 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoST: Multi-modality Scene Tokenization for Motion Prediction
Apr 30, 2024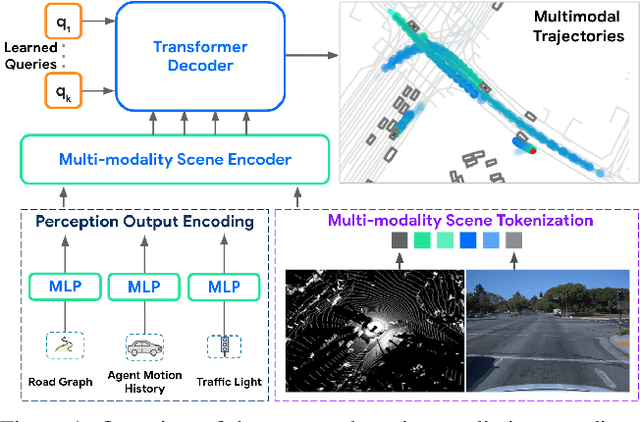

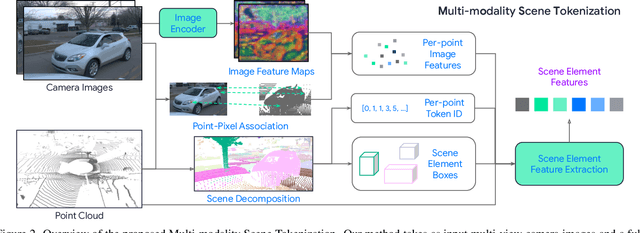
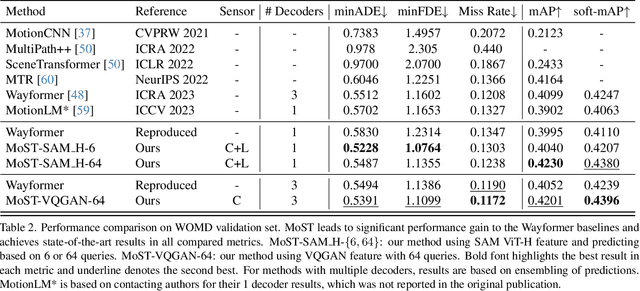
Many existing motion prediction approaches rely on symbolic perception outputs to generate agent trajectories, such as bounding boxes, road graph information and traffic lights. This symbolic representation is a high-level abstraction of the real world, which may render the motion prediction model vulnerable to perception errors (e.g., failures in detecting open-vocabulary obstacles) while missing salient information from the scene context (e.g., poor road conditions). An alternative paradigm is end-to-end learning from raw sensors. However, this approach suffers from the lack of interpretability and requires significantly more training resources. In this work, we propose tokenizing the visual world into a compact set of scene elements and then leveraging pre-trained image foundation models and LiDAR neural networks to encode all the scene elements in an open-vocabulary manner. The image foundation model enables our scene tokens to encode the general knowledge of the open world while the LiDAR neural network encodes geometry information. Our proposed representation can efficiently encode the multi-frame multi-modality observations with a few hundred tokens and is compatible with most transformer-based architectures. To evaluate our method, we have augmented Waymo Open Motion Dataset with camera embeddings. Experiments over Waymo Open Motion Dataset show that our approach leads to significant performance improvements over the state-of-the-art.
WOMD-LiDAR: Raw Sensor Dataset Benchmark for Motion Forecasting
Apr 07, 2023



Widely adopted motion forecasting datasets substitute the observed sensory inputs with higher-level abstractions such as 3D boxes and polylines. These sparse shapes are inferred through annotating the original scenes with perception systems' predictions. Such intermediate representations tie the quality of the motion forecasting models to the performance of computer vision models. Moreover, the human-designed explicit interfaces between perception and motion forecasting typically pass only a subset of the semantic information present in the original sensory input. To study the effect of these modular approaches, design new paradigms that mitigate these limitations, and accelerate the development of end-to-end motion forecasting models, we augment the Waymo Open Motion Dataset (WOMD) with large-scale, high-quality, diverse LiDAR data for the motion forecasting task. The new augmented dataset WOMD-LiDAR consists of over 100,000 scenes that each spans 20 seconds, consisting of well-synchronized and calibrated high quality LiDAR point clouds captured across a range of urban and suburban geographies (https://waymo.com/open/data/motion/). Compared to Waymo Open Dataset (WOD), WOMD-LiDAR dataset contains 100x more scenes. Furthermore, we integrate the LiDAR data into the motion forecasting model training and provide a strong baseline. Experiments show that the LiDAR data brings improvement in the motion forecasting task. We hope that WOMD-LiDAR will provide new opportunities for boosting end-to-end motion forecasting models.
