasting Models with Ensemble Distillation
Apr 05, 2024



Motion forecasting has become an increasingly critical component of autonomous robotic systems. Onboard compute budgets typically limit the accuracy of real-time systems. In this work we propose methods of improving motion forecasting systems subject to limited compute budgets by combining model ensemble and distillation techniques. The use of ensembles of deep neural networks has been shown to improve generalization accuracy in many application domains. We first demonstrate significant performance gains by creating a large ensemble of optimized single models. We then develop a generalized framework to distill motion forecasting model ensembles into small student models which retain high performance with a fraction of the computing cost. For this study we focus on the task of motion forecasting using real world data from autonomous driving systems. We develop ensemble models that are very competitive on the Waymo Open Motion Dataset (WOMD) and Argoverse leaderboards. From these ensembles, we train distilled student models which have high performance at a fraction of the compute costs. These experiments demonstrate distillation from ensembles as an effective method for improving accuracy of predictive models for robotic systems with limited compute budgets.
Let Your Graph Do the Talking: Encoding Structured Data for LLMs
Feb 08, 2024How can we best encode structured data into sequential form for use in large language models (LLMs)? In this work, we introduce a parameter-efficient method to explicitly represent structured data for LLMs. Our method, GraphToken, learns an encoding function to extend prompts with explicit structured information. Unlike other work which focuses on limited domains (e.g. knowledge graph representation), our work is the first effort focused on the general encoding of structured data to be used for various reasoning tasks. We show that explicitly representing the graph structure allows significant improvements to graph reasoning tasks. Specifically, we see across the board improvements - up to 73% points - on node, edge and, graph-level tasks from the GraphQA benchmark.
MotionLM: Multi-Agent Motion Forecasting as Language Modeling
Sep 28, 2023Reliable forecasting of the future behavior of road agents is a critical component to safe planning in autonomous vehicles. Here, we represent continuous trajectories as sequences of discrete motion tokens and cast multi-agent motion prediction as a language modeling task over this domain. Our model, MotionLM, provides several advantages: First, it does not require anchors or explicit latent variable optimization to learn multimodal distributions. Instead, we leverage a single standard language modeling objective, maximizing the average log probability over sequence tokens. Second, our approach bypasses post-hoc interaction heuristics where individual agent trajectory generation is conducted prior to interactive scoring. Instead, MotionLM produces joint distributions over interactive agent futures in a single autoregressive decoding process. In addition, the model's sequential factorization enables temporally causal conditional rollouts. The proposed approach establishes new state-of-the-art performance for multi-agent motion prediction on the Waymo Open Motion Dataset, ranking 1st on the interactive challenge leaderboard.
Fine-Tashkeel: Finetuning Byte-Level Models for Accurate Arabic Text Diacritization
Mar 25, 2023Most of previous work on learning diacritization of the Arabic language relied on training models from scratch. In this paper, we investigate how to leverage pre-trained language models to learn diacritization. We finetune token-free pre-trained multilingual models (ByT5) to learn to predict and insert missing diacritics in Arabic text, a complex task that requires understanding the sentence semantics and the morphological structure of the tokens. We show that we can achieve state-of-the-art on the diacritization task with minimal amount of training and no feature engineering, reducing WER by 40%. We release our finetuned models for the greater benefit of the researchers in the community.