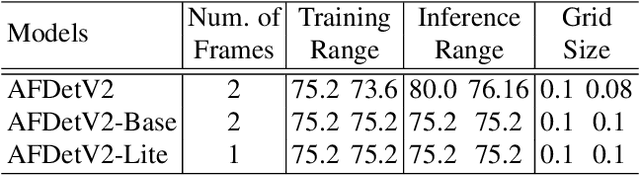
AFDetV2: Rethinking the Necessity of the Second Stage for Object Detection from Point Clouds
Dec 16, 2021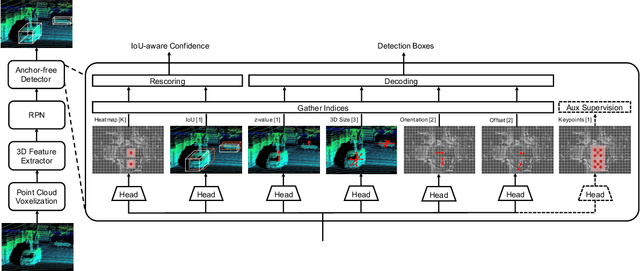

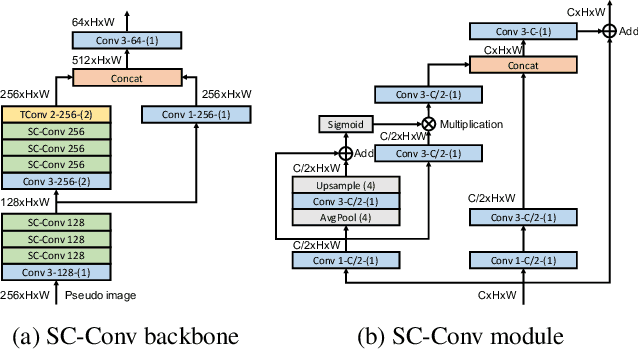
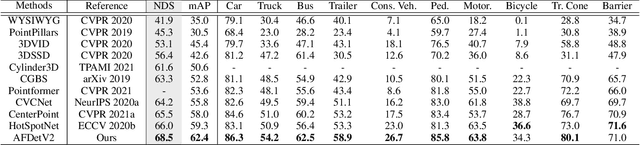
There have been two streams in the 3D detection from point clouds: single-stage methods and two-stage methods. While the former is more computationally efficient, the latter usually provides better detection accuracy. By carefully examining the two-stage approaches, we have found that if appropriately designed, the first stage can produce accurate box regression. In this scenario, the second stage mainly rescores the boxes such that the boxes with better localization get selected. From this observation, we have devised a single-stage anchor-free network that can fulfill these requirements. This network, named AFDetV2, extends the previous work by incorporating a self-calibrated convolution block in the backbone, a keypoint auxiliary supervision, and an IoU prediction branch in the multi-task head. As a result, the detection accuracy is drastically boosted in the single-stage. To evaluate our approach, we have conducted extensive experiments on the Waymo Open Dataset and the nuScenes Dataset. We have observed that our AFDetV2 achieves the state-of-the-art results on these two datasets, superior to all the prior arts, including both the single-stage and the two-stage se3D detectors. AFDetV2 won the 1st place in the Real-Time 3D Detection of the Waymo Open Dataset Challenge 2021. In addition, a variant of our model AFDetV2-Base was entitled the "Most Efficient Model" by the Challenge Sponsor, showing a superior computational efficiency. To demonstrate the generality of this single-stage method, we have also applied it to the first stage of the two-stage networks. Without exception, the results show that with the strengthened backbone and the rescoring approach, the second stage refinement is no longer needed.
Real-Time Anchor-Free Single-Stage 3D Detection with IoU-Awareness
Aug 03, 2021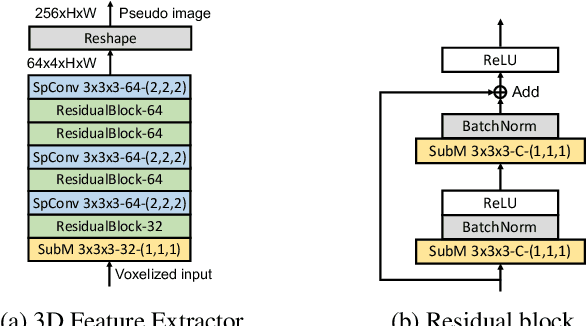
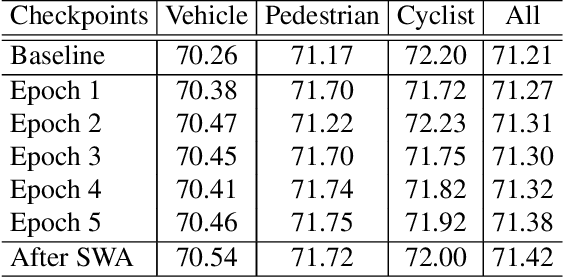
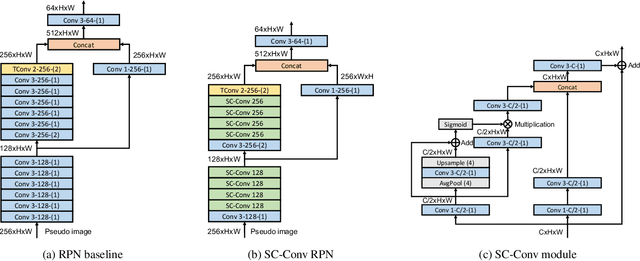
In this report, we introduce our winning solution to the Real-time 3D Detection and also the "Most Efficient Model" in the Waymo Open Dataset Challenges at CVPR 2021. Extended from our last year's award-winning model AFDet, we have made a handful of modifications to the base model, to improve the accuracy and at the same time to greatly reduce the latency. The modified model, named as AFDetV2, is featured with a lite 3D Feature Extractor, an improved RPN with extended receptive field and an added sub-head that produces an IoU-aware confidence score. These model enhancements, together with enriched data augmentation, stochastic weights averaging, and a GPU-based implementation of voxelization, lead to a winning accuracy of 73.12 mAPH/L2 for our AFDetV2 with a latency of 60.06 ms, and an accuracy of 72.57 mAPH/L2 for our AFDetV2-base, entitled as the "Most Efficient Model" by the challenge sponsor, with a winning latency of 55.86 ms.
AFDet: Anchor Free One Stage 3D Object Detection
Jun 30, 2020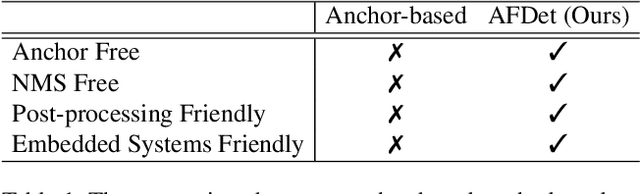
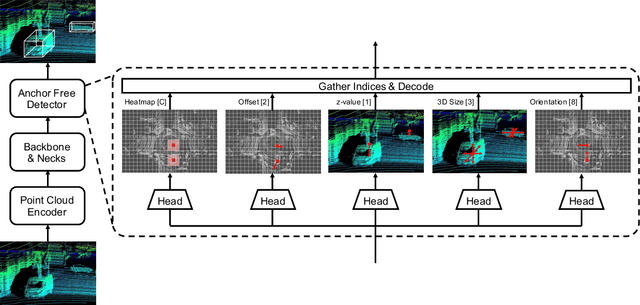
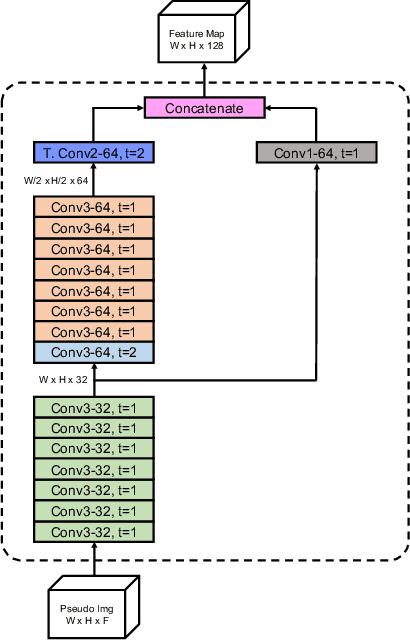
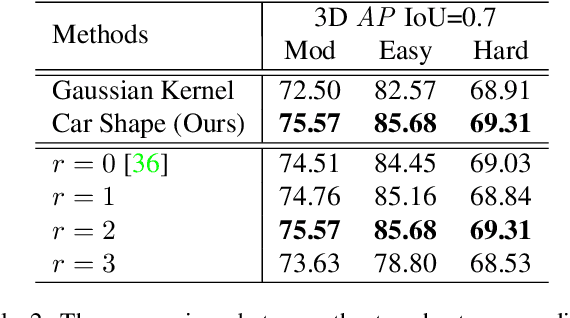
High-efficiency point cloud 3D object detection operated on embedded systems is important for many robotics applications including autonomous driving. Most previous works try to solve it using anchor-based detection methods which come with two drawbacks: post-processing is relatively complex and computationally expensive; tuning anchor parameters is tricky. We are the first to address these drawbacks with an anchor free and Non-Maximum Suppression free one stage detector called AFDet. The entire AFDet can be processed efficiently on a CNN accelerator or a GPU with the simplified post-processing. Without bells and whistles, our proposed AFDet performs competitively with other one stage anchor-based methods on KITTI validation set and Waymo Open Dataset validation set.