Wayformer: Motion Forecasting via Simple & Efficient Attention Networks
Jul 12, 2022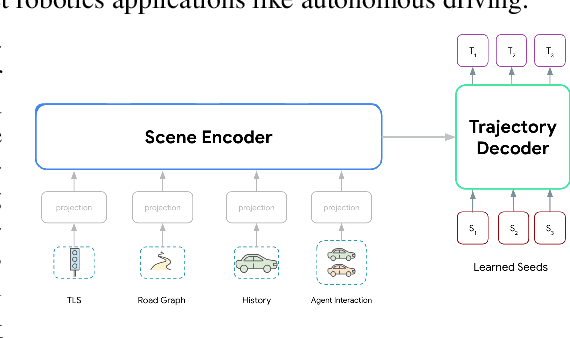
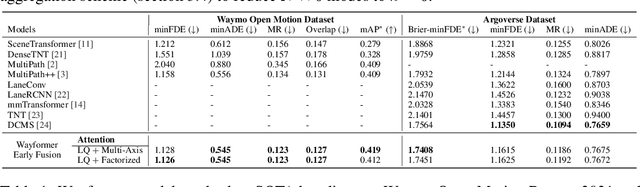
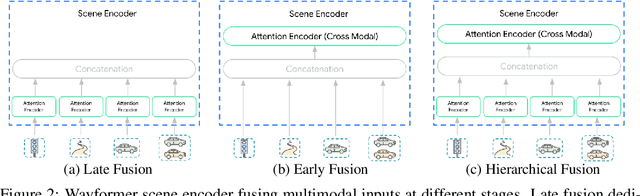
Motion forecasting for autonomous driving is a challenging task because complex driving scenarios result in a heterogeneous mix of static and dynamic inputs. It is an open problem how best to represent and fuse information about road geometry, lane connectivity, time-varying traffic light state, and history of a dynamic set of agents and their interactions into an effective encoding. To model this diverse set of input features, many approaches proposed to design an equally complex system with a diverse set of modality specific modules. This results in systems that are difficult to scale, extend, or tune in rigorous ways to trade off quality and efficiency. In this paper, we present Wayformer, a family of attention based architectures for motion forecasting that are simple and homogeneous. Wayformer offers a compact model description consisting of an attention based scene encoder and a decoder. In the scene encoder we study the choice of early, late and hierarchical fusion of the input modalities. For each fusion type we explore strategies to tradeoff efficiency and quality via factorized attention or latent query attention. We show that early fusion, despite its simplicity of construction, is not only modality agnostic but also achieves state-of-the-art results on both Waymo Open MotionDataset (WOMD) and Argoverse leaderboards, demonstrating the effectiveness of our design philosophy
Narrowing the Coordinate-frame Gap in Behavior Prediction Models: Distillation for Efficient and Accurate Scene-centric Motion Forecasting