2nd Place Solution for Waymo Open Dataset Challenge -- 2D Object Detection
Jun 28, 2020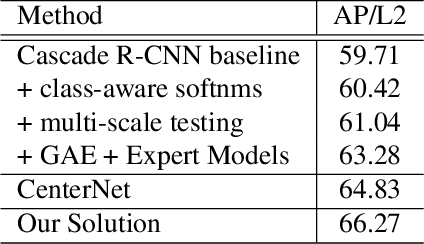
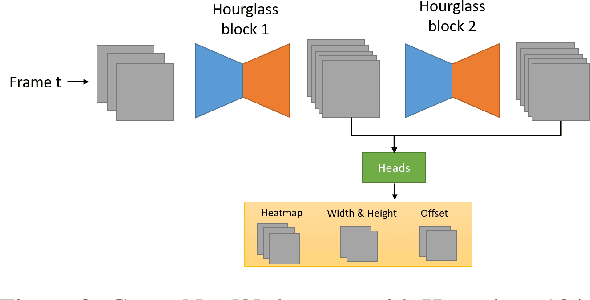
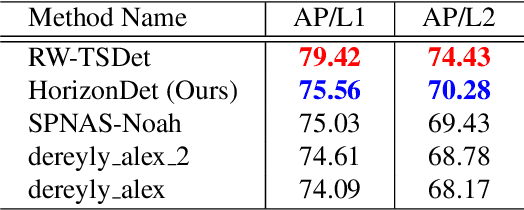
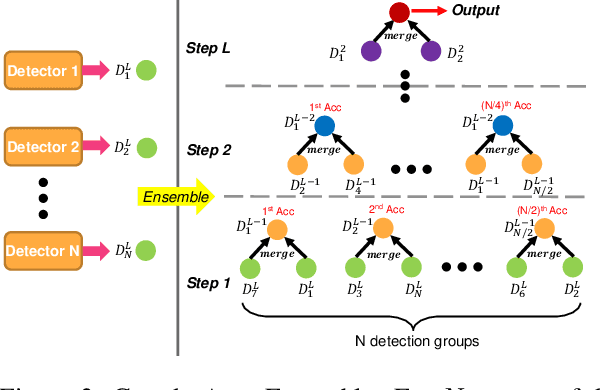
A practical autonomous driving system urges the need to reliably and accurately detect vehicles and persons. In this report, we introduce a state-of-the-art 2D object detection system for autonomous driving scenarios. Specifically, we integrate both popular two-stage detector and one-stage detector with anchor free fashion to yield a robust detection. Furthermore, we train multiple expert models and design a greedy version of the auto ensemble scheme that automatically merges detections from different models. Notably, our overall detection system achieves 70.28 L2 mAP on the Waymo Open Dataset v1.2, ranking the 2nd place in the 2D detection track of the Waymo Open Dataset Challenges.
1st Place Solutions for Waymo Open Dataset Challenges - 2D and 3D Tracking
Jun 28, 2020
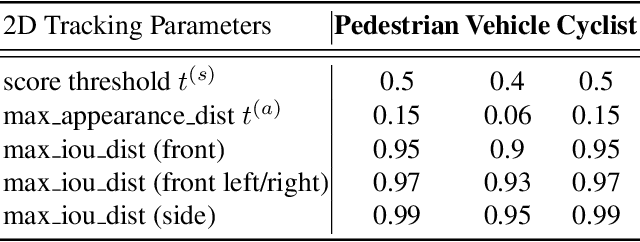
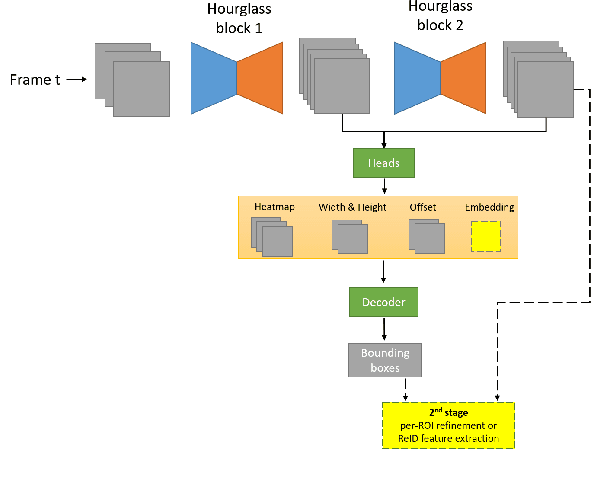
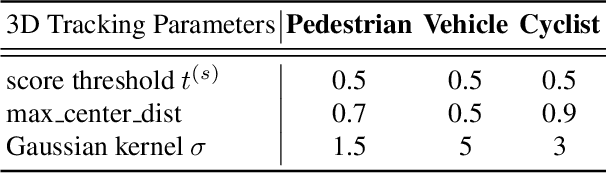
This technical report presents the online and real-time 2D and 3D multi-object tracking (MOT) algorithms that reached the 1st places on both Waymo Open Dataset 2D tracking and 3D tracking challenges. An efficient and pragmatic online tracking-by-detection framework named HorizonMOT is proposed for camera-based 2D tracking in the image space and LiDAR-based 3D tracking in the 3D world space. Within the tracking-by-detection paradigm, our trackers leverage our high-performing detectors used in the 2D/3D detection challenges and achieved 45.13% 2D MOTA/L2 and 63.45% 3D MOTA/L2 in the 2D/3D tracking challenges.
1st Place Solution for Waymo Open Dataset Challenge - 3D Detection and Domain Adaptation
Jun 28, 2020
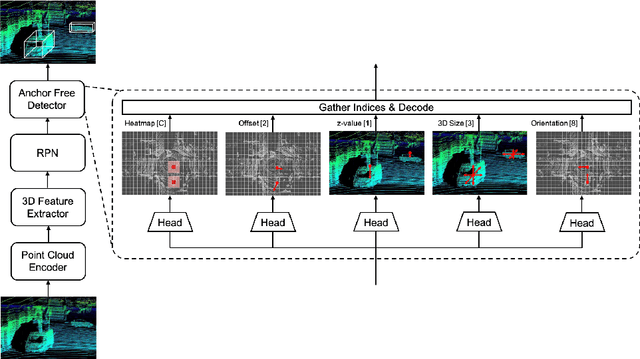
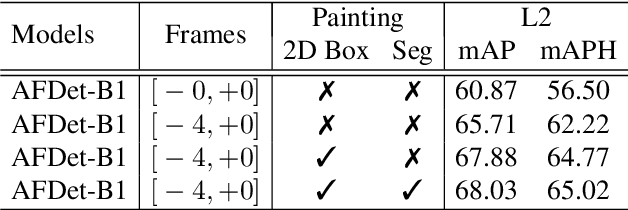
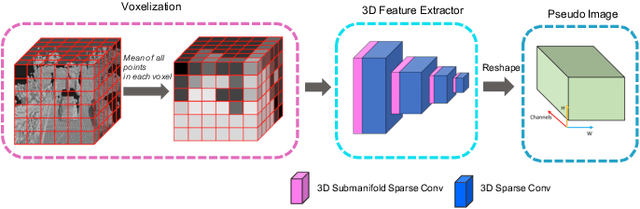
In this technical report, we introduce our winning solution "HorizonLiDAR3D" for the 3D detection track and the domain adaptation track in Waymo Open Dataset Challenge at CVPR 2020. Many existing 3D object detectors include prior-based anchor box design to account for different scales and aspect ratios and classes of objects, which limits its capability of generalization to a different dataset or domain and requires post-processing (e.g. Non-Maximum Suppression (NMS)). We proposed a one-stage, anchor-free and NMS-free 3D point cloud object detector AFDet, using object key-points to encode the 3D attributes, and to learn an end-to-end point cloud object detection without the need of hand-engineering or learning the anchors. AFDet serves as a strong baseline in our winning solution and significant improvements are made over this baseline during the challenges. Specifically, we design stronger networks and enhance the point cloud data using densification and point painting. To leverage camera information, we append/paint additional attributes to each point by projecting them to camera space and gathering image-based perception information. The final detection performance also benefits from model ensemble and Test-Time Augmentation (TTA) in both the 3D detection track and the domain adaptation track. Our solution achieves the 1st place with 77.11% mAPH/L2 and 69.49% mAPH/L2 respectively on the 3D detection track and the domain adaptation track.