Jun 10, 2022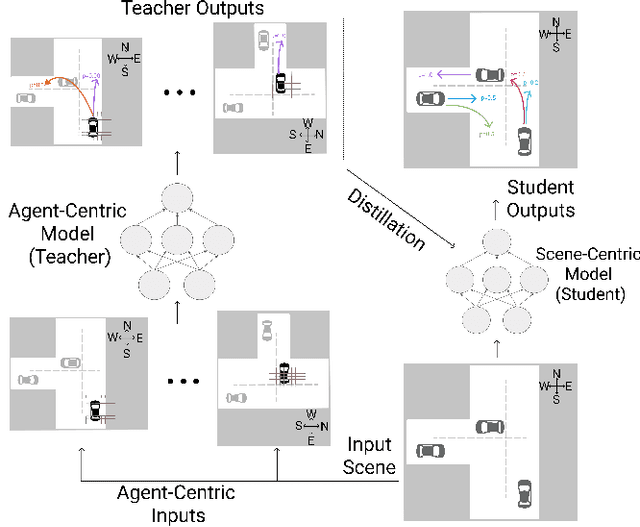
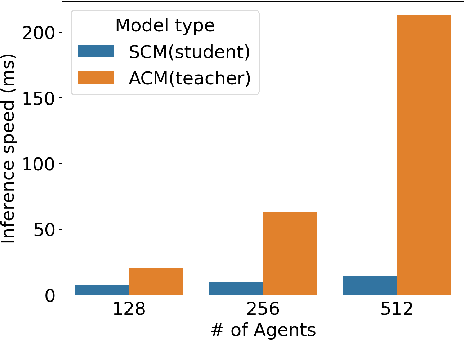
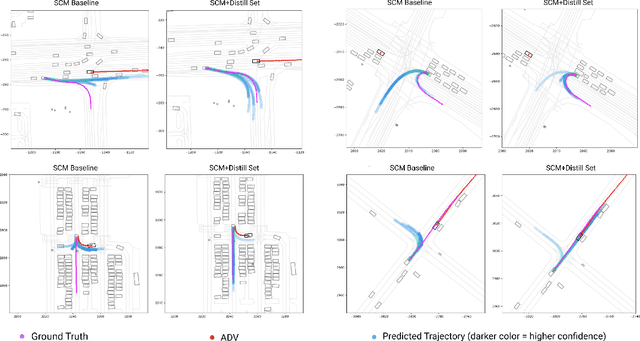
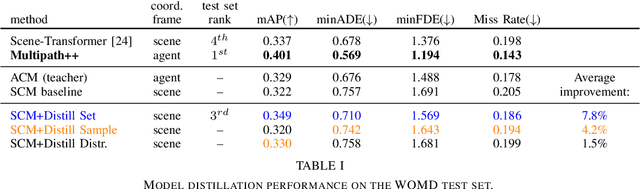
Behavior prediction models have proliferated in recent years, especially in the popular real-world robotics application of autonomous driving, where representing the distribution over possible futures of moving agents is essential for safe and comfortable motion planning. In these models, the choice of coordinate frames to represent inputs and outputs has crucial trade offs which broadly fall into one of two categories. Agent-centric models transform inputs and perform inference in agent-centric coordinates. These models are intrinsically invariant to translation and rotation between scene elements, are best-performing on public leaderboards, but scale quadratically with the number of agents and scene elements. Scene-centric models use a fixed coordinate system to process all agents. This gives them the advantage of sharing representations among all agents, offering efficient amortized inference computation which scales linearly with the number of agents. However, these models have to learn invariance to translation and rotation between scene elements, and typically underperform agent-centric models. In this work, we develop knowledge distillation techniques between probabilistic motion forecasting models, and apply these techniques to close the gap in performance between agent-centric and scene-centric models. This improves scene-centric model performance by 13.2% on the public Argoverse benchmark, 7.8% on Waymo Open Dataset and up to 9.4% on a large In-House dataset. These improved scene-centric models rank highly in public leaderboards and are up to 15 times more efficient than their agent-centric teacher counterparts in busy scenes.