MAC: Mining Activity Concepts for Language-based Temporal Localization
Nov 21, 2018
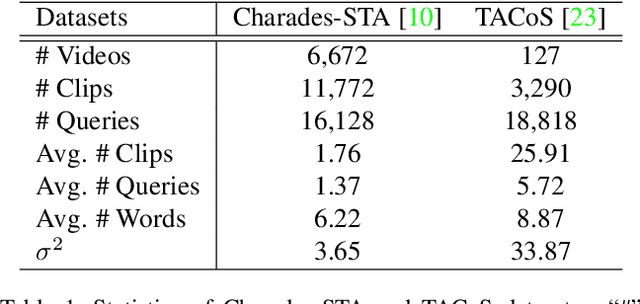

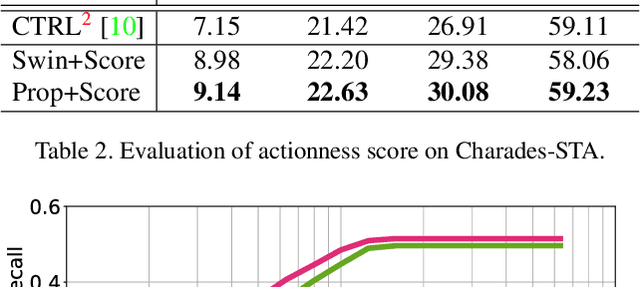
We address the problem of language-based temporal localization in untrimmed videos. Compared to temporal localization with fixed categories, this problem is more challenging as the language-based queries not only have no pre-defined activity list but also may contain complex descriptions. Previous methods address the problem by considering features from video sliding windows and language queries and learning a subspace to encode their correlation, which ignore rich semantic cues about activities in videos and queries. We propose to mine activity concepts from both video and language modalities by applying the actionness score enhanced Activity Concepts based Localizer (ACL). Specifically, the novel ACL encodes the semantic concepts from verb-obj pairs in language queries and leverages activity classifiers' prediction scores to encode visual concepts. Besides, ACL also has the capability to regress sliding windows as localization results. Experiments show that ACL significantly outperforms state-of-the-arts under the widely used metric, with more than 5% increase on both Charades-STA and TACoS datasets.
Motion-Appearance Co-Memory Networks for Video Question Answering
Mar 29, 2018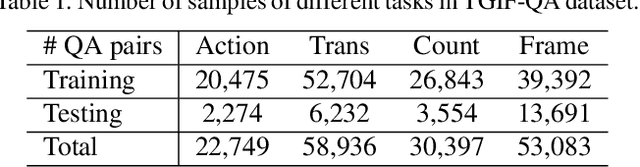

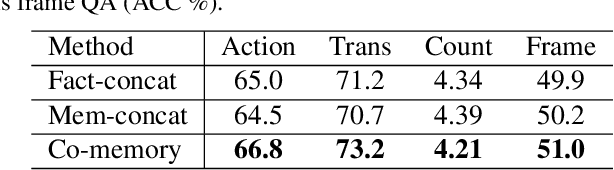

Video Question Answering (QA) is an important task in understanding video temporal structure. We observe that there are three unique attributes of video QA compared with image QA: (1) it deals with long sequences of images containing richer information not only in quantity but also in variety; (2) motion and appearance information are usually correlated with each other and able to provide useful attention cues to the other; (3) different questions require different number of frames to infer the answer. Based these observations, we propose a motion-appearance comemory network for video QA. Our networks are built on concepts from Dynamic Memory Network (DMN) and introduces new mechanisms for video QA. Specifically, there are three salient aspects: (1) a co-memory attention mechanism that utilizes cues from both motion and appearance to generate attention; (2) a temporal conv-deconv network to generate multi-level contextual facts; (3) a dynamic fact ensemble method to construct temporal representation dynamically for different questions. We evaluate our method on TGIF-QA dataset, and the results outperform state-of-the-art significantly on all four tasks of TGIF-QA.