VN-Transformer: Rotation-Equivariant Attention for Vector Neurons
Jun 08, 2022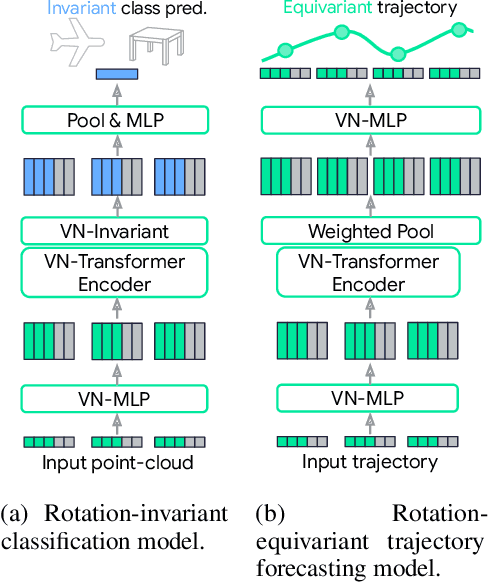
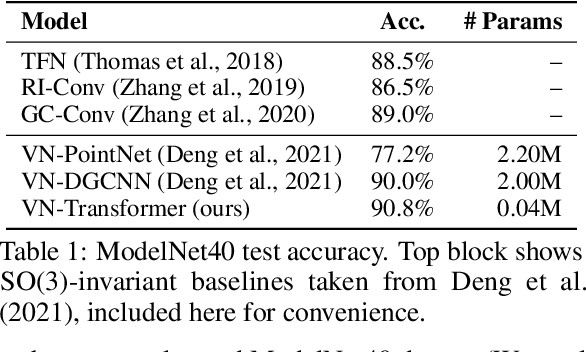

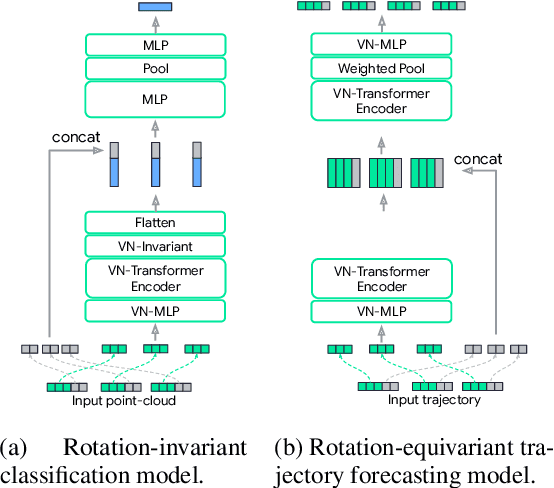
Rotation equivariance is a desirable property in many practical applications such as motion forecasting and 3D perception, where it can offer benefits like sample efficiency, better generalization, and robustness to input perturbations. Vector Neurons (VN) is a recently developed framework offering a simple yet effective approach for deriving rotation-equivariant analogs of standard machine learning operations by extending one-dimensional scalar neurons to three-dimensional "vector neurons." We introduce a novel "VN-Transformer" architecture to address several shortcomings of the current VN models. Our contributions are: $(i)$ we derive a rotation-equivariant attention mechanism which eliminates the need for the heavy feature preprocessing required by the original Vector Neurons models; $(ii)$ we extend the VN framework to support non-spatial attributes, expanding the applicability of these models to real-world datasets; $(iii)$ we derive a rotation-equivariant mechanism for multi-scale reduction of point-cloud resolution, greatly speeding up inference and training; $(iv)$ we show that small tradeoffs in equivariance ($\epsilon$-approximate equivariance) can be used to obtain large improvements in numerical stability and training robustness on accelerated hardware, and we bound the propagation of equivariance violations in our models. Finally, we apply our VN-Transformer to 3D shape classification and motion forecasting with compelling results.
SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer
Oct 15, 2021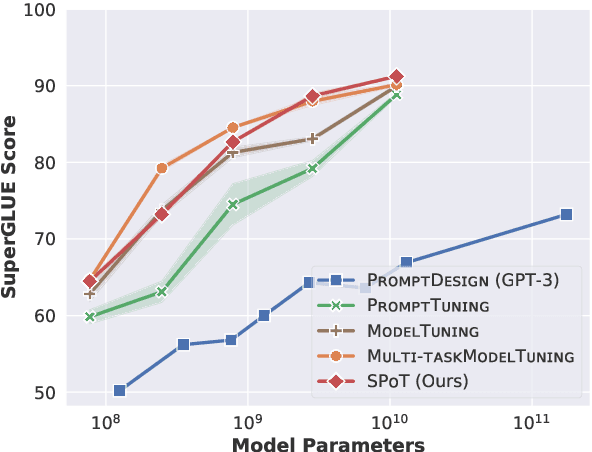
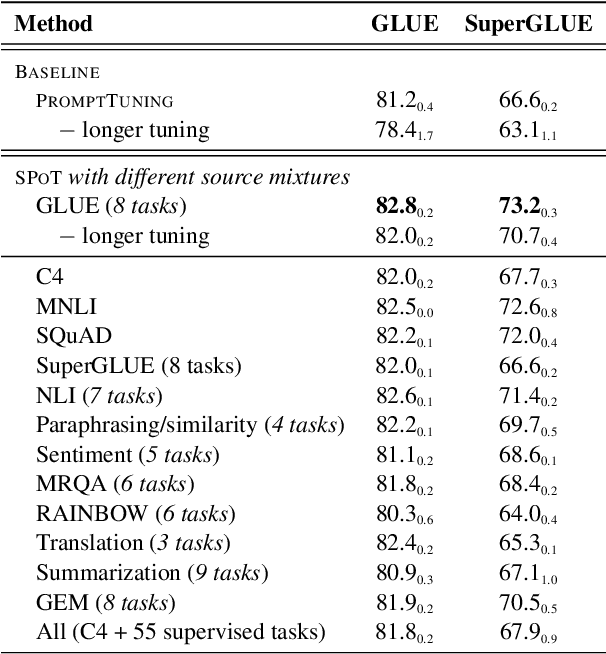
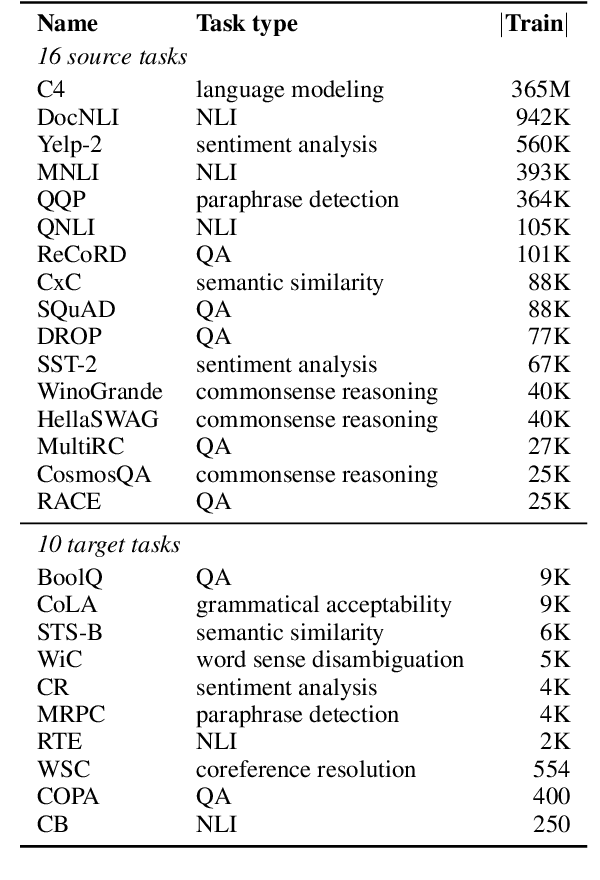
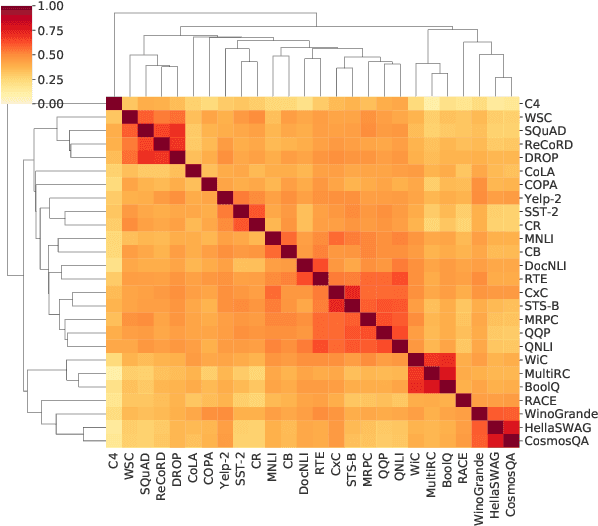
As pre-trained language models have gotten larger, there has been growing interest in parameter-efficient methods to apply these models to downstream tasks. Building on the PromptTuning approach of Lester et al. (2021), which learns task-specific soft prompts to condition a frozen language model to perform downstream tasks, we propose a novel prompt-based transfer learning approach called SPoT: Soft Prompt Transfer. SPoT first learns a prompt on one or more source tasks and then uses it to initialize the prompt for a target task. We show that SPoT significantly boosts the performance of PromptTuning across many tasks. More importantly, SPoT either matches or outperforms ModelTuning, which fine-tunes the entire model on each individual task, across all model sizes while being more parameter-efficient (up to 27,000x fewer task-specific parameters). We further conduct a large-scale study on task transferability with 26 NLP tasks and 160 combinations of source-target tasks, and demonstrate that tasks can often benefit each other via prompt transfer. Finally, we propose a simple yet efficient retrieval approach that interprets task prompts as task embeddings to identify the similarity between tasks and predict the most transferable source tasks for a given novel target task